Big Data: Prescription for the Pharmaceutical R&D Plight
Pharma R&D is a notoriously long and arduous process, and it can take more than 10 years and $2.6 billion to bring a single drug to market. Among the biggest players, the return on investment for R&D fell to 3.7% in 2016. However, a solution could be data analytics, which enhances and accelerates drug development.
This article examines the current state of drug development, and how big data can improve its different components: drug discovery, clinical trial design, and adverse drug reaction detection.

Pharma R&D is a notoriously long and arduous process, and it can take more than 10 years and $2.6 billion to bring a single drug to market. Among the biggest players, the return on investment for R&D fell to 3.7% in 2016. However, a solution could be data analytics, which enhances and accelerates drug development.
This article examines the current state of drug development, and how big data can improve its different components: drug discovery, clinical trial design, and adverse drug reaction detection.

Melissa Lin
Melissa has worked in ECM, tech startups, and management consulting, advising Fortune 500 companies across multiple sectors.
The numbers demonstrate that 2016 was not a great year for the U.S. pharmaceutical industry. As of early December, only 19 new drugs had been approved by the Food and Drug Administration (FDA), fewer than half of those approved in 2015 and the lowest level since 2007. Among the biggest players, the return on investment for research and development (R&D) fell to 3.7%.
Despite these discouraging statistics, the pharmaceutical industry remains integral to the wider healthcare ecosystem. But the industry faces increasing pressure to improve productivity and minimize development time. Returns on R&D serve as an important performance metric for investors, as well as a starting point for dialogue between the industry, payers, and health technology assessment groups, which collectively determine the value of innovative medicines. Industry players can pursue different strategies – including scientific partnerships, investments in emerging markets, and diversification of product portfolios – to counter productivity issues. However, as this piece suggests, another solution includes data analytics, which can enhance and accelerate drug development.
