





Many new machine learning projects start with a minimal amount of sampled data, if any. Even worse, they tend to fail to take advantage of the “hidden gem” that is unlabeled data by focusing on the obvious, labeled data. A potential solution is semi-supervised learning (SSL), which uses both labeled and unlabeled samples to perform prediction.
This blog post demonstrates how semi-supervised learning improves model performance, especially with small samples of labeled data. We also show that using the confidence of a semi-supervised model to select samples to be pseudo-labeled outperforms a fixed size selection.
Unfortunately, we did not observe any impact from sample weighting pseudo labels or from self-training. Our findings are supported by experiments on textual data (AG News), credit card fraud detection, and geolocation deduplication (Nomao). If you want to start small, this blog post only shows the experiment on the AG News dataset and doesn't go into pseudo labels.
Short Introduction to Semi-Supervised Learning
Semi-supervision is a natural concept often used implicitly. For example, when classifying corporate web pages from personal ones, it seems natural to consider a whole domain as personal if two or three of its pages have already been classified as personal. Attributing the same label to similar items can be seen in machine learning as “propagating” a label to neighboring samples.
A toy example could look like this:
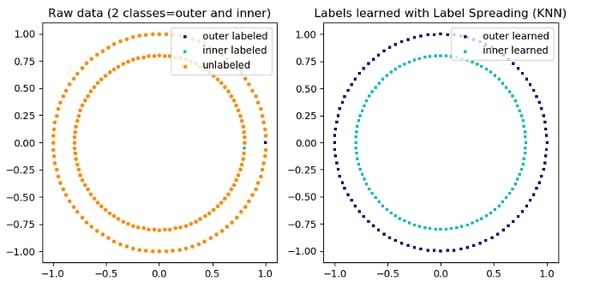 An illustration of label-propagation: The structure of unlabeled observations is consistent with the class structure, and thus the class label can be propagated to the unlabeled observations of the training set. © 2007–2019, scikit-learn developers (BSD License).
An illustration of label-propagation: The structure of unlabeled observations is consistent with the class structure, and thus the class label can be propagated to the unlabeled observations of the training set. © 2007–2019, scikit-learn developers (BSD License).
A good place to start is scikit-learn’s semi-supervised module. It implements two flavors of semi-supervised methods that perform label inference on unlabeled data using a graph-based approach. Label propagation [1] computes a similarity matrix between samples and uses a KNN-based approach to propagate samples. Label spreading [2] has a similar approach but adds a regularization to be more robust to noise. We chose the latter for better performance.
While we restricted our experiment to label spreading, we explored other traditional semi-supervised algorithms :
- Contrastive Pessimistic Likelihood Estimation (CPLE), inspired from [3] and available in semisup-learn, a method that guarantees that the addition of pseudo-labeled data to the training set does not degrade the performance of the classifier,
- Naive Bayes in pomegranate, which performs a vanilla expectation-maximization algorithm.
The underlying (supervised) model can also be used to directly perform the pseudo-labeling: this is known as self-training. We also report the results of our experiments using self-training.
Experiments
Now that we have explained the intuition, many natural questions arise. Does semi-supervised learning improve model performance? How about self-training?
Determining which samples should be pseudo-labeled and how they should be integrated into the training set (using sample weights for instance) is not clear either. We try to answer these questions in the following experiments.
Perimeter. Our goal in this blog post is to start with the simplest semi-supervised approaches. We will therefore not talk about deep learning methods, adversarial methods, or data augmentation.
Experimental Setting. For our experiments, we will assume that the train dataset is partially labeled. The classical supervised approach will make use of only the labeled samples available while the semi-supervised one will use the entire training set, with both labeled and unlabeled data.
At each iteration, we do the following:
- Fit an SSL-model on labeled and unlabeled train data and use it to pseudo-label part (or all) of the unlabeled data.
- Train a supervised model on both the labeled and pseudo-labeled data
We also train a fully supervised model with no pseudo-labeled data at each iteration and refer to it as the base model.
Plots. The training set size is given by the x-axis, while the y-axis is the model score. The confidence intervals are in the 10th and 90th percentile.
Datasets
AG News. AG News is a news classification task with four classes: world, sports, business, and sci/tech. It has 150,000 samples. We performed our experiments on a subset of 10,000 samples. The text is preprocess with GloVe embeddings.
Open ML’s CreditCardFraudDetection dataset. This is a strongly imbalanced dataset composed of 284,000 transactions and only around 500 fraudulent ones. We use a random forest with scikit-learn’s default parameters. Note that we have an F1-score performance metric for this dataset as accuracy is sensitive to class imbalance.
Open ML’s Nomao dataset. This is a geolocation deduplication dataset. Each sample contains features and similarity measures extracted from two samples. This is a binary classification on 34,000 samples. We use a random forest again with scikit-learn’s default parameters.
Comparing Pseudo-Label Selection Methods
Similarly to other machine learning methods, semi-supervised algorithms may label samples with more or less confidence. Here, we consider two strategies:
- A fixed proportion of the dataset. We select the top n, with n = ratio * (number of labeled samples), according to the confidence scores. This method is referred to as “Ratio Pseudo Labels."
