A Deep Dive Into Entity Framework Performance When Using “Contains”
Entity Framework is a great tool, but in some cases its performance is slow. One such case arises when complex queries use “Contains.”
Join Toptal .NET Developer Anton Shkuratov in exploring how performance issues can be mitigated and finding the best approach to this type of complex queries.
Entity Framework is a great tool, but in some cases its performance is slow. One such case arises when complex queries use “Contains.”
Join Toptal .NET Developer Anton Shkuratov in exploring how performance issues can be mitigated and finding the best approach to this type of complex queries.

Anton is a software developer and technical consultant with 10+ years of experience in desktop-distributed applications.
Expertise
During my everyday work, I use Entity Framework. It is very convenient, but in some cases, its performance is slow. Despite there being lots of good articles on EF performance improvements, and some very good and useful advice is given (e.g., avoid complex queries, parameters in Skip and Take, use views, select needed fields only, etc.), not that much can really be done when you need to use complex Contains on two or more fields—in other words, when you join data to a memory list.
Problem
Let’s check the following example:
var localData = GetDataFromApiOrUser();
var query = from p in context.Prices
join s in context.Securities on
p.SecurityId equals s.SecurityId
join t in localData on
new { s.Ticker, p.TradedOn, p.PriceSourceId } equals
new { t.Ticker, t.TradedOn, t.PriceSourceId }
select p;
var result = query.ToList();
