What does it take to store all New York Times articles published between 1855 and 1922? Depending on how you measure it, the answer is 11 million newspaper pages or… just one Hadoop cluster and one tech specialist who can move 4 terabytes of textual data to a new location in 24 hours.
The biggest star of the Big Data world, Hadoop was named after a yellow stuffed elephant that belonged to the 2-year son of computer scientist Doug Cutting. The toy became the official logo of the technology, used by the major Internet players — such as Twitter, LinkedIn, eBay, and Amazon.
So the first secret to Hadoop's success seems clear — it’s cute. And, if serious, the deserved popularity needs a more detailed explanation. This article highlights Hadoop's pros, pinpoints its cons, and tells about available alternatives.
What is Hadoop?
Apache Hadoop is an open-source Java-based framework that relies on parallel processing and distributed storage for analyzing massive datasets. Developed in 2006 by Doug Cutting and Mike Cafarella to run the web crawler Apache Nutch, it has become a standard for Big Data analytics.
According to a study by the Business Application Research Center (BARC), Hadoop found intensive use as
a runtime environment (sandbox) for classic business intelligence (BI), advanced analysis of large volumes of data, predictive maintenance, and data discovery and exploration;
a suitable technology to implement data lake architecture.
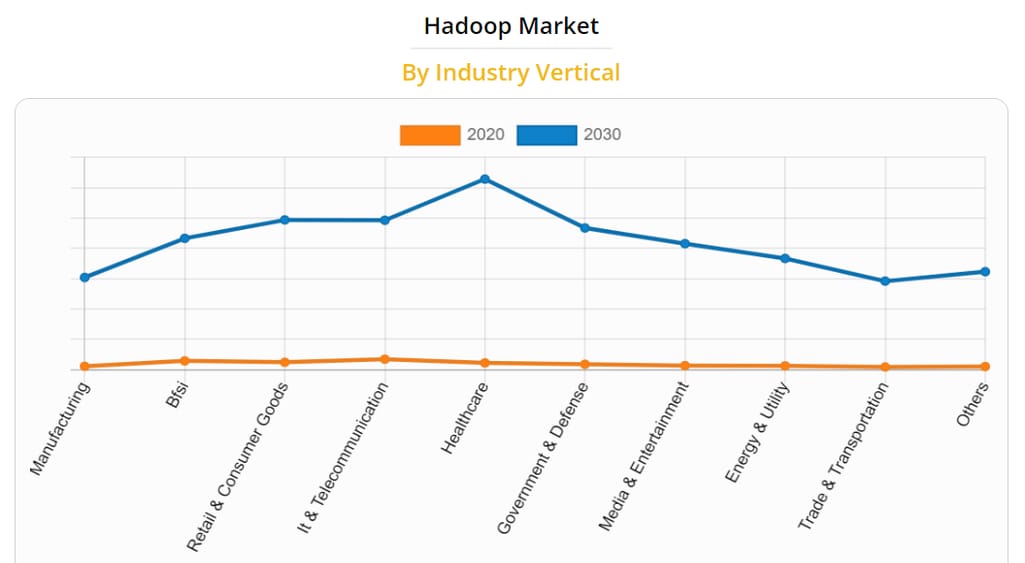
Many industries, from manufacturing to banking to transportation, take advantage of what Hadoop can offer. And the number of companies adopting the platform is projected to increase by 2030. According to the latest report by Allied Market Research, the Big Data platform will see the biggest rise in adoption in telecommunication, healthcare, and government sectors.
The expected rise of the Hadoop market across industries. Source: Allied Market Research.
But to understand why Hadoop is so lucrative, we need to look at how the framework works from the inside.
Apache Hadoop architecture
What happens when a data scientist, BI developer, or data engineer feed a huge file to Hadoop? Under the hood, the framework divides a chunk of Big Data into smaller, digestible parts and allocates them across multiple commodity machines to be processed in parallel. So, instead of employing a costly, elephant-sized supercomputer, Hadoop interconnects an army of widely-available and relatively inexpensive devices that form a Hadoop cluster.
