
Reading Azure EventHub Data into DataFrame Using Apache Spark – Scala
Apache Spark provides a seamless way to ingest and process streaming data from Azure EventHubs into DataFrames. In this tutorial, we’ll walk through the setup and configuration steps required to achieve this integration.
Prerequisites:
Before diving into the code, ensure you have the necessary setup and permissions:
- Basic knowledge of setting up Event Hubs, Key Vaults, and managing secrets. (Included general overview that covers the initial steps required)
- Azure EventHub instance created (in this example, we’ll use “myehub”).
- Access to Azure Key Vault to securely store and access the required credentials.
- Basic knowledge of Scala, Apache Spark and Databricks Notebooks.
1. Setting Up the Configuration:
Let’s start by defining the essential parameters and importing the required libraries:
val eventHub = "myehub"
val namespaceName = "contosoehubns"
val sharedAccessKeyName = "test"
val environment = "dev"
val keyvault_name = "kv-test-01-dev"
// Retrieve the shared access key from Azure Key Vault
val sharedAccessKey = dbutils.secrets.get(scope = keyvault_name, key = "KEY")
// Import necessary Spark and Event Hubs libraries
import org.apache.spark.eventhubs.{ConnectionStringBuilder, EventHubsConf, EventPosition}
import org.apache.spark.sql.functions.{explode, split}
import org.apache.spark.sql.types.StringType // Necessary for casting to StringType
import org.apache.spark.sql.Row
2. Creating the EventHub Connection String:
Construct the connection string using the provided information:
val connectionString = ConnectionStringBuilder() .setNamespaceName(namespaceName) .setEventHubName(eventHub) .setSasKeyName(sharedAccessKeyName) .setSasKey(sharedAccessKey) .build // Define EventHubs configuration with starting position val eventHubsConf = EventHubsConf(connectionString).setStartingPosition(EventPosition.fromStartOfStream)
3. Reading EventHub Data into DataFrame:
Now, let’s read the streaming data from EventHubs into a DataFrame using Spark’s structured streaming capabilities:
val df = spark
.readStream
.format("eventhubs")
.options(eventHubsConf.toMap)
.load()
// Display schema
df.schema
Schema Output:

//Display EventHub Streaming data
display(df)
// Display filter data based on enqueuedTime
display(df.select( $"body".cast(StringType), $"partition", $"offset", $"sequenceNumber", $"enqueuedTime", $"publisher", $"partitionKey".cast(StringType), $"properties", $"systemProperties" ).filter("enqueuedTime >= '2023-06-14T00:47:33.093+0000'"))
With these configurations and code snippets, you can seamlessly set up Apache Spark to read streaming data from Azure EventHubs into a DataFrame. Output without the filters would give continuous data stream until stopped. Make sure to adjust the parameters according to your specific Azure environment and requirements.
By leveraging the power of Spark’s structured streaming and Event Hubs’ scalability, you can efficiently process and analyze real-time data within your Spark workflows.
Setting Up Azure Event Hubs:
- Azure Portal Login:
- Go to the Azure Portal and sign in with your credentials.
- Create Event Hub Namespace:
- Navigate to “Create a resource” > “Internet of Things” > “Event Hubs Namespace”.
- Fill in the necessary details like Subscription, Resource Group, Namespace name, Region, etc.
- Once created, you can access your Event Hub Namespace.
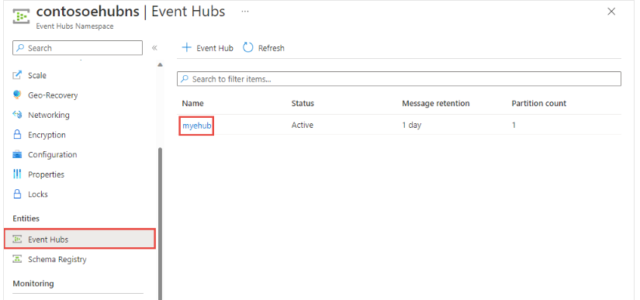
- Create Event Hub:
- Inside the Event Hub Namespace, go to “Event Hubs”.
- Click on “Add” to create a new Event Hub instance.
- Provide a name for the Event Hub (e.g., “myehub”) and configure other settings as needed.
- After creation, you can manage your Event Hub from this interface.
Setting Up Azure Key Vault:
- Create Key Vault:
- In the Azure Portal, go to “Create a resource” > “Security + Identity” > “Key Vault”.
- Enter details like Subscription, Resource Group, Key Vault name, Region, etc.
- Once created, navigate to the Key Vault resource.
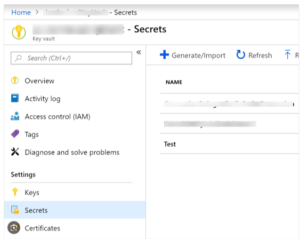
- Add Secrets to Key Vault:
- In the Key Vault menu, go to “Secrets” and click “Generate/Import”.
- Enter the secret details, like name and value.
- Ensure the secret’s access policies are appropriately configured to allow access to the intended services or users.
Microsoft link to setup keys/secrets.
https://azuredevopslabs.com/labs/vstsextend/azurekeyvault/
Accessing Secrets from Key Vault:
- Grant Access to Services/Applications:
- Define the access policies for the services that need to retrieve secrets from the Key Vault.
- For example, if you need Spark to access secrets, you’ll grant appropriate permissions for the Spark service principal.
- Accessing Secrets Programmatically:
- Use Azure SDKs or tools like Azure CLI to retrieve secrets programmatically.
- For instance, in Python, you can use the
azure-keyvault-secretslibrary to access secrets.