The code above doesn’t work in EF 6 at all, and while it does work in EF Core, the join is actually done locally—since I have ten million records in my database, all of them get downloaded and all the memory gets consumed. This is not a bug in EF. It is expected. However, wouldn’t it be fantastic if there was something to solve this? In this article, I’m going to do some experiments with a different approach to work around this performance bottleneck.
Solution
I’m going to try different ways to achieve this starting from the most simple to more advanced. On each step, I will provide code and metrics, such as time taken and memory usage. Note that I will interrupt the benchmarking program run if it works longer than ten minutes.
Code for the benchmarking program is located in the following repository. It uses C#, .NET Core, EF Core, and PostgreSQL. I used a machine with Intel Core i5, 8 GB RAM, and an SSD.
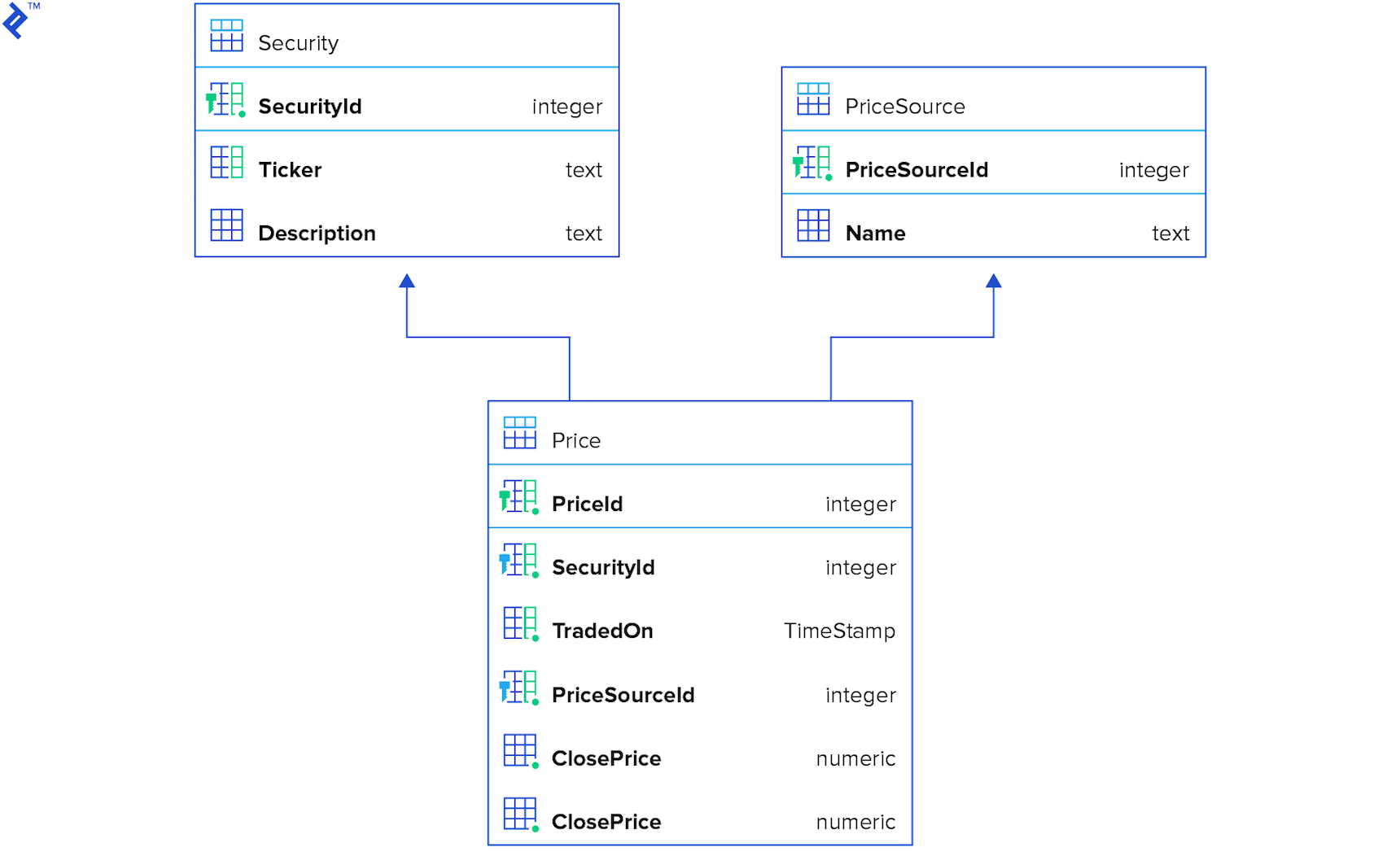
The DB schema for testing looks like this:
Option 1. Simple and Naive
Let’s try something simple, just to get started.
var result = new List<Price>();
using (var context = CreateContext())
{
foreach (var testElement in TestData)
{
result.AddRange(context.Prices.Where(
x => x.Security.Ticker == testElement.Ticker &&
x.TradedOn == testElement.TradedOn &&
x.PriceSourceId == testElement.PriceSourceId));
}
}
The algorithm is simple: For each element in the test data, find a proper element in the database and add it to the result collection. This code has just one advantage: It is very easy to implement. Also, it’s readable and maintainable. Its obvious drawback is that it is the slowest one. Even though all three columns are indexed, the overhead of network communication still creates a performance bottleneck. Here are the metrics:
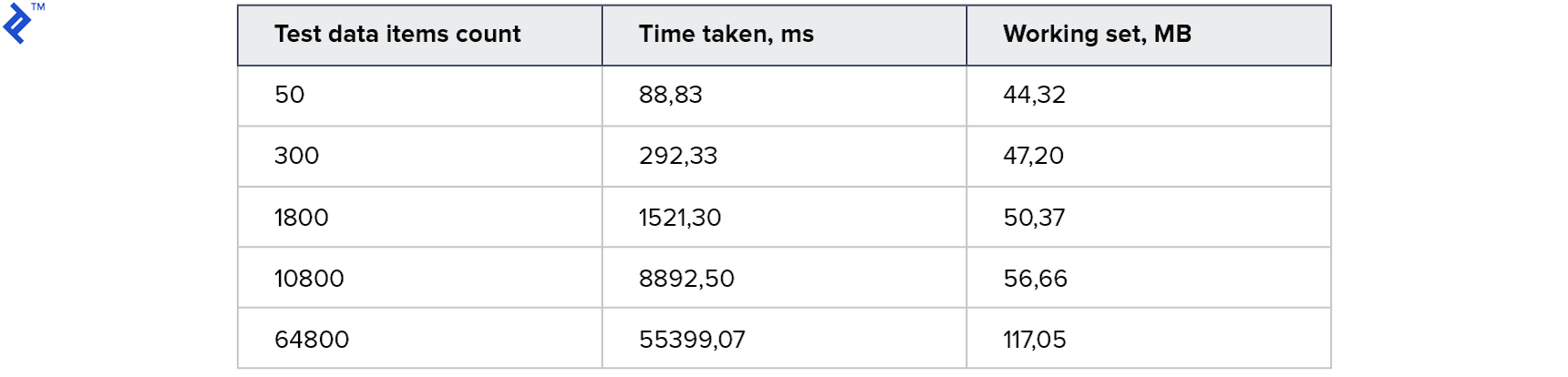
So, for a large volume, it takes approximately one minute. Memory consumption seems to be reasonable.