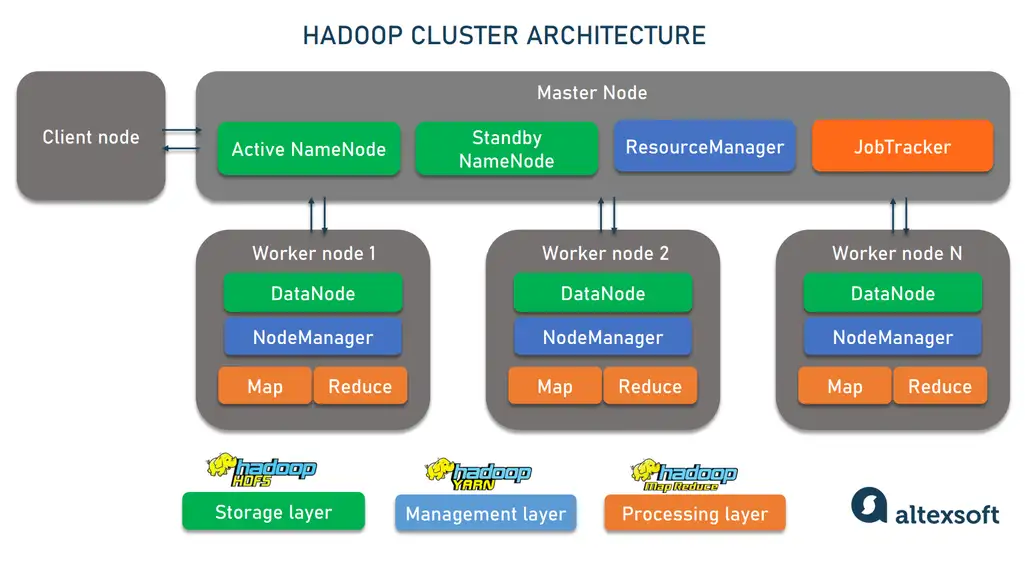
Hadoop cluster: shared-nothing approach
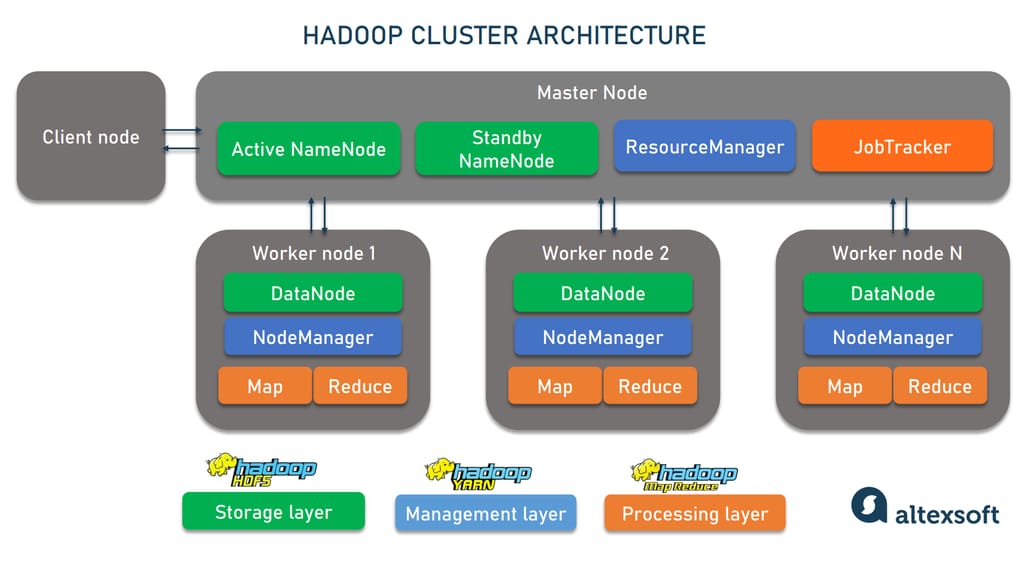
A Hadoop cluster is a group of computers called nodes that act as a single, centralized system working on the same task. Each node is a self-sufficient and independent unit with its own memory and disk space. In other words, it shares no resources with other machines except for a common network. This shared-nothing architecture delivers a lot of benefits we’ll discuss later.