This article examines the current state of drug development, and how big data can improve its different components: drug discovery, clinical trial design, and adverse drug reaction detection. It will then conclude with recommendations for companies looking to integrate these types of solutions.
Decreasing ROI for Pharmaceutical R&D
As mentioned previously, few drug candidates eventually become commercially approved, let alone commercial successes. Only five in 5,000, or 0.1%, of the drugs that begin preclinical testing ever make it to human testing, and only one becomes approved for human use.
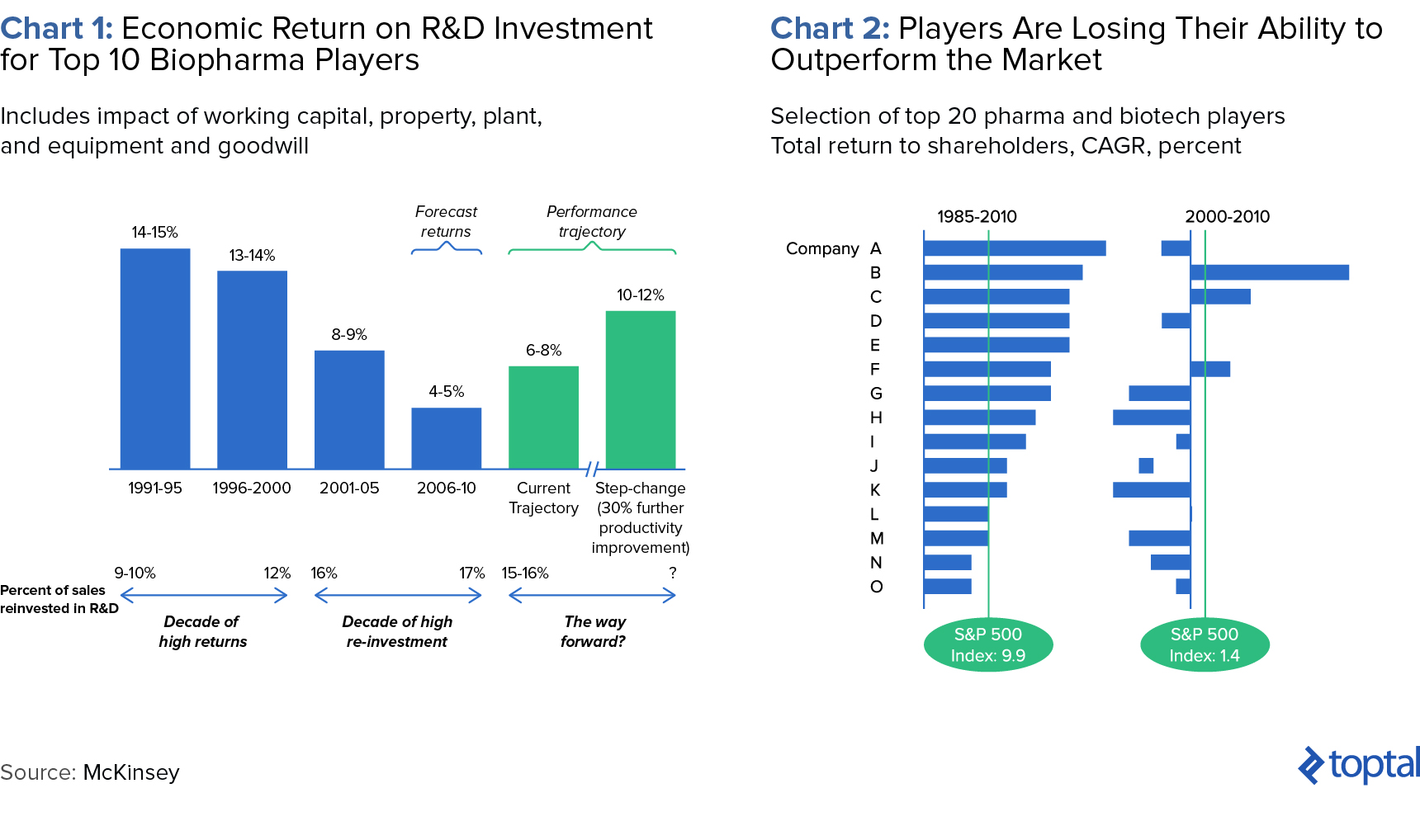
According to a 2012 McKinsey report, cumulative success rates have fallen by 50% as the number of drug development programs and the cost per program have doubled. It’s also widely believed that one-off launches show transient improvements in ROI, overshadowing deeper issues such as growing trial costs and crowded markets. Many pharmaceutical companies have created significant 25-year shareholder value, though their results in the following decade are more modest (see below).
Few would contest that the drug development process is long and arduous. After all, it can take more than 10 years and $2.6 billion to bring a drug to market. It starts when researchers try to understand the process behind a disease at a cellular or molecular level. Through better understanding of disease processes and pathways, potential “targets” for new treatments are identified. If preclinical testing demonstrates safety and efficacy, a candidate moves into successive phases of testing, review, and authorization.
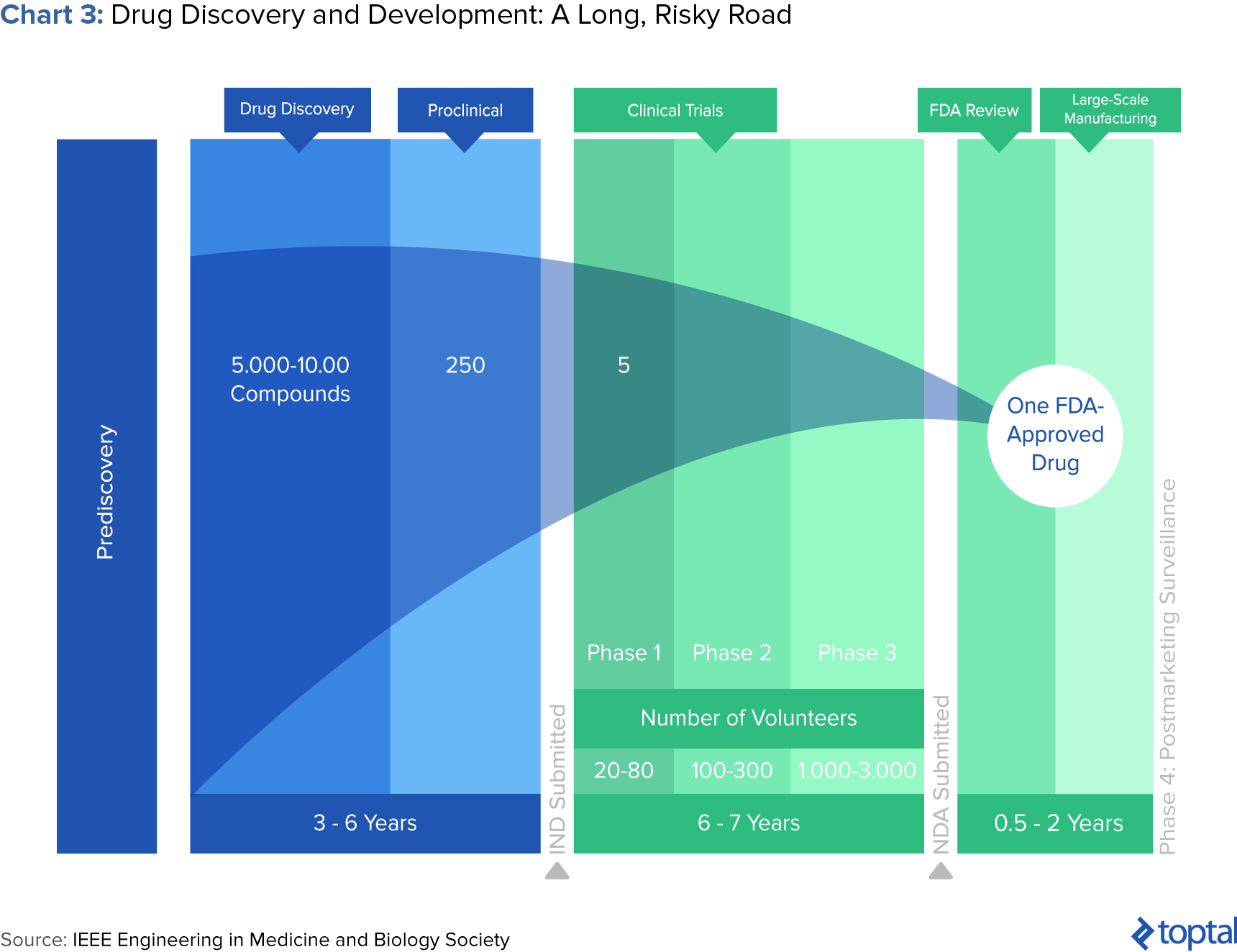
At every step, decisions to advance or halt certain compounds are made based on experimental and historical data. “Failing fast,” or terminating further development based on unsatisfactory performance, is crucial. This is because costs increase at every successive stage of the pipeline, and especially when human trials begin. To combat these difficulties, pharma companies can employ data analytics.