Option 2. Naive with Parallel
Now let’s try to add parallelism to the code. The core idea here is that hitting the database in parallel threads can improve the overall performance.
var result = new ConcurrentBag<Price>();
var partitioner = Partitioner.Create(0, TestData.Count);
Parallel.ForEach(partitioner, range =>
{
var subList = TestData.Skip(range.Item1)
.Take(range.Item2 - range.Item1)
.ToList();
using (var context = CreateContext())
{
foreach (var testElement in subList)
{
var query = context.Prices.Where(
x => x.Security.Ticker == testElement.Ticker &&
x.TradedOn == testElement.TradedOn &&
x.PriceSourceId == testElement.PriceSourceId);
foreach (var el in query)
{
result.Add(el);
}
}
}
});
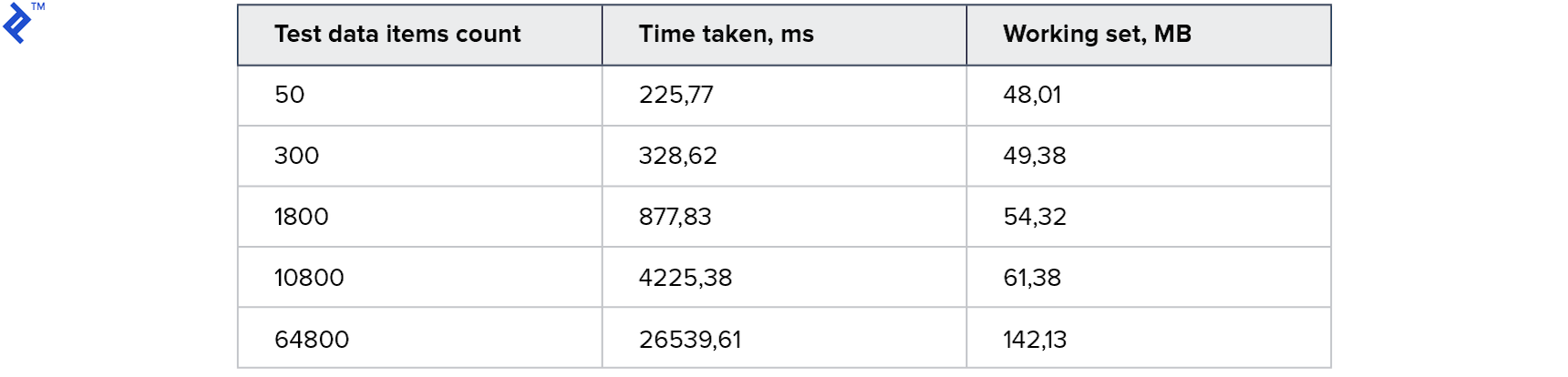
It is interesting that, for smaller test data sets, this approach works slower than the first solution, but for bigger samples, it is faster (approx. 2 times in this instance). Memory consumption changes a bit, but not significantly.
Option 3. Multiple Contains
Let’s try another approach:
- Prepare 3 collections of unique values of Ticker, PriceSourceId, and Date.
- Perform the query with one run filtering by using 3 Contains.