How a Hadoop cluster is structured.
Yet, independence doesn’t mean equality. In fact, nodes form three distinct groups with their own roles:
A master node takes care of data and resource distribution and coordination of parallel processing. This role requires the best hardware available;
a slave or worker node actually performs jobs assigned by the master node, and
a client or edge node serves as a gateway between a Hadoop cluster and outer systems and applications. It loads data and grabs the results of the processing staying outside the master-slave hierarchy.
What is the size of a Hadoop cluster? It depends on the volume of incoming data. One of the world’s largest Hadoop clusters belongs to LinkedIn and consists of around 10,000 nodes. But you can start with as few as four machines (one to run all master processes and three for slave jobs) and add new nodes later to scale the project. Note that just a single computer will be enough to deploy Hadoop for assessment and testing purposes.
No matter the actual size, each cluster accommodates three functional layers — Hadoop distributed file systems for data storage, Hadoop MapReduce for processing, and Hadoop Yarn for resource management.
Hadoop distributed file system: write once, read many times approach
Hadoop distributed file system or HDFS is a data storage technology designed to handle gigabytes to terabytes or even petabytes of data. It divides a large file into equal portions and stores them on different machines. By default, HDFS chops data into pieces of 128M except for the last one. But you can configure the block size.
HDFS is based on the write once, read many times principle. It focuses on retrieving the entire file in the fastest possible way rather than on the speed of the storing process. You can use the whole dataset for different analytical purposes again and again, but there is no way to edit or change the dataset once you save it.
How HDFS master-slave structure works. A master node called NameNode maintains metadata with critical information, controls user access to the data blocks, makes decisions on replications, and manages slaves. Besides an active NameNode, there are standby NameNodes ready to pick up the operations if the primary master breaks down. Hadoop 2 supports just one standby machine and Hadoop 3 allows for multiple spare masters.