Data Analytics Applications for Pharma Companies
Big data analytics involves the collection, manipulation, and analysis of massive, diverse data sets. It provides promise for pharma companies in several ways: 1) Predictive modeling can unearth targets for the drug pipeline. 2) Statistical tools can improve patient recruitment and enhance monitoring. 3) Data mining of public forums and social media sites can identify adverse drug reactions not formally reported. Let’s delve into each use case.
Predictive Modeling in Drug Discovery
If you were a marketing company looking to optimize conversions, you’d invest resources into your target market rather than the entire population. It’s similar in drug discovery—pharma companies aim to invest in compounds likely to succeed in clinical trials and the market so they can recover initial R&D investments.
In the past, researchers used natural plant or animal compounds as the basis for candidate drugs. Drug development has historically been an iterative process using high-throughput screening (HTS) labs to physically test thousands of compounds a day, with an expected hit rate of 1% or less. But now scientists are creating new molecules with computers. Predictive modeling, both sophisticated and basic, can help predict candidate drug interaction, inhibition, and toxicity. A widespread method is pharmokinetic modeling, which uses advanced mathematical modeling and simulations to predict how the compound will act in the body. Even without available protein structure information, screening of virtual compound libraries allows researchers to consider as many as 10,000 compounds, and narrow it down to 10 or 20.
These capabilities do not necessarily have to be built in-house. Recently, IBM Watson Health and Pfizer forged a partnership to help researchers discover new drug targets. While the average researcher reads 250-300 articles in a year, Watson has processed 25 million Medline abstracts, over one million full-text medical journal articles, and four million patents. Watson can even be augmented with an organization’s private data to reveal hidden patterns.
