
Reading Azure EventHub Data into DataFrame using Python in Databricks
Azure EventHubs offer a powerful service for processing large amounts of data. In this guide, we’ll explore how to efficiently read data from Azure EventHub and convert it into a DataFrame using Python in Databricks. This walkthrough simplifies the interaction between Azure EventHubs and the ease of working with DataFrames.
Prerequisites:
Before diving into the code, ensure you have the necessary setup and permissions:
- Basic knowledge of setting up EventHubs, Key Vaults, and managing secrets.
- Azure EventHub instance created (in this example, we’ll use “myehub”).
- Access to Azure Key Vault to securely store and access the required credentials.
- Basic knowledge of Scala, Apache Spark and Databricks Notebooks.
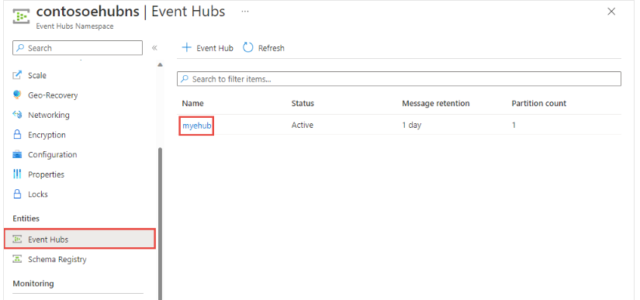
1. Setting Up the Configuration:
td_scope = "kv-test-01-dev"
namespace_name = "contosoehubns"
shared_access_key_name = "test"
eventhub = "myehub"
shared_access_key = dbutils.secrets.get(scope=td_scope, key="KEY")
# Construct the connection string
connection = f"Endpoint=sb://{namespace_name}.servicebus.windows.net/;SharedAccessKeyName={shared_access_key_name};SharedAccessKey={shared_access_key};EntityPath={eventhub}"
# Define the consumer group
consumer_group = "$Default"
Firstly, this script initializes the configuration for accessing Azure EventHub within a Databricks environment. It sets parameters like the scope, namespace, access key details, and the eventhub itself. Additionally, it constructs the connection string necessary for interfacing with the EventHub service, enabling seamless data consumption.

2. Read EventHub Data
Utilize the Azure SDK for Python (azure-eventhub) to read data from the EventHub. Further, define a function (read_event) to process incoming events and print the data and associated metadata.
pip install azure-eventhub
from azure.eventhub import EventHubConsumerClient
def read_event(partition_context, event):
event_data = event.body_as_str()
enqueued_time = event.enqueued_time
partition_id = partition_context.partition_id
# Process data or perform operations here
print(event_data)
print(enqueued_time)
partition_context.update_checkpoint(event)
# Create an EventHub consumer client
client = EventHubConsumerClient.from_connection_string(connection, consumer_group, eventhub_name="data01")
with client:
# Start receiving events
client.receive(on_event=read_event, starting_position="-1")
The function, read_event, is called for each event received from the EventHub. It extracts information from the event, such as event_data (the content of the event), enqueued_time (the time the event was enqueued), and partition_id (ID of the partition from which the event was received). In this example, it simply prints out the event data and enqueued time, but this is where you’d typically process or analyze the data as needed for your application.
Here, an instance of EventHubConsumerClient is created using the from_connection_string method. It requires parameters like connection (which contains the connection string to the Azure EventHub), consumer_group (the consumer group name), and eventhub_name (the name of the EventHub).
Finally, the client.receive method initiates the event consumption process. The on_event parameter specifies the function (read_event in this case) that will be called for each received event. The starting_position parameter specifies from which point in the event stream the client should start consuming events (“-1” indicates starting from the most recent events).
Also, The output from this cell would give continues events until stopped.
3. Transform to DataFrame
To convert the received data into a DataFrame, employ the capabilities of Pandas within Databricks. Initialize a DataFrame with the received event data within the read_event function and perform transformations as needed.
import pandas as pd
# Inside read_event function
data = pd.DataFrame({
'Event_Data': [event_data],
'Enqueued_Time': [enqueued_time],
'Partition_ID': [partition_id]
})
# Further data manipulation or operations can be performed here
# For example:
# aggregated_data = data.groupby('Some_Column').mean()
# Display the DataFrame in Databricks
display(data)
Therefore here, we’ve outlined the process of reading Azure EventHub data using Python in Databricks. The Azure EventHub Python SDK provides the necessary tools to consume and process incoming data, and by leveraging Pandas DataFrames, you can efficiently handle and manipulate this data within the Databricks environment.
Experiment with various transformations and analysis techniques on the DataFrame to derive meaningful insights from the ingested data.
Check out this link for guidance on reading “Azure EventHub data into a DataFrame using Scala in Databricks”, along with a concise overview of setting up EventHubs, KeyVaults, and managing secrets.