Numerous slave nodes or DataNodes, organized in racks, store and retrieve data according to instructions from the NameNode.
Hadoop MapReduce: split and combine strategy
MapReduce is a programming paradigm that enables fast distributed processing of Big Data. Created by Google, it has become the backbone for many frameworks, including Hadoop as the most popular free implementation.
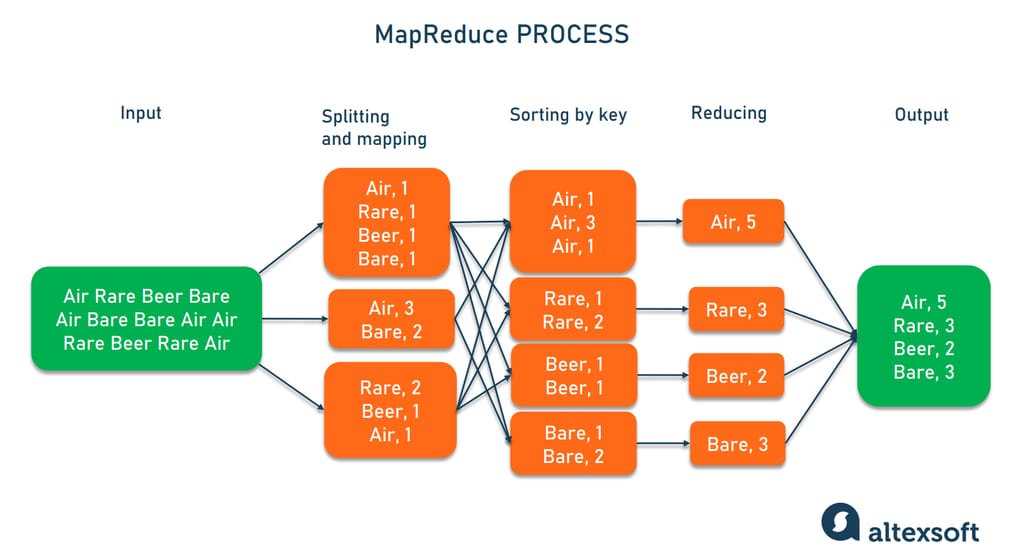
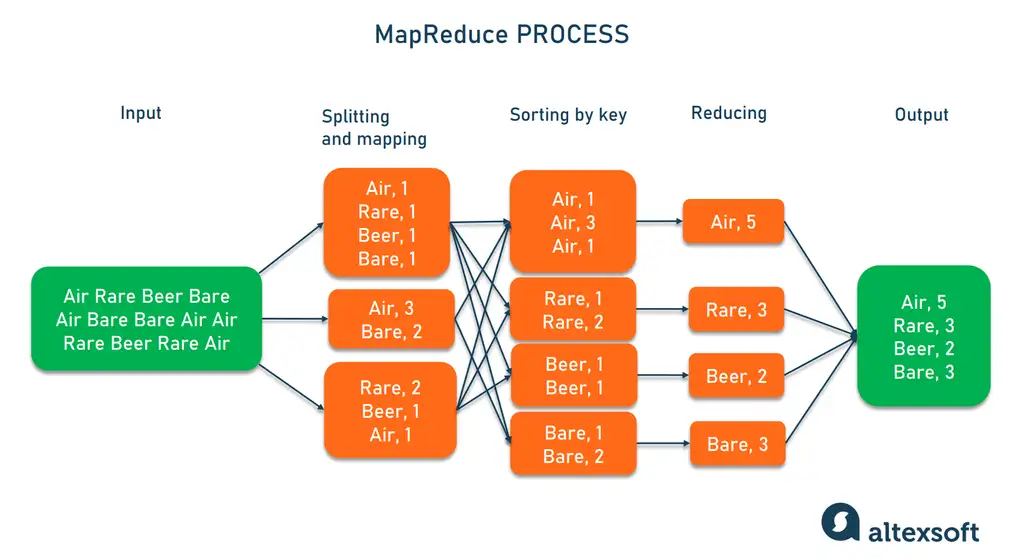
The MapReduce process involves two steps — map and reduce.
1. The map script splits large data inputs into smaller chunks and applies your rules to form pairs of key and value parameters. For example, our task is to investigate word frequencies in a text. Then, the key and value would be “word” and “count” respectively. If the mapper comes upon the word “air” three times in a certain data portion, you’ll get the pair <air, 3>.
2. The reduce script sorts the results by key and combines the values — again, following your instructions. In our case, the reducer will sum up counts for the same words collected from all chunks. The diagram below vividly describes the idea.
How MapReduce counts words.
How MapReduce master-slave architecture works. A master node — a JobTracker — receives tasks from a client node and communicates with HDFS’s NameNode to locate DataNodes with requested data. Then, it submits jobs to the nearest MapReduce slave — TaskTracker. Typically, a TaskTracker resides on the same server as DataNodes it works with.
The worker performs map and reduce steps following instructions from a JobTracker, and notifies the master about its progress. If a certain TaskTracker fails, the master reassigns the job to the next nearest slave node.
Hadoop Yarn: a bridge between HDFS and Big Data applications
YARN is short for Yet Another Resource Negotiator. Often called the brain of Hadoop, this layer controls distributed applications. It relieves the MapReduce engine of scheduling tasks and decouples data processing from resource management.
Thanks to YARN, which acts as an operating system for Big Data apps and bridges them with HDFS, Hadoop can support different scheduling methods, data analysis approaches, and processing engines other than MapReduce — for instance, Apache Spark.
