
Software Development
Easy lambdas with Netlify 
Jan Vermeir 03 Sep, 2021





Any company wants to adapt quickly because of new or changed business ideas, or because of changes in the market. Only by adapting quickly, you can stay ahead of the competition. For a company that relies heavily on software built in-house, like Picnic, this means software needs to change rapidly. This is where things get difficult.
In this post, I’ll explain how rapid feedback in the software development process is required to speed up software change, and how executable specifications can reduce this feedback loop. I’ll describe how we apply this methodology at Picnic and what benefits we’re reaping because of it.
Many factors can slow down software change, like a team lacking autonomy, or legacy code, but here I would like to focus on slow feedback. Say that the following is a rough summary of an average software development process:
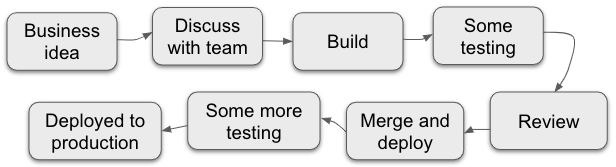
In the software development process, slow feedback is a multi-headed monster because at each of the aforementioned steps, you could get feedback.
A couple of examples:
The later you get feedback, the more time you will have wasted on a change that is not desired. To solve this, we need rapid feedback so that we fail fast and not waste time. This in turn speeds up the development process!
Having observed the effects of slow feedback at Picnic for a while, I found various ways to reduce the feedback loop and speed up software change. One of such ways is to get a shared understanding between a product owner and a team of software engineers of what needs to be built, a technique called Example Mapping can be used. It is a way to collaboratively come up with examples of how the system should behave. These examples can then be turned into executable specifications, which is what I will focus on in this post.
Executable specifications can give you the rapid feedback you need to avoid wasting time on building software you don’t need, or software that does not work.
So why executable?
These specifications are called executable, because they can be executed as automated tests. This means that on the one hand, you have a human-readable specification of what the system – or a particular change within the system – should do. People familiar with the domain, but without specific technical expertise can also understand these specifications. On the other hand, you have a suite of automated tests that a software engineer can run to verify that everything works as expected. It’s living documentation. If the documentation changes, so do your tests.
Because they’re automated tests they dramatically reduce manual testing and the time wasted doing this. And with that also regressions that slip in because you forget to test some feature that was built a year ago. Note that I’m not against manual testing – exploratory testing is still useful for things that are hard to automate or don’t need to be tested often. It’s the boring, repetitive, and time-consuming manual testing that should be automated.
Basically, we want to build the right thing, build it right, and automatically verify that this is the case.
The theory described above may be really nice, but how does this work in practice?
There are various tools to create executable specifications, one of which is Cucumber. A specification in Cucumber looks like this:

Gherkin is the language to write down your specifications, so that Cucumber can execute each line (called a step) as an automated test. You have a set of so-called feature files, each containing a clear description of the feature and several scenarios like the one above, specifying examples that describe the behaviour of the feature.
You may be familiar with the given-when-then structure. The given part is the setup, required to bring the system into a state in which the desired behaviour can be triggered. The when part is this trigger, and the then part verifies that the behaviour is as expected.
Although multiple blog posts could be dedicated on how to write scenarios and what should and should not be in them, the key is that everyone on the team (including the product owner!) understands what they mean. Only then you can avoid misunderstanding of what the intended behaviour should be.
Diving deeper into the technicalities of how to run this specification as an automated test, I’ll describe the technical setup.
At Picnic most teams use Java, so we decided to use Behave as our Cucumber implementation and implement the tests executed by the feature files in Python. I know this sounds strange, but it was a deliberate decision. By using different languages for tests and production code, we force a separation between tests and production code, preventing the test from relying on implementation details. After all, we want to test the behaviour of our system as observed from the outside, not the inner workings! Even if you would use the same language (some teams at Picnic use Python), I would still strongly advise you to keep this separation. What you want to test is your system’s outer APIs, whether that’s a messaging interface, REST, or SOAP.
Speaking of “the system”, what is the scope of it?