A simpler approach includes the application of historical data from pre-clinical studies, clinical trials, and post-marketing surveillance. The data can be used to predict the final outcome (FDA approval/patient outcomes) based on various independent variables.
Data-hungry Processes Lead to Increased Collaboration
Paywalls and patents have long slowed the flow of information in the hypercompetitive industry. So an interesting trend is growing collaboration amongst industry parties. For example, nonprofit Structural Genomics Consortium partners with nine pharma companies and labs, who have pledged to share their drug wish lists, results in open access journals, and experimental samples to speed up discovery.

Similarly, UK startup MedChemica is at the core of a collaboration designed to accelerate development using data mining while maintaining each partner’s intellectual property. MedChemica’s technology mines partners’ databases of molecules to find closely matched pairs, performs an analysis between the two, and the output is then used to create rules that can be applied to virtual molecules to predict the impacts of similar structural changes. All partners in the consortium can suggest where additional data is needed, and can even agree to share costs in further testing.
Better Clinical Trial Design
Clinical trials are research studies that test whether a treatment is safe and effective for humans. There are three phases before a drug moves into FDA review. Each subsequent phase involves more individuals, increasing from tens in Phase I to thousands in Phase III. The process typically takes six to seven years to complete. Delays in market launch can amount to $15 million per day in opportunity costs for a blockbuster drug. Here are some clinical trial pain points, and how big data can alleviate them:
Enhanced, Targeted Recruiting
Trial failure is often caused by the inability to recruit enough eligible patients. Phase III trials are conducted at over 100 sites in ten or more countries. And, because drugs are now often designed for niche populations, companies compete to recruit the same patients. As a result, 37% of clinical trials fail to reach their recruitment goals and 11% of sites fail to recruit a single patient. According to the National Cancer Institute, only 5% of cancer patients join clinical trials. The traditional method of recruitment for eligible patients is manual review of physicians’ patient lists—but it’s expensive and slow.
Here’s where electronic patient hospital data and big data can help. With analytics and data scientists, patients can be enrolled based on sources other than doctors’ visitors, like social media. The criteria for patient selection can now include factors like genetic information, disease status, and individual characteristics, enabling trials to be smaller, shorter, and less expensive. “It’s like fishing with a fish finder,” said John Potthoff, chief executive officer at Elligo Health Research. “You can really see where patients are and where to go to get them. When you are looking at a bigger pool, you can be more targeted in finding patients who meet the inclusion and exclusion criteria the best.” Ellen Kelso, executive director at Chesapeake IRB, an independent institutional review board which consults pharmaceutical companies, estimates that more than 60% of trials use preliminary online analysis to identify potential participants.
Stronger and More Efficient Trial Management
Automation and big data allow for trials to be monitored in real time. They can identify safety or operational signals, helping to avoid costly issues such as adverse events and delays. According to a recent McKinsey report, potential clinical trial efficiency gains include:
- Dynamic sample-size estimation and other protocol changes could enable rapid responses to emerging insights from the clinical data. They also enable smaller trials of equivalent power or shorter trial times, leading to efficiency gains.
- Adapting to differences in site patient-recruitment rates would allow a company to address lagging sites, bring new sites online if necessary, and increase recruiting from successful sites.
- Using electronic medical records as the primary source for clinical-trial data rather than having a separate system could accelerate trials and reduce manual data entry errors.
- Next-generation remote monitoring of sites enabled by real-time data access could improve management and responses to issues that arise in trials.
Supplementing Clinical Trial Data with Real World Data
The industry has experienced an explosion in available data beyond what’s collected from traditional, tightly controlled clinical trial environments. While anonymized electronic health record (EHR) data has been analyzed in the past, it’s usually limited to a single research institution or provider network. However, it is now possible to link different data sources, allowing complex research questions to be addressed.
For example, the analysis of EHR patient data collected in real time during doctor or hospital visits can help us better understand treatment patterns and clinical outcomes in the real world. These insights complement those gained from clinical trials and can assess a wider spectrum of patients typically excluded from trials (e.g., elderly, frail, or immobile patients, etc.). Pharmaceutical giant Genentech has invested heavily in this approach, analyzing databases of real-world patients to understand outcomes of different patient subtypes, treatment regimens, and how different treatment patterns affect clinical outcomes in the real world.