How YARN master-slave architecture works. A YARN master — ResourceManager — has a holistic view of CPU and memory consumption across the cluster and optimizes the utilization of resources. Its slaves, NodeManagers, cater to individual nodes, reporting on their available resources, status, and health to the master.
Hadoop advantages
The Hadoop architecture and principles it follows at different levels generate numerous advantages that make it one of the best Big Data frameworks.
Cost efficiency
Though it’s not the main reason to opt for Hadoop, cost efficiency remains a strong argument in favor of the framework. The software part is open-source, free of charge, and easy to set up.
As for hardware, there is no need for costly custom systems. The capabilities of relatively cheap commodity servers will be enough to run Hadoop. Moreover, it gives IT specialists the freedom to choose and purchase different types of hardware that best fit a particular project's needs.
Scalability
Thanks to shared-nothing architecture, where all nodes are independent, Hadoop clusters are easy to scale without stopping the entire system, both vertically and horizontally.
In the former case, you increase the capacity of separate machines by adding CPU or RAM. In the horizontal scenario, you expand the existing cluster with new machines and make them work in parallel. Hadoop 3 allows the addition of more than 10,000 data nodes in a cluster.
Versatility
Hadoop allows you to gather data from disparate sources and in various forms — both structured and unstructured, including images, texts, audio and video files, and more. You store all the information in HDFS without pre-processing and decide on the schema to apply to it later. Due to the “write once, read many times” principle, the same dataset can be modeled again and again, depending on the use case.
Compatibility with multiple file systems and processing engines
Besides the native HDFS, Hadoop is compatible with many other storage services and file systems, including FTP file systems, Amazon S3, and Azure Storage. Hadoop 3 expanded this list with Microsoft Azure Data Lake and Aliyun Object Storage System.
Also, as we mentioned before, Hadoop works with various processing engines. So, you can combine HDFS with Apache Spark or computing technologies of your choice instead of MapReduce.
Fault tolerance
The framework is praised for its exceptional fault tolerance. If an individual node goes down, the job is reassigned to another machine and the entire cluster continues to work as usual.
