November 22, 2023 | Blog, Data Analysis
Check out the latest blog by Our Senior Consultant Howard Hill where he offers an engineer’s guide to streamlining real-time data using an open-model infrastructure.

This post is a getting-started guide intended to assist engineers in setting up an open model infrastructure for real-time processing.
Data is established as the driving force behind many industries today, and having a modern data architecture is pivotal for organizations to be successful. One key component that plays a central role in modern data architectures is the data lake, which allows organizations to store and analyze large amounts of data cost-effectively and run advanced analytics and machine learning (ML) at scale.
Here at OpenCredo we love projects that are based around Kafka and/or Data/Platform Engineering; in one of our recent projects, we created an open data lake using Kafka, Flink, Nessie and Iceberg. The first part of this blog is related to the Flink and S3 infra design.
Apache Flink is designed for distributed streams and batch processing, handling real-time and historical data. Flink integrates well with the Hadoop or Presto ecosystem, allowing it to leverage its distributed storage systems like HDFS or AWS S3, for example as the storage engine.
Flink is great at data processing for streaming data, providing low-latency performance and advanced windowing functions and has evolved from version 1.4 to 1.17 to now include a Kubernetes Operator. This makes it considerably easier to manage jobs and tasks.