Adverse Drug Reactions Detection
Harmful reactions caused by medication are known as adverse drug reactions (ADRs). Because clinical trials do not fully mimic real-world conditions, a drug’s consequences cannot be fully assessed prior to market launch. And, ADR reporting systems rely on spontaneous regulatory reports that have passed through lawyers, clinicians, and pharmacists, where information may be lost or misinterpreted. Therefore, ADR detection and reporting are often incomplete or untimely. It is estimated that up to 90% of side effects to drugs are not reported.
Many drug users instead take to social media like Twitter, Facebook, and public medical forums including Medications.com and DailyStrength.com to voice complaints or report side effects. Many users even include hashtags for regulatory agencies (e.g., #FDA), manufacturers (#Pfizer, #GSK), and specific products (#accutaneprobz). Mining these sites for patient-provided ADRs can prove more accurate than those diagnosed by medical professionals. According to David Lewis, head of global safety as Novartis, “Mining data from social media gives us a greater chance of capturing ADRs that a patient wouldn’t necessarily complain about to their doctor or nurse…a psychiatrist can’t see suicidal ideation as an ADR while a patient can describe it perfectly.” Sentiment analysis, which computationally identifies and categorizes opinions expressed in text, can also be performed.

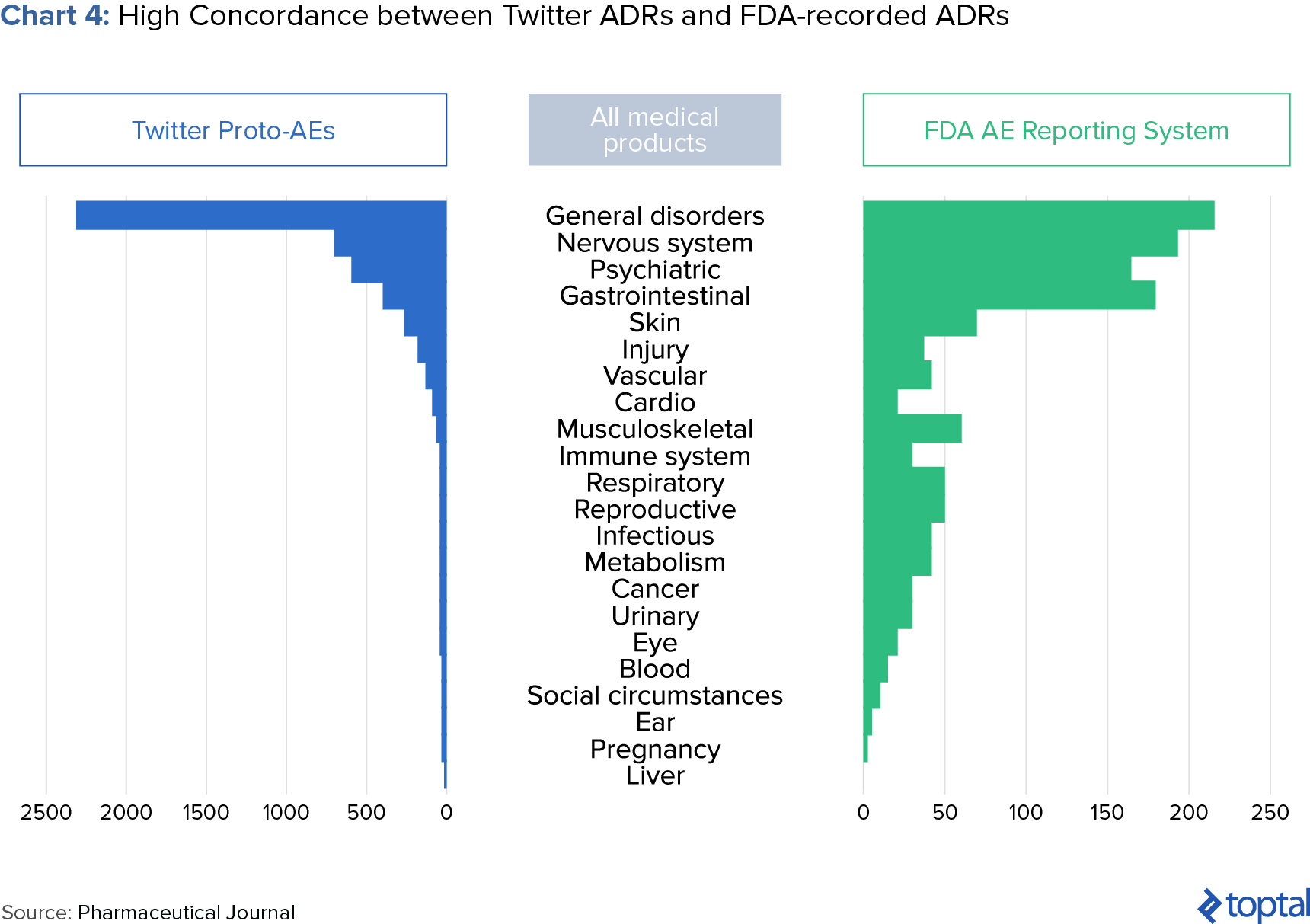
Epidemico, a subsidiary of Booz Allen Hamilton, uses natural language processing and machine learning algorithms to search for ADRs from social media posts for some 1,400 drugs. A 2014 study, jointly launched by the FDA and Epidemico, examined 6.9 million Twitter posts and found 4,401 tweets that resembled an ADR. When compared with data held by the FDA, the study found a high relation between informal social media reports and those reported in clinical trials (see chart below).
Recommendations for Pharma Companies Looking to Implement These Features
Despite its benefits, many pharmaceutical companies are wary of investing in big data analytical capabilities. Below are some recommendations for success in implementation:
-
Technology and analytics. Pharmaceutical companies utilizing legacy systems should increase the ability to share data by connecting these systems. Additionally, pharmaceutical R&D should leverage cutting-edge tools such as biosensors and health-measurement devices in smartphones. Data from smart devices and remote monitoring of patients through sensors and devices could facilitate R&D, analyze efficacy, and enhance future sales. For example, Google has struck a partnership with Novartis to develop a smart contact lens that monitors diabetics’ glucose levels, while Roche and Qualcomm are joining forces on elevating anti-coagulation monitors, which guard against blood clots, to wirelessly transmit patient information.