When it comes to preventing data loss, the protection mechanism varies across the Hadoop versions. Hadoop 2 achieves fault tolerance by automatically replicating information three times in different nodes. The downside of this approach is that it creates a 200 percent waste of storage space and network bandwidth.
The third version of the framework supports erasure coding — the fifty-year-old method that appeared to be smart enough for new-age technologies. It generates additional data segments and stores them across different locations. In case of corruption or failure, the data can be restored from those segments. Erasure coding cuts the disk usage in half if compared to the triple replication and saves customers money on the hardware infrastructure.
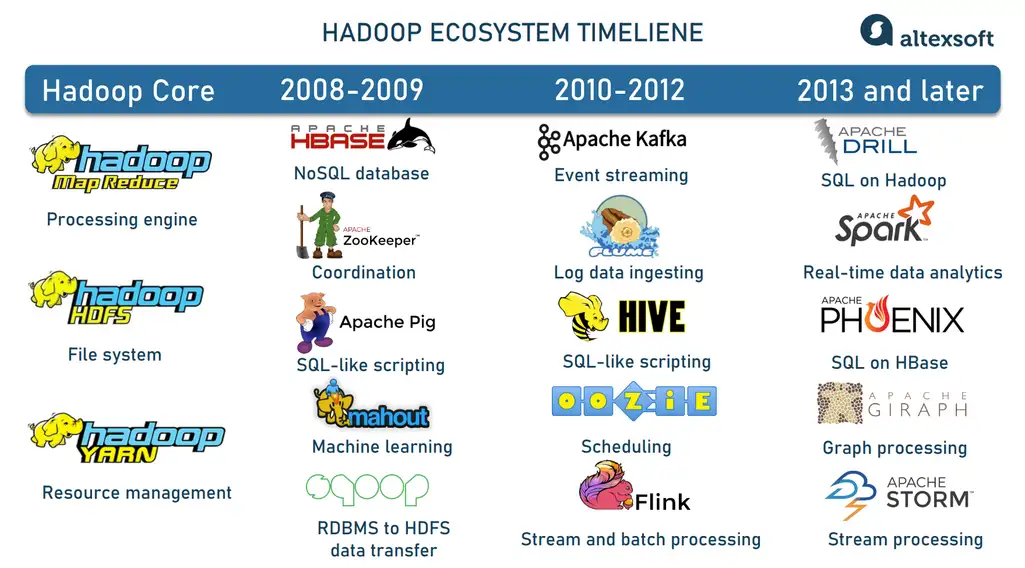
Hadoop ecosystem
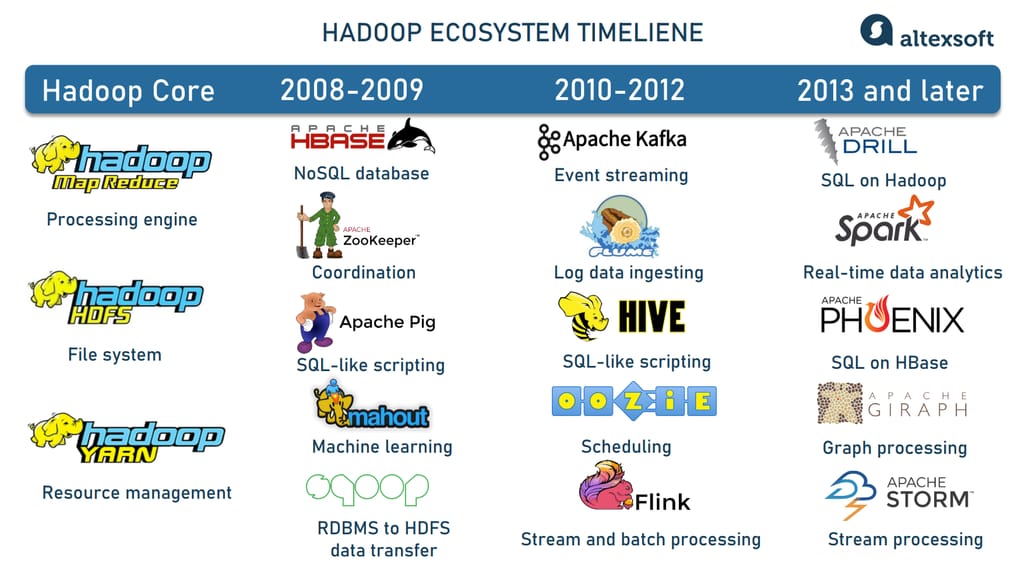
Apache Hadoop is not limited to its three core elements — HDFS, MapReduce, and Yarn. Its open-source nature and modularity attract many contributors who have been working on projects related to Hadoop and enhancing its capabilities. As a result, today we have a huge ecosystem of interoperable instruments addressing various challenges of Big Data.
Hadoop ecosystem evolvement.
On top of HDFS, the Hadoop ecosystem provides HBase, a NoSQL database designed to host large tables, with billions of rows and millions of columns.
To facilitate data ingestion, there are Apache Flume aggregating log data from multiple servers and Apache Sqoop designed to transport information between Hadoop and relational (SQL) databases.
Apache Pig, Apache Hive, Apache Drill, and Apache Phoenix simplify Big Data exploration and analysis allowing for using SQL and SQL-like query languages, familiar to most data analysts. All these tools natively work with MapReduce, HDFS, and HBase.
Instruments like Apache ZooKeeper and Apache Oozie help better coordinate operations, schedule jobs, and track metadata across a Hadoop cluster.
This is by far not the full list of Apache projects. You are welcome to explore them yourself to find the right instruments for your requirements and for data engineering of any complexity.
How data engineering works under the hood.
Robust community
In terms of the community size, Hadoop can hardly compete with top programming languages or web technologies. Yet, its pool of supporters definitely stands out if compared with other Big Data platforms. Hadoop is on the 2022 StackOverflow list of the most popular frameworks and libraries in different domains. Two other most-wanted Big Data instruments — Apache Kafka and Apache Spark — belong to the same ecosystem.