- An absolute threshold on the labeling confidence. This method is denoted as “Selecting Pseudo Labels > Threshold” in the legend and mentioned as “uncertainty-based."
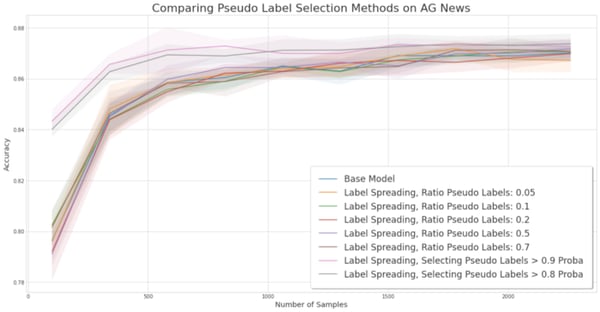
Experiment for comparing pseudo-label selection methods on the AG News dataset.
AG News. This figure shows that uncertainty-based SSL is the only over-performing strategy. SSL is useful with a low number of samples which makes sense since once the dataset reaches a given size, the space of features has been explored and SSL can only confirm the prediction of the model.
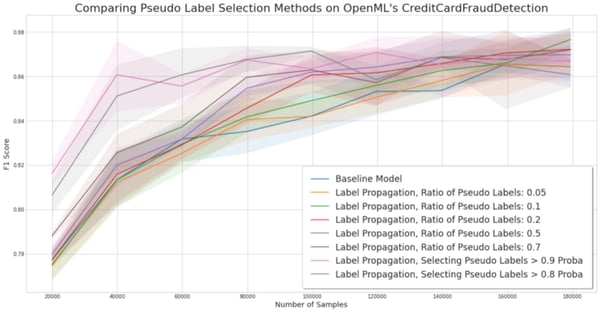 Experiment for comparing pseudo-label selection methods on the credit card fraud detection dataset.
Experiment for comparing pseudo-label selection methods on the credit card fraud detection dataset.
Credit Card Fraud Detection. Here again, the uncertainty-based approach is a clear winner on this dataset. It also confirms that SSL is most useful when a small number of samples are labeled.
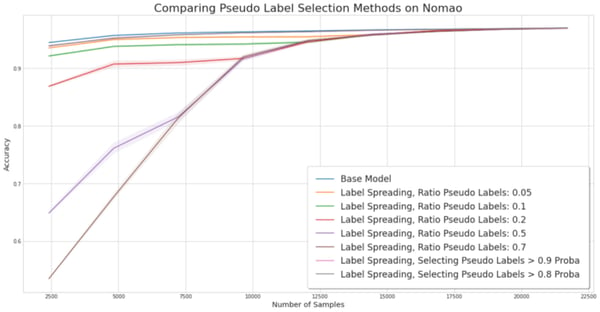 Experiment for comparing pseudo-label selection methods on the Nomao dataset.
Experiment for comparing pseudo-label selection methods on the Nomao dataset.
Nomao. On this dataset, SSL is clearly not performing well. However, we observe that uncertainty-based methods are aware of the low quality of their prediction and therefore few samples are selected. The result is that their performance is comparable to the base model.
Conclusion. Uncertainty-based SSL is equal or better than the base model in most of our experiments. On AG News, they slightly underperform but the effect size is too small to draw a strong conclusion. Selecting pseudo labels based on a probability threshold rather than a simple ratio of true labels seems like the most performant method, and if it is not always performant, it rarely worsens the base classifier.
Using Sample Weights on Pseudo Labels
In our experimental design, we assume that labeled data is more reliable than pseudo-labeled data. We would thus want to prevent pseudo-labeled data to compete against labeled data, as it is done in CPLE.
To handle the uncertainty held in pseudo labels, we propose to underweight them compared to labeled data with the following two different strategies:
- Absolute weighting, with different hard-coded values.
- Relative weighting, by using the confidence score associated with the samples, because using this value has proven useful in other experiments.
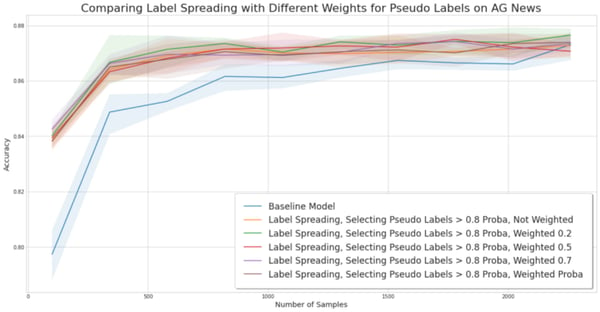 Experiment for comparing sample weighting pseudo labels on the AG News dataset.
Experiment for comparing sample weighting pseudo labels on the AG News dataset.
