





Applying domain-specific knowledge to the data preparation phase makes data science and machine learning (ML) projects most meaningful. Without specific use case knowledge, the models will likely fail to deliver accurate predictions.
When we apply business or domain knowledge to the data preparation phase prior to training a model, this is called feature engineering. It is an essential process to deliver predictive models with real business impact. Understanding the value and intricacies of feature engineering can significantly improve the results of your project.
Feature Engineering Process
Feature engineering entails selecting, modifying, or creating new features (also known as variables or attributes) from an existing dataset to improve the performance of predictive models. New features create new columns in our dataset. These features are not just created at random; they are created by having expert knowledge of the business case.
7 Steps to Feature Engineering for Exceptional ML Models
1. Exploratory Data Analysis (EDA): Before diving headfirst into feature engineering, it's imperative to gain a deep understanding of the dataset through exploratory data analysis. EDA involves visualizing data distributions, identifying outliers, assessing correlations, and discerning patterns that can guide subsequent feature engineering steps.
2. Handling Missing Data: Missing data can throw a wrench into the gears of ML models. Imputation techniques such as mean imputation, median imputation, or advanced methods like K-nearest neighbors (KNN) imputation are employed to fill in the gaps and ensure a complete dataset.
3. Encoding Categorical Variables: ML algorithms operate on numerical data, rendering categorical variables incompatible. Encoding categorical variables involves converting categorical data into a numerical format that algorithms can digest. Popular encoding techniques include one-hot encoding, label encoding, and target encoding.
4. Feature Scaling: Features often exhibit varying scales and magnitudes, which can adversely impact the performance of certain ML algorithms. Feature scaling, through methods like standardization or min-max scaling, ensures that all features are uniformly scaled, thereby preventing dominance by features with larger magnitudes.
5. Feature Transformation and Generation: It comes as no surprise that steps 2-4 benefit from business knowledge. This step is where domain knowledge becomes imperative. Transforming features through logarithmic transformations, polynomial features, or interaction terms can uncover complex relationships hidden within the data. Additionally, creating new features derived from domain knowledge or engineering insightful metrics can amplify the predictive power of models.
6. Feature Selection: Not all features are created equal. Feature selection entails analyzing the relationship between each of your features and the target variable whose value you are trying to predict, and eliminating the features that don’t contribute significantly to your predictions. Techniques such as correlation analysis, mutual information, and recursive feature elimination aid in discerning importance.
7. Dimensionality Reduction: Dimensionality reduction is another more algorithmic method of reducing the number of features in your dataset. Techniques such as principal component analysis (PCA) or manifold learning algorithms help distill the essence of the data and reduce any noise, thus streamlining model training and inference.
Benefits of Feature Engineering
While feature engineering takes additional effort to implement, its benefits far outweigh the minimal cost.
Enhanced Model Performance
Feature engineering serves as the basis of model refinement, strengthening predictive accuracy and generalization capabilities. Selecting features that embed specific business knowledge into a model results in superior performance metrics.
Improved Interpretability
Feature engineering empowers analysts to imbue models with interpretability by crafting features that align with domain-specific insights. As a result, stakeholders can grasp the rationale behind model predictions and glean actionable insights with confidence.
Robustness to Noise and Overfitting
By thoughtfully selecting and transforming features, feature engineering fortifies models against the adverse effects of noise and overfitting. Robust features instill models with resilience, enabling models to generalize effectively on unseen data.
Domain Expertise Integration
Feature engineering offers a channel for domain experts to infuse their insights into the modeling process. By crafting features that encapsulate domain-specific knowledge and nuances, models can discern subtle patterns that might elude automated algorithms alone.
Categories of Feature Creation
During the feature creation process it can be helpful to consider the type of feature being created. Features will be created from domain knowledge, generated from patterns within the data, derived through the combination of existing features. We refer to these categories as Domain-Specific, Data-Driven, or Synthetic features.
- Domain-Specific: Creating new features from specific domain knowledge. Features are based on business rules, specific interests, or industry standards.
- Data-Driven: Creating new features by discovering patterns in the data, such as calculating averages, grouping, or interrelated features.
- Synthetic: Creating new features by merging existing features or synthesizing new data points.
Feature Creation Tips
To be effective, a feature must be related to the target in a manner that your model can comprehend. Feature engineering is an iterative process of data prep, model training, performance assessment, and feature improvement. Linear models, for instance, can only grasp linear correlations. Therefore, when utilizing a linear regression model, your aim is to adjust the features to establish a linear relationship with the target.
The fundamental concept here is that any transformation applied to a feature essentially becomes integrated into the model itself. For instance, consider predicting the price of polygonal plots of land based on the length of one side. Directly fitting a linear model to the length yields unsatisfactory outcomes as the relationship is not linear. A better choice would be the calculated area, or with domain knowledge the usable area for commercial interest.
Think back from the objective and goals for your features: When determining which feature engineering techniques to employ, keep in mind the model type that you're choosing to optimize for that model. Also, when creating new features, make sure that they have the potential to be predictive and aren’t just created for the sake of it.