-
Focus on real-world evidence. Real-world outcomes are becoming more important as payors utilize value-based pricing. Companies can differentiate themselves by pursuing drugs with tangible real-world outcomes, such as those targeted at niche patient populations. To expand their data beyond clinical trials, they can even join proprietary data networks.
-
Collaborate internally and externally. Pharmaceutical R&D has historically been cloaked in secrecy—but both internal and external collaboration will be key for success with big data. Improving internal collaboration requires streamlined communication between discovery, clinical development, and medical affairs. This can lead to insights across the portfolio, including clinical identification and potential opportunities in personalized medicine. External collaboration is also important: academic researchers can provide insight into the latest scientific breakthroughs, initiatives spearheaded with other pharma companies can create a greater, more powerful data pool to leverage for discovery, and contract research organizations (CROs) can help scale an internal effort or provide specific expertise.
-
Organization. To avoid data silos and facilitate the sharing of data, it’s best to assign owners to different data types, with their reach extending across functions. The expertise gained by the data owner will be invaluable when developing ways to use existing information or to integrate additional data. It would also enhance accountability for data quality. However, these changes are only possible if company leadership genuinely supports the value of big data.
Parting Thoughts
Today, it’s clear that the life sciences, computer science, and data science are converging. Though technical and cultural challenges undoubtedly lay ahead, advanced data analytics is a lever pharma companies can pull to combat unfavorable R&D economics. Of course, though, the promise of big data will remain just that if organizations do not take strategic steps in implementation.
According to Glen de Vries of SaaS company Medidata, big data “can cure life science’s R&D malaise.” During the Global Pharmaceuticals and Biotechnology Conference hosted by The Financial Times, he compared big data to the discovery of the Rosetta Stone, which allowed scholars to decipher hieroglyphics and unlock Ancient Egyptian history. Similarly, if datasets can be combined within the healthcare system, including information coming from genomics/proteomics, in-clinic data recorded by physicians, and mobile health, medical research will undergo a revolution.