- Recheck locally (see below).
var result = new List<Price>();
using (var context = CreateContext())
{
var tickers = TestData.Select(x => x.Ticker).Distinct().ToList();
var dates = TestData.Select(x => x.TradedOn).Distinct().ToList();
var ps = TestData.Select(x => x.PriceSourceId)
.Distinct().ToList();
var data = context.Prices
.Where(x => tickers.Contains(x.Security.Ticker) &&
dates.Contains(x.TradedOn) &&
ps.Contains(x.PriceSourceId))
.Select(x => new {
x.PriceSourceId,
Price = x,
Ticker = x.Security.Ticker,
})
.ToList();
var lookup = data.ToLookup(x =>
$"{x.Ticker}, {x.Price.TradedOn}, {x.PriceSourceId}");
foreach (var el in TestData)
{
var key = $"{el.Ticker}, {el.TradedOn}, {el.PriceSourceId}";
result.AddRange(lookup[key].Select(x => x.Price));
}
}
This approach is problematic. Execution time is very data dependent. It may retrieve just the required records (in which case it will be very fast), but it might return many more (maybe even 100 times more).
Let’s consider the following test data:
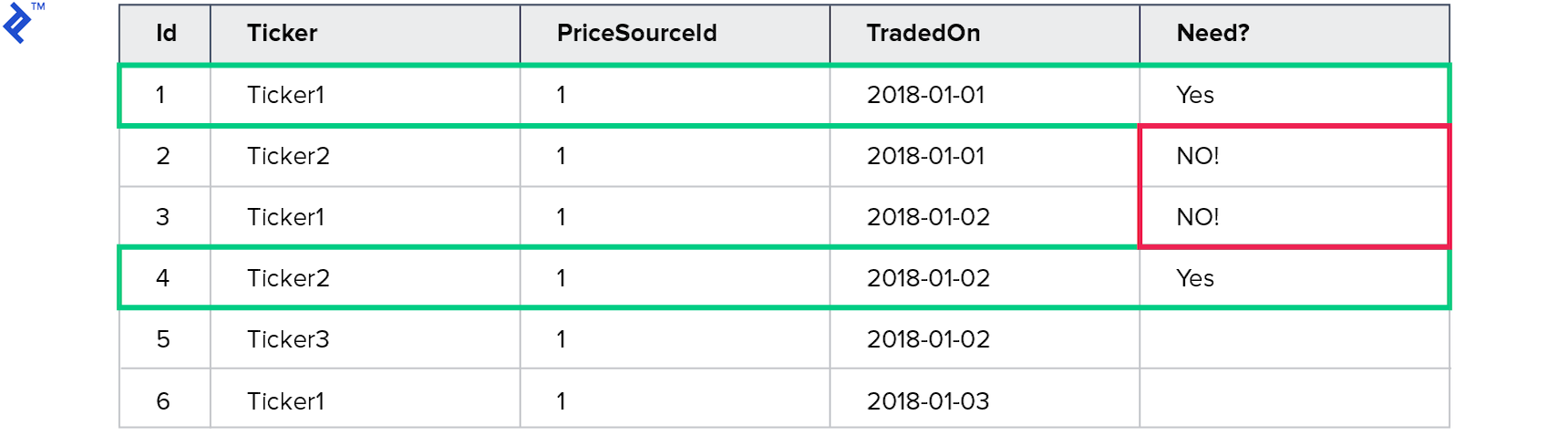
Here I query the prices for Ticker1 traded on 2018-01-01 and for Ticker2 traded on 2018-01-02. However, four records will actually be returned.
The unique values for Ticker are Ticker1 and Ticker2. The unique values for TradedOn are 2018-01-01 and 2018-01-02.
So, four records match this expression.