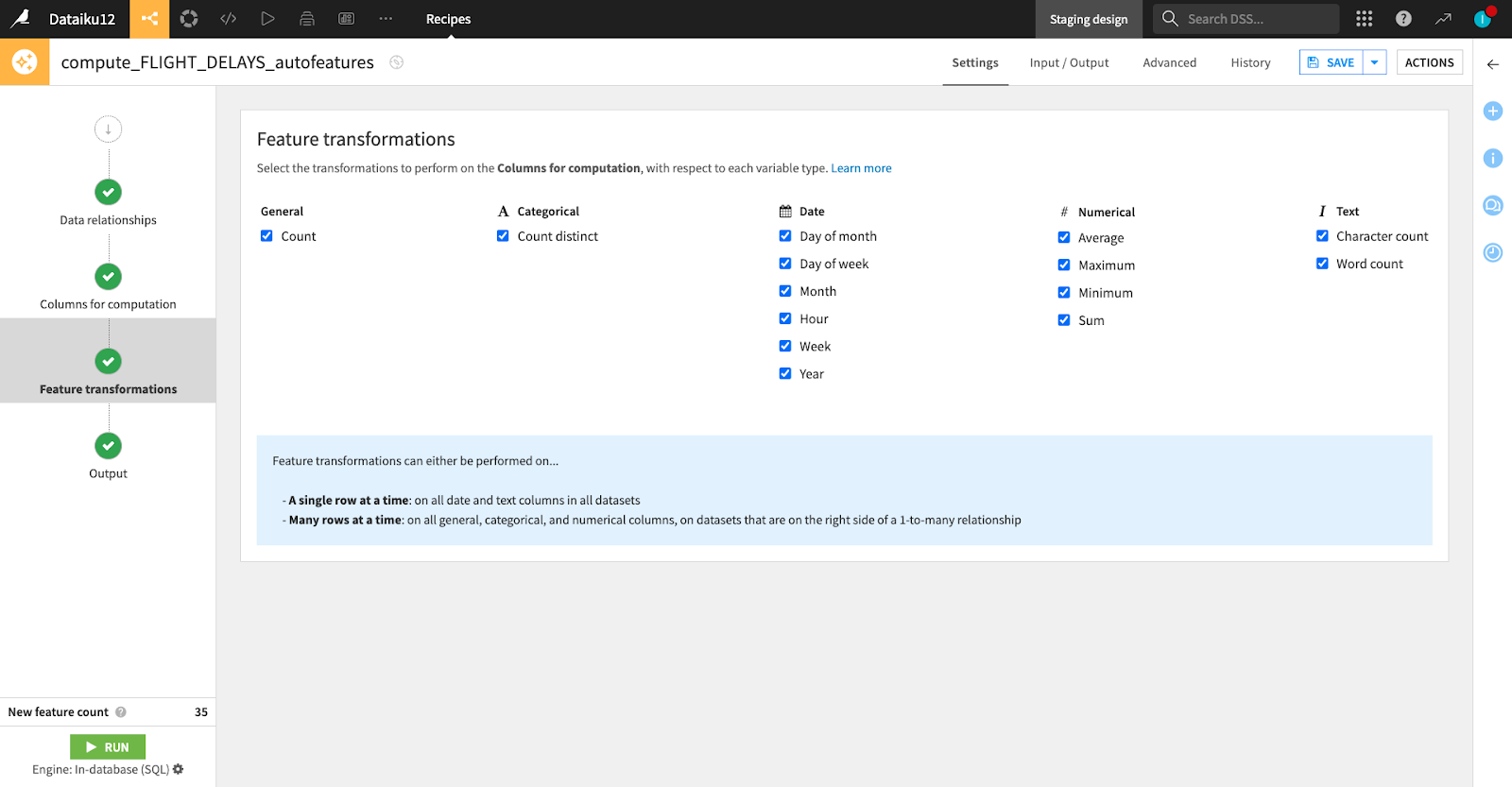
Dataiku's Auto Feature Generation
Dataiku & Feature Engineering
Dataiku has powerful tools to support the feature engineering process. Historically feature engineering has been manual and time-consuming, with users transforming or creating new features using formulas, code, or built-in visual recipes.
With Auto Feature Generation, you can now easily perform feature transformation and feature generation based on relationships between multiple datasets, without needing to write any code. Dataiku also features built-in statistical analysis and visualizations to quickly test out relationships between data, including Principal Component Analysis (PCA).
During model development, Dataiku AutoML accelerates feature pre-processing and handling by automatically filling in missing values and converting non-numeric data into numerical values using well-established encoding techniques.

Dataiku AutoML
Additionally, built-in feature generation can programmatically create new pairwise combinations of features to provide additional inputs to the model, or users may instead choose to apply common feature reduction techniques. Once created, Dataiku documents the settings and stores feature engineering steps in recipes for reuse in scoring and model retraining.
Feature engineering is a critical component for anyone striving for exceptional ML models. By leveraging domain knowledge, refining data transformations, and selecting pertinent features, practitioners can unlock the full potential of their predictive models. From enhancing performance metrics to fostering interpretability and resilience, there are many benefits of effective feature engineering.