

The business benefits of generative AI (GenAI) are compelling. A recent McKinsey report estimates that GenAI could add the equivalent of $2.6 to $4.4 trillion annually across 63 use cases they analyzed.1 Over time, organizations will reengineer their IT environment, data architecture and processes to capitalize on this transformative opportunity.
But what about the nearer term? Organizations are identifying generative AI opportunities in the present that can’t wait. How can businesses target the power of GenAI to enhance business effectiveness now?
Get the Most Out of Your Data by Limiting Scope
The GenAI large language models (LLMs) that have received so much attention have been trained and fine-tuned with massive amounts of data. Yet very few organizations have the resources or expertise today to train a model from scratch.
A more feasible option for many organizations, particularly in the nearer term, will be to fine-tune or augment an existing model with their own context-specific data. To further control scope and expense, the base model can be a language model specific to a particular domain, such as healthcare, legal services or finance.
Fine-tuning or augmenting a pre-trained model limits the scope of data discovery, exploration and enrichment to those datasets that are relevant to the use cases you select. It is also much less time-consuming than training a model and results in a more relevant and accurate model, compared with using a pre-trained model “as-is.”
RAG and Vector Databases Enable Better Outcomes
Retrieval-augmented generation, or RAG, is a method to rapidly augment an existing language model with enterprise or context-specific information. Dell Technologies believes that model augmentation will be a popular alternative early on, as it allows organizations to bound GenAI use cases.
RAG takes data from structured and unstructured sources, which can be contextual or up-to-date data the language model cannot access on its own. The target data must be converted into a compatible format for the retrieval mechanism. For enhanced accuracy and RAG retrieval speed, target data can be converted into vector representations and stored in a vector database.
By drawing from vector databases, GenAI models can process complex relationships between data for better outcomes. Tools and best practices to create these representations with reasonable effort are available and are continually being improved.
Discover, Explore and Enrich Key Data, then Observe Output
Data to be ingested by a GenAI model requires preparation to ensure data quality, proper formatting and data sensitivity classification. Both structured and unstructured data are needed for augmenting or tuning language models, so the methods for data cleansing, labeling and anonymizing must address data traditionally located in both data lakes and data warehouses. Much of the unstructured data may need to be organized and enriched before it can be used as a tuning data source.
A major consideration for certain use cases is the flow or sequence of words, steps or activities—for example, an insurer’s claim processing steps or the question-answer sequence to resolve a customer issue. Data preparation for GenAI models may include quality improvement and summarization of text or workflow data, question-answer-context and instruction-response datasets.2
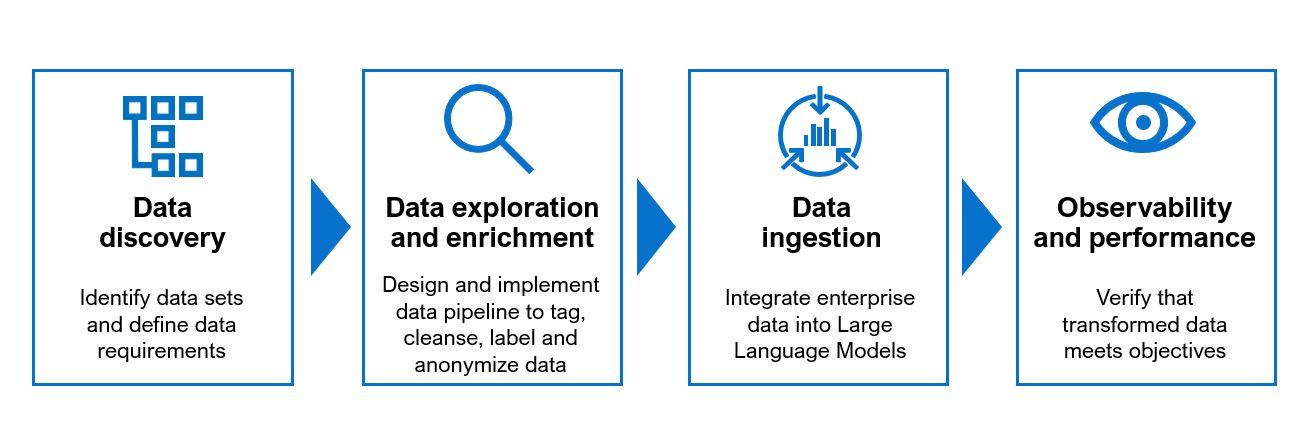
GenAI models should be tuned with the best data sources aligned to the use cases. Before a GenAI project is released to production, data scientists should verify that the transformed data meets the project objectives. In addition, it’s vital to ensure sensitive or proprietary data is handled properly and protected.
It Takes Expertise to Move Fast with GenAI
It’s no surprise one of the constraints organizations face in accelerating their GenAI projects is the scarcity of professionals with skills in data discovery, data exploration and enrichment. An ESG report stated that “39% of organizations said expertise or skills is one of the biggest challenges they face with implementing GenAI,” which was the highest percentage for all the challenges listed.3
A competent, experienced partner can make a big difference in quickly identifying and prioritizing use cases and then preparing the data and selecting and fine-tuning models. Organizations who want to address more use cases sooner to maximize GenAI impact can turn to Dell Consulting Services and leverage our consulting experts to accelerate time to value from bringing generative AI to their data.
For more information on the broad range of Dell Technologies services for generative AI, please see Services for generative AI.
1 https://www.mckinsey.com/capabilities/mckinsey-digital/our-insights/the-economic-potential-of-generative-ai-the-next-productivity-frontier
2 https://h2o.ai/blog2/2023/streamlining-data-preparation-for-fine-tuning-of-large-language-models/
3 https://www.techtarget.com/esg-global/research-report/research-report-beyond-the-genai-hype-real-world-investments-use-cases-and-concerns/