That’s why a local recheck is needed and why this approach is dangerous. The metrics are as follows:
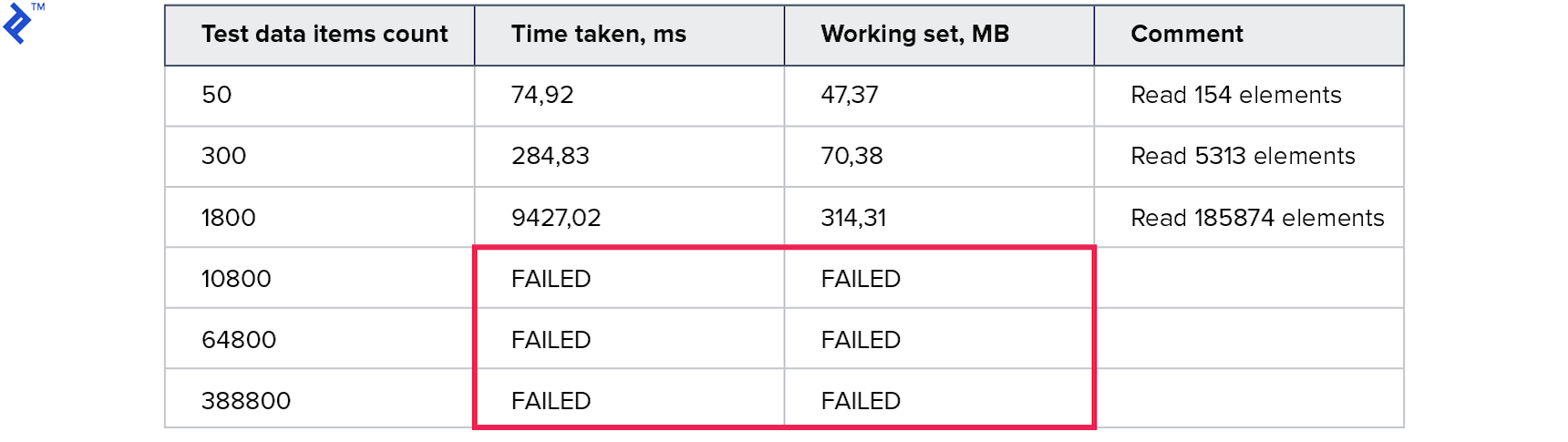
Awful memory consumption! Tests with big volumes failed due to a timeout of 10 minutes.
Option 4. Predicate Builder
Let’s change the paradigm: Let’s build a good old Expression for each test data set.
var result = new List<Price>();
using (var context = CreateContext())
{
var baseQuery = from p in context.Prices
join s in context.Securities on
p.SecurityId equals s.SecurityId
select new TestData()
{
Ticker = s.Ticker,
TradedOn = p.TradedOn,
PriceSourceId = p.PriceSourceId,
PriceObject = p
};
var tradedOnProperty = typeof(TestData).GetProperty("TradedOn");
var priceSourceIdProperty =
typeof(TestData).GetProperty("PriceSourceId");
var tickerProperty = typeof(TestData).GetProperty("Ticker");
var paramExpression = Expression.Parameter(typeof(TestData));
Expression wholeClause = null;
foreach (var td in TestData)
{
var elementClause =
Expression.AndAlso(
Expression.Equal(
Expression.MakeMemberAccess(
paramExpression, tradedOnProperty),
Expression.Constant(td.TradedOn)
),
Expression.AndAlso(
Expression.Equal(
Expression.MakeMemberAccess(
paramExpression, priceSourceIdProperty),
Expression.Constant(td.PriceSourceId)
),
Expression.Equal(
Expression.MakeMemberAccess(
paramExpression, tickerProperty),
Expression.Constant(td.Ticker))
));
if (wholeClause == null)
wholeClause = elementClause;
else
wholeClause = Expression.OrElse(wholeClause, elementClause);
}
var query = baseQuery.Where(
(Expression<Func<TestData, bool>>)Expression.Lambda(
wholeClause, paramExpression)).Select(x => x.PriceObject);
result.AddRange(query);
}
The resulting code is pretty complex. Building expressions is not the easiest thing and involves reflection (which, itself, is not that fast). But it helps us to build a single query using lots of … (.. AND .. AND ..) OR (.. AND .. AND ..) OR (.. AND .. AND ..) .... These are the results:
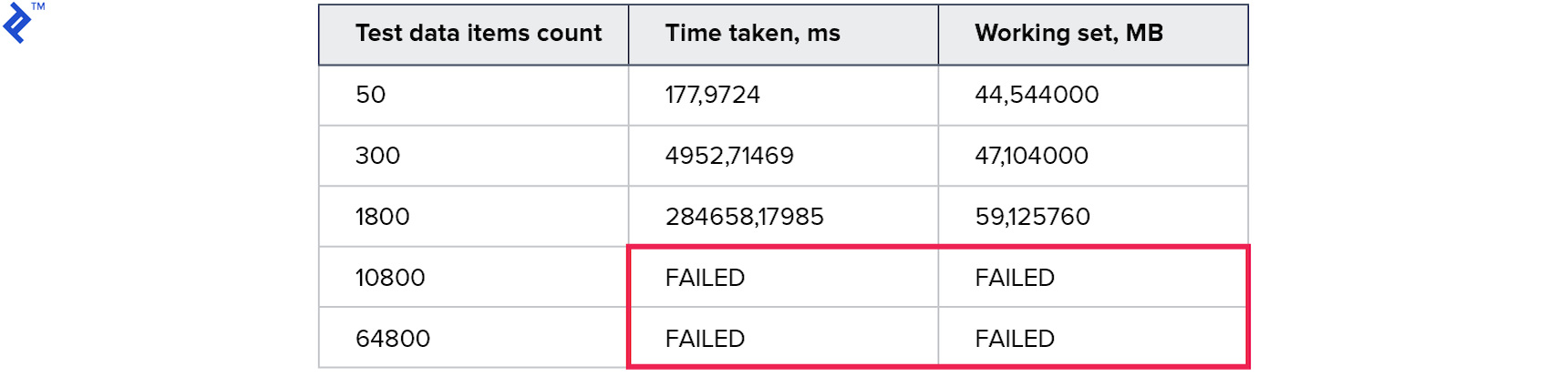
Even worse than either of the previous approaches.
Option 5. Shared Query Data Table