This level of popularity means that you can always find answers to your questions about Hadoop tools or just communicate with other fans of the ecosystem via the StackOverflow, Reddit, or Cloudera community which is a meeting point of Hadoop developers.
Hadoop as a service
Today, companies have the opportunity to run Big Data analytics on Hadoop without investing in hardware. This became possible thanks to Hadoop as a service (HaaS) providers. They enable you to access the framework functionality in the cloud, typically charging fees per cluster/ per hour.
Those who consider HaaS rather than on-premises deployment can opt for:
Amazon EMR (former Amazon Elastic MapReduce), handling large-scale data processing jobs and machine learning applications with open-source Big Data frameworks such as Hadoop, Spark, and Hive;
Dataproc, a managed Hadoop and Spark platform by Google, integrated with other Google Cloud services. It lets you run MapReduce and Spark jobs on data kept in Google Cloud Storage (instead of HDFS); or
Oracle Big Data Service, offering customers a fully-managed Hadoop environment in the cloud.
There are other HaaS vendors as well. Besides Hadoop software and infrastructure needed to deploy it, they often provide cluster management and data migration services, customizable dashboards, and additional security features.
Hadoop disadvantages
Now, after so much praise, it’s time to look at the dark side of Hadoop. None of its disadvantages is a big deal if you just experiment with the technology. But in production, barely noticeable flaws may grow into serious business problems. So, better consider key Hadoop limitations and whether you can be reconciled with them from the very beginning.
Small file problem
Hadoop was initially designed with big datasets in mind, but it’s not suitable for handling a big number of small files. As we mentioned before, the default block size in HDFS is 128 MB. You can change this parameter manually but the system won’t be able to effectively deal with myriads of tiny data pieces. Let’s see why.
First, a NameNode (master node of HDFS) allocates 150 kb of memory space to record metadata on each block stored in the HDFS — no matter its size.
Say, you have a dataset of 1 GB. If you divide it by 128 MB, you’ll have 8 data blocks. But if your targeted size is 1 MB, the splitting will produce 1024 files. Now consider the blocks of 100 KB or so: There will be ten thousand of them each occupying their share of memory in the NameNode. At some point, the task stops being feasible.
Second, HDFS is tuned to read big datasets but isn’t effective in searching and retrieving small files.
Third, slave nodes of MapReduce process only one input at a time — be it a chunk of 128 MB or 128 KB. If you have millions of small files, it will take an eternity to analyze them.
Solution. There are different ways to address the small file problem. The most obvious one is to merge small pieces into a single sequence file under the same name. You can also take advantage of the HAR (Hadoop Archives) command that packs tiny files into larger chunks. In this case, MapReduce runs jobs on the entire package. Yet, all these steps need additional time and effort.
Low speed and no real-time data processing
MapReduce performs batch processing only: It reads a large file and analyzes it following predefined instructions. Such an approach works great for huge volumes of information, yet it takes quite a while to produce the output.
Note that MapReduce can’t cache results. Instead, it retrieves data from HDFS and writes outputs back to the HDFS at both stages of processing — map and reduce. This makes Hadoop slower than other Big Data frameworks. And though Hadoop 3 is 30 percent faster than the second version, it still lags behind engines that support caching and in-memory computation (e.g. Spark).
Anyway, if you work with real-time analytics and your business depends on how fast you get insights for decision-making, Hadoop will hardly meet your expectations.
Solution. You may use Apache Kafka to ingest live data streams and Apache Spark, Apache Storm, or Apache Flink to process them in real or near real time. By the way, Spark supports batch workloads as well but executes jobs 10 to 100 times faster than MapReduce.
Overall complexity and challenging learning curve
The most common language for data analysis is SQL but barebone Hadoop doesn’t support it. Developers, data engineers, data analysts, and other experts must code in Java to interact directly with HDFS, write jobs for MapReduce, and use its capabilities effectively.