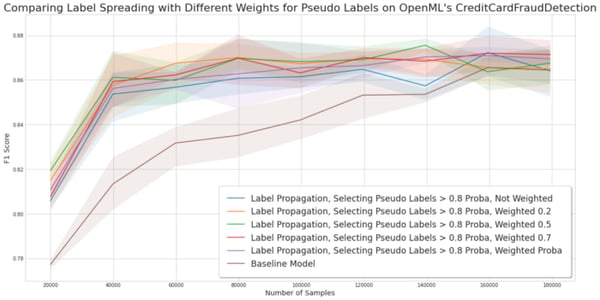
Experiment for comparing sample weighting pseudo labels on the credit card fraud detection dataset.
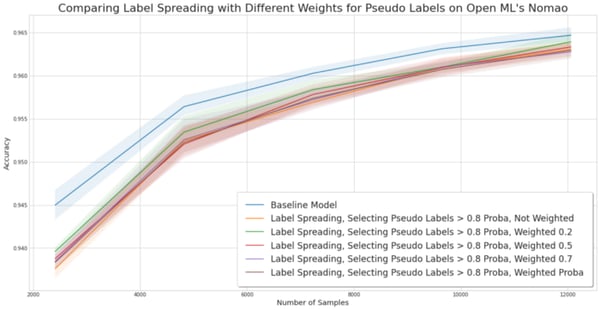
Experiment for comparing sample weighting pseudo labels on the Nomao dataset
Observations. On AG News and fraud detection, the different weighting strategy does not bring an additional uplift, but they do not impact the performance either. We could have thought that underweighting pseudo-labeled samples would have mitigated the down lift generated by SSL, but it is not the case.
Conclusion. In our three experiments, weighting pseudo labels has little to no significant difference with an unweighted method. Note that this may be due to the fact that we have used a pseudo-labeling method that already selects the best samples. If the weights really mattered, then the weighting with absolute values would have impacted the results, in particular on Nomao.
Self Training
As detailed in the introduction, self-training consists of performing semi-supervised learning using the model itself as a pseudo-labeler. The idea behind it is to reinforce the beliefs of the models by iterating through the space of samples.
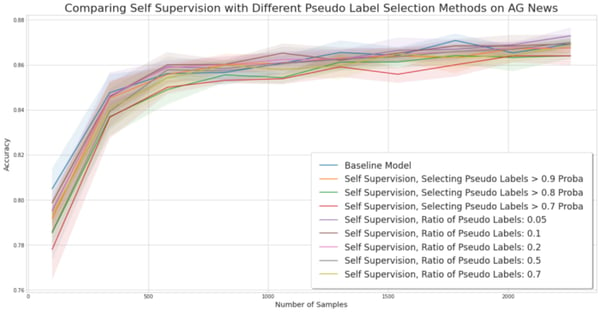 Experiment for comparing self-training methods on the AG News dataset
Experiment for comparing self-training methods on the AG News dataset
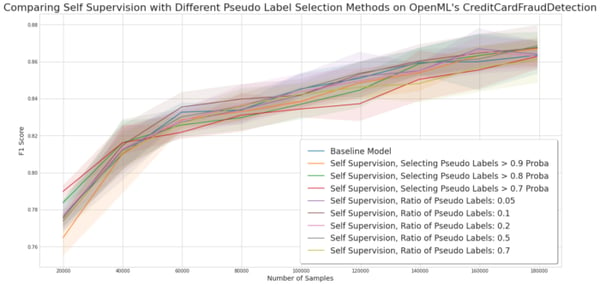
Experiment for comparing self-training methods on the credit card fraud detection dataset.
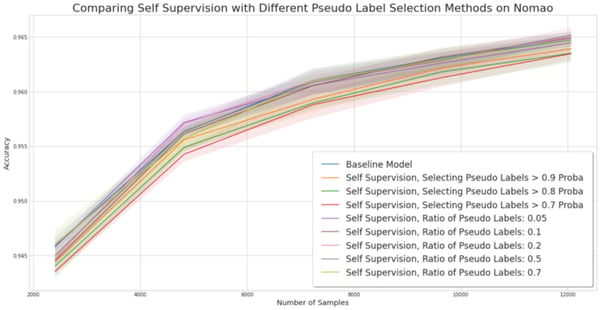
Experiment for comparing self-training methods on the Nomao dataset.
Conclusion. In our experiments, we failed to obtain better performance using self-training. More recent works [4] combine self-training and data augmentation — generations of samples similar to the labeled ones — in order to obtain better performance.
Takeaways: Rediscovering Semi-Supervised Learning
Vanilla semi-supervised learning techniques deserve more attention: they can be useful to improve a base model, provided that the right strategy is used to select the samples to pseudo label.
We saw that semi-supervised learning worked best on a smaller number of samples, making it a relevant method to explore at the beginning of a project.
In our experiments, using a threshold on the confidence score estimated by the Label Spreading method appears to be a good strategy. It also prevents a loss of performance on datasets on which SSL underperforms. On the other hand, we noticed no improvement associated with sample weighting.
Though self-training did not yield positive results on its own, it would be interesting to explore whether a new strategy, combining self and semi-supervision, could be useful. For instance, we could choose to select samples where both classifiers agree, to add certainty to new pseudo labels, or where they disagree, to focus on gray areas.