At Picnic each team deploys one or more docker containers into a Kubernetes environment, so the easiest way was to make each container the subject under test. However, it is likely you can’t run and test a container on its own, it has dependencies on for example databases, message brokers, and other external services communicating over REST or SOAP. Below is an overview of how we managed to test a container in isolation:
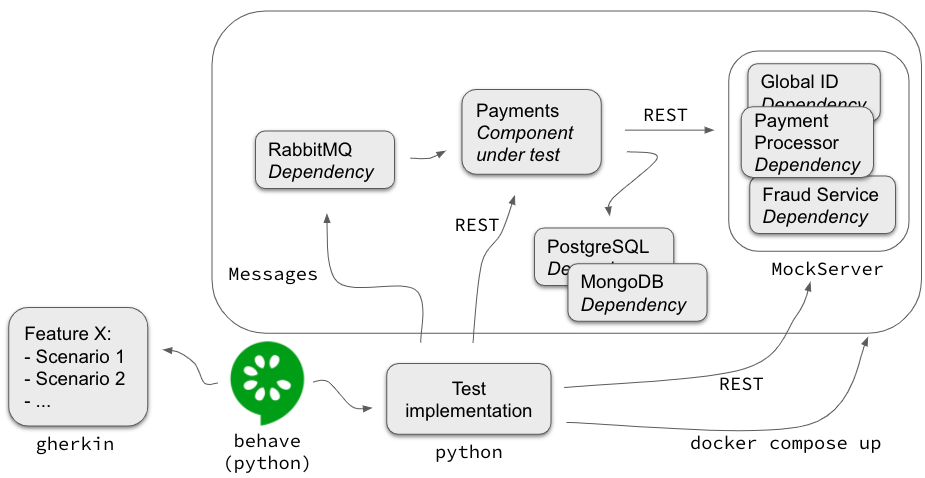
This is the setup for testing the Payments container. The dependencies of Payments are run in containers as well. In the case of RabbitMQ, we run the real thing, it’s just easier than mocking the messaging interface. The same holds for the databases, but more importantly, these hold the state of the system. As you’re observing the system from the outside you don’t actually care how it persists its state, as long as the expected behaviour is observed. Therefore, apart from resetting the state between scenarios, only the Payments container should interact with the databases directly.
For the other dependencies, like the internal Fraud Service or a payment processor, we mock the REST interfaces by using a tool called MockServer. Our test implementation will set up expectations for each scenario (in the “given” section) to make sure the Payments container thinks it’s talking to the real thing. We will also use MockServer to verify that certain interactions did in fact happen. For example, our “Then a collection of 1337 cents is initiated through the Payment Processor” step does this.
As the last piece of the puzzle, our test implementation will run docker compose to start all the containers. Once it’s ready to run the tests, behave will interpret our specifications and execute them.
The nice thing about this setup is that we can run it both locally and on a CI server. Remember: we want to get fast feedback so you want to be able to run those tests while (or even better: before) you’re writing code, not just afterwards. If you’d only be able to run them on CI or after deployment in some test environment, you would still get late feedback and waste time!
By now you might think, sure, this is nice for a new project, where we can start from scratch and do everything perfectly, but it won’t be of much use in my existing project that contains a lot of legacy code. This is not true.
When I started, Picnic was already 5 years down the road, a lot of code had been written, most of it good, some of it not so good, none of which with executable specifications as I described above. Regardless I started creating a proof of concept setup with a single scenario for one team, and just enough extra bits to make that run with docker compose. I also mocked some external dependency to show how this works. I picked a scenario which touched some brittle but crucial code, so that we could immediately reap the benefits.
When the team was convinced of this approach, we hooked up the setup with our CI pipeline. Instead of doing a one-off creating specifications for everything (which I strongly advise against), every time we touched some code or added a new feature, we created a feature file with some scenarios. Slowly but surely we got to a state where all key business functionality was covered by an executable specification. At this point word spread and other teams got interested. Now nearly every team at Picnic is writing these specifications and reducing their feedback cycle.
In this post, I’ve explained that in order to change software quickly, we need rapid feedback. Executable specifications are a way to reduce the feedback cycle in your software development process. By introducing these at Picnic, we now:
All of this decreases the time to change software in an organisation and will keep you ahead of the competition. I hope this will help you adopt executable specifications in your organisation, and reduce the time it takes to change your software!
This article was originally posted on the Picnic blog.