Solution. Tools like Apache Pig, Apache Hive, and Apache Drill hide the complexities of Hadoop, enabling you to employ SQL and SQL-like languages for manipulations with data.
There are also interfaces that allow you to access Hadoop, analyze data, and program for it in other languages. This includes Pydoop for Python, RHadoop for R, and Hadoop Pipes for C++, to name just a few.
Hadoop tutorials and courses
If you want to jump into Big Data engineering or introduce Big Data technologies to your company, mastering Hadoop is essential. So, how to tame the elephant?
Helpful skills
No one can expect you or one of your employees to become a Hadoop expert in a couple of days. Yet, the learning process will be significantly shorter if you already have a set of certain technical skills — namely
Knowledge of the Linux operating system. It’s a preferred OS for Hadoop installation;
Programming. Expertise in any programming language will make learning Hadoop easier. Yet, since the framework is written in Java, it’s the number one option to know — at least, at the basic level. If you’re going to create applications for the Hadoop ecosystem, get familiar with Scala, which is the default language of Apache Spark. Python and R are essential for data analysts; and
SQL. As we said, Hadoop doesn’t natively support SQL. But numerous SQL engines over the framework make accessing and analyzing Big Data much easier. So, hands-on experience with SQL commands is a must-have to work with Apache Hadoop.
Once you’ve acquired all the above-mentioned capabilities, the next step will be mastering Hadoop and getting certification.
To prove your skills, you may take a certification exam, maintained by Cloudera, a large data platform and the best-known player in the Hadoop space. It enables you to verify your capabilities as a Spark and Hadoop Developer, Data Analyst, and Administrator managing the Hadoop environment.
Hadoop alternatives, or is Hadoop dead?
Definitely, not. Today, Hadoop which combines data storage and processing capabilities remains a basis for many Big Data projects. Many additional instruments are running over HDFS, MapReduce, or both, expanding their functionality.
But businesses are constantly looking for newer and more effective technologies outside the Hadoop ecosystem. Here are some options to consider.
MongoDB: an NoSQL database with additional features
MongoDB is the leading NoSQL platform created to enhance relational database management systems with the ability to accept data in any form. It can store huge amounts of information and also provides a number of additional services like data encryption, advanced real-time analytics, and data lakes. At the same time, it can hardly compete with Hadoop in batch processing and complex ETL jobs.
Snowflake: an evolving ecosystem for all types of data
A cloud-native data platform, Snowflake comprises a data warehouse suitable for massive sets of structured and semi-structured data, a powerful SQL query engine, and a set of additional services — such as authentication, access control, metadata and infrastructure management, and more.
In September 2021 Snowflake announced the public preview of the unstructured data management functionality. Since then, the ecosystem for this type of data has been constantly growing. Yet, for now, it can’t totally replace all that Hadoop has to offer.
Cloudera: commercial implementation of Hadoop
Cloudera is a leading vendor of Hadoop-based software. It complements the free framework with commercial tools and technologies. The platform has Cloudera Search for real-time indexing and full-text search in Hadoop (the open-source analog is Apache Solr), Cloudera Navigator for data governance, and Impala for SQL data querying.
Google Cloud Platform: a relative of Apache Hadoop
On close inspection, Big Data offerings by Google Cloud Platform strongly resemble Hadoop instruments, and for a reason. HDFS was initially inspired by the Google File System. It was Google that developed MapReduce in 2003 for a range of data analytics tasks and later open-sourced it. Now, Google abandoned MapReduce in favor of the more scalable framework — Cloud Dataflow which supports both batch and stream workloads and can be compared to Apache Spark.
Apache HBase mimics the concept of Google Cloud BigTable. And Apache Hive in a way is a sibling of Google Cloud BigQuery: Both enable SQL querying and analyzing extremely large datasets.
However, unlike Apache instruments, Google products are not free of charge. The same refers to other alternatives. So, in a way, Hadoop remains unique and indispensable.