Let’s try one more approach:
I added a new table to the database that will hold query data. For each query I can now:
- Start a transaction (if not yet started)
- Upload query data to that table (temporary)
- Perform a query
- Roll back a transaction—to delete uploaded data
var result = new List<Price>();
using (var context = CreateContext())
{
context.Database.BeginTransaction();
var reducedData = TestData.Select(x => new SharedQueryModel()
{
PriceSourceId = x.PriceSourceId,
Ticker = x.Ticker,
TradedOn = x.TradedOn
}).ToList();
// Here query data is stored to shared table
context.QueryDataShared.AddRange(reducedData);
context.SaveChanges();
var query = from p in context.Prices
join s in context.Securities on
p.SecurityId equals s.SecurityId
join t in context.QueryDataShared on
new { s.Ticker, p.TradedOn, p.PriceSourceId } equals
new { t.Ticker, t.TradedOn, t.PriceSourceId }
select p;
result.AddRange(query);
context.Database.RollbackTransaction();
}
Metrics first:
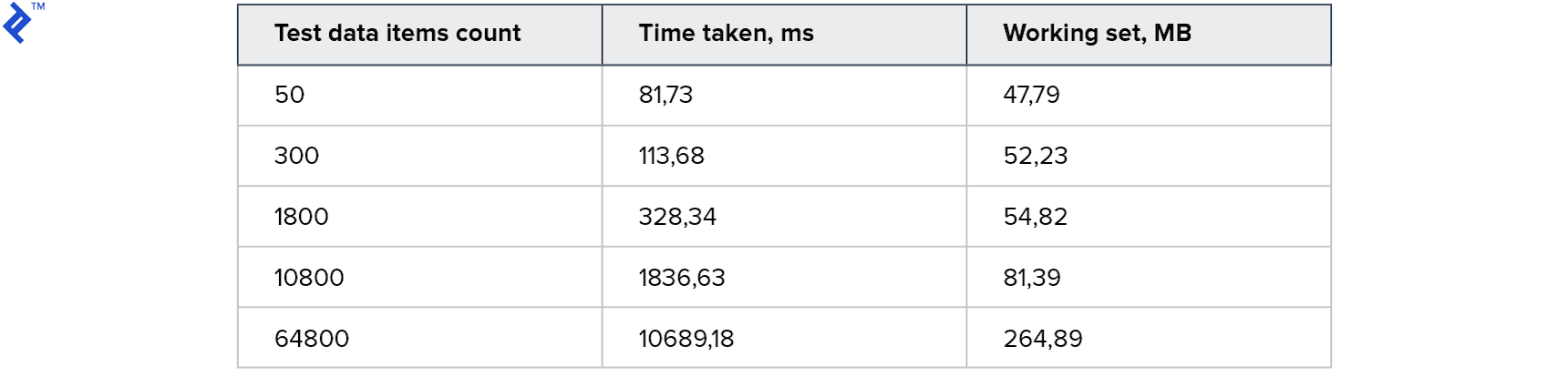
The result is very good. Very fast. Memory consumption is also good. But the drawbacks are:
- You have to create an extra table in the database to perform just one type of query,
- You have to start a transaction (which consumes DBMS resources anyways), and
- You have to write something to the database (in a READ operation!)—and basically, this will not work if you use something like read replica.
But apart from that, this approach is nice—fast and readable. And a query plan is cached in this case!
Option 6. MemoryJoin Extension
Here I’m going to use a NuGet package called EntityFrameworkCore.MemoryJoin. Despite the fact that its name has the word Core in it, it also supports EF 6. It is called MemoryJoin, but in fact, it sends the specified query data as VALUES to the server and all work is done on the SQL server.
Let’s check the code.
var result = new List<Price>();
using (var context = CreateContext())
{
// better to select needed properties only, for better performance
var reducedData = TestData.Select(x => new {
x.Ticker,
x.TradedOn,
x.PriceSourceId
}).ToList();
var queryable = context.FromLocalList(reducedData);
var query = from p in context.Prices
join s in context.Securities on
p.SecurityId equals s.SecurityId
join t in queryable on
new { s.Ticker, p.TradedOn, p.PriceSourceId } equals
new { t.Ticker, t.TradedOn, t.PriceSourceId }
select p;
result.AddRange(query);
}
Metrics:

This looks awesome. Three times faster than the previous approach—that makes it the fastest yet. 3.5 seconds for 64K records! The code is simple and understandable. This works with read-only replicas. Let’s check the query generated for three elements:
SELECT "p"."PriceId",
"p"."ClosePrice",
"p"."OpenPrice",
"p"."PriceSourceId",
"p"."SecurityId",
"p"."TradedOn",
"t"."Ticker",
"t"."TradedOn",
"t"."PriceSourceId"
FROM "Price" AS "p"
INNER JOIN "Security" AS "s" ON "p"."SecurityId" = "s"."SecurityId"
INNER JOIN
( SELECT "x"."string1" AS "Ticker",
"x"."date1" AS "TradedOn",
CAST("x"."long1" AS int4) AS "PriceSourceId"
FROM
( SELECT *
FROM (
VALUES (1, @__gen_q_p0, @__gen_q_p1, @__gen_q_p2),
(2, @__gen_q_p3, @__gen_q_p4, @__gen_q_p5),
(3, @__gen_q_p6, @__gen_q_p7, @__gen_q_p8)
) AS __gen_query_data__ (id, string1, date1, long1)
) AS "x"
) AS "t" ON (("s"."Ticker" = "t"."Ticker")
AND ("p"."PriceSourceId" = "t"."PriceSourceId")
As you can see, this time actual values are passed from memory to the SQL server in the VALUES construction. And this does the trick: The SQL server managed to perform a fast join operation and use the indexes correctly.
However, there are some drawbacks (you may read more on my blog):
- You need to add an extra DbSet to your model (however no need to create it in the DB)
- The extension doesn’t support model classes with many properties: three string properties, three date properties, three guide properties, three float/double properties, and three int/byte/long/decimal properties. This is more than enough in 90% of the cases, I guess. However, if it’s not, you can create a custom class and use that. So, HINT: you need to pass the actual values in a query, otherwise resources are wasted.
Conclusion
Among the things I’ve tested here, I’d definitely go for MemoryJoin. Someone else might object that the drawbacks are insurmountable, and since not all of them can be resolved at the moment, we should abstain from using the extension. Well, for me, it’s like saying that you should not use a knife because you could cut yourself. Optimization was a task not for junior developers but for someone who understands how EF works. To that end, this tool can improve performance dramatically. Who knows? Maybe one day, someone at Microsoft will add some core support for dynamic VALUES.
Finally, Here are a few more diagrams to compare results.
Below is a diagram for time taken to perform an operation. MemoryJoin is the only one which does the job in a reasonable time. Only four approaches can process big volumes: two naive implementations, shared table, and MemoryJoin.
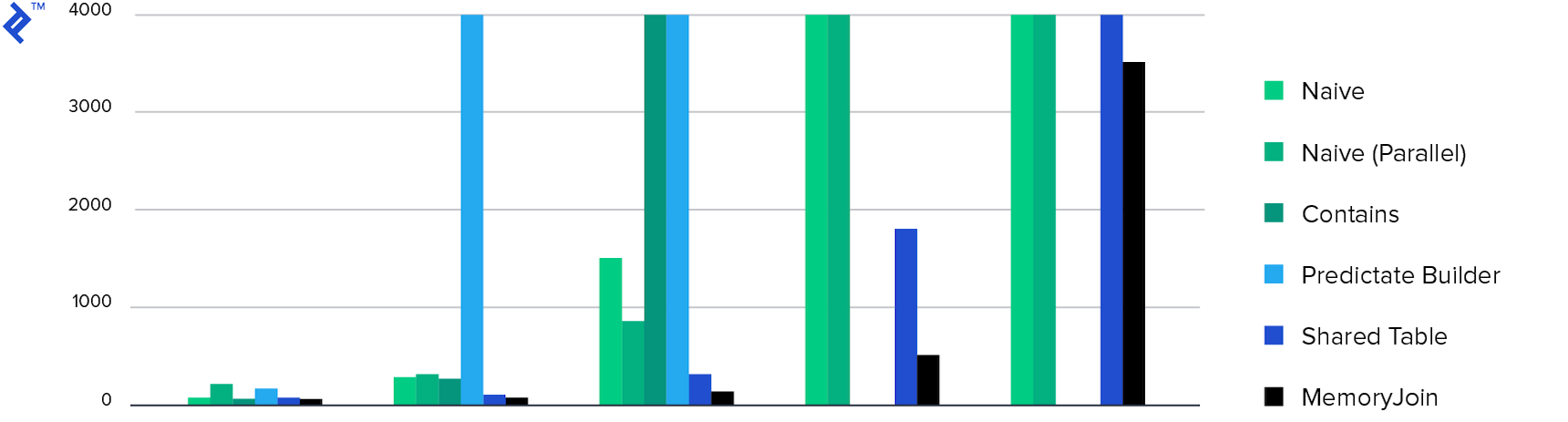
The next diagram is for memory consumption. All approaches demonstrate more or less the same numbers except the one with multiple Contains. This phenomenon was described above.

Understanding the basics
What is DBset in Entity Framework?
DBSet is an abstraction which is literally a collection of objects (usually lazy loaded) stored in a table. Operations done on DBSet are actually performed on the actual database records via SQL queries.
What does Entity Framework do?
Entity Framework is an object relational mapping framework, which provides a standard interface for accessing data stored in relational databases (of different vendors).
What is code first approach in Entity Framework?
The code-first approach means that the developer creates model classes first before the actual DB is created. One of the biggest advantages is storing the database model in source control systems.
Tomsk, Tomsk Oblast, Russia
Member since December 8, 2014
About the author
Anton is a software developer and technical consultant with 10+ years of experience in desktop-distributed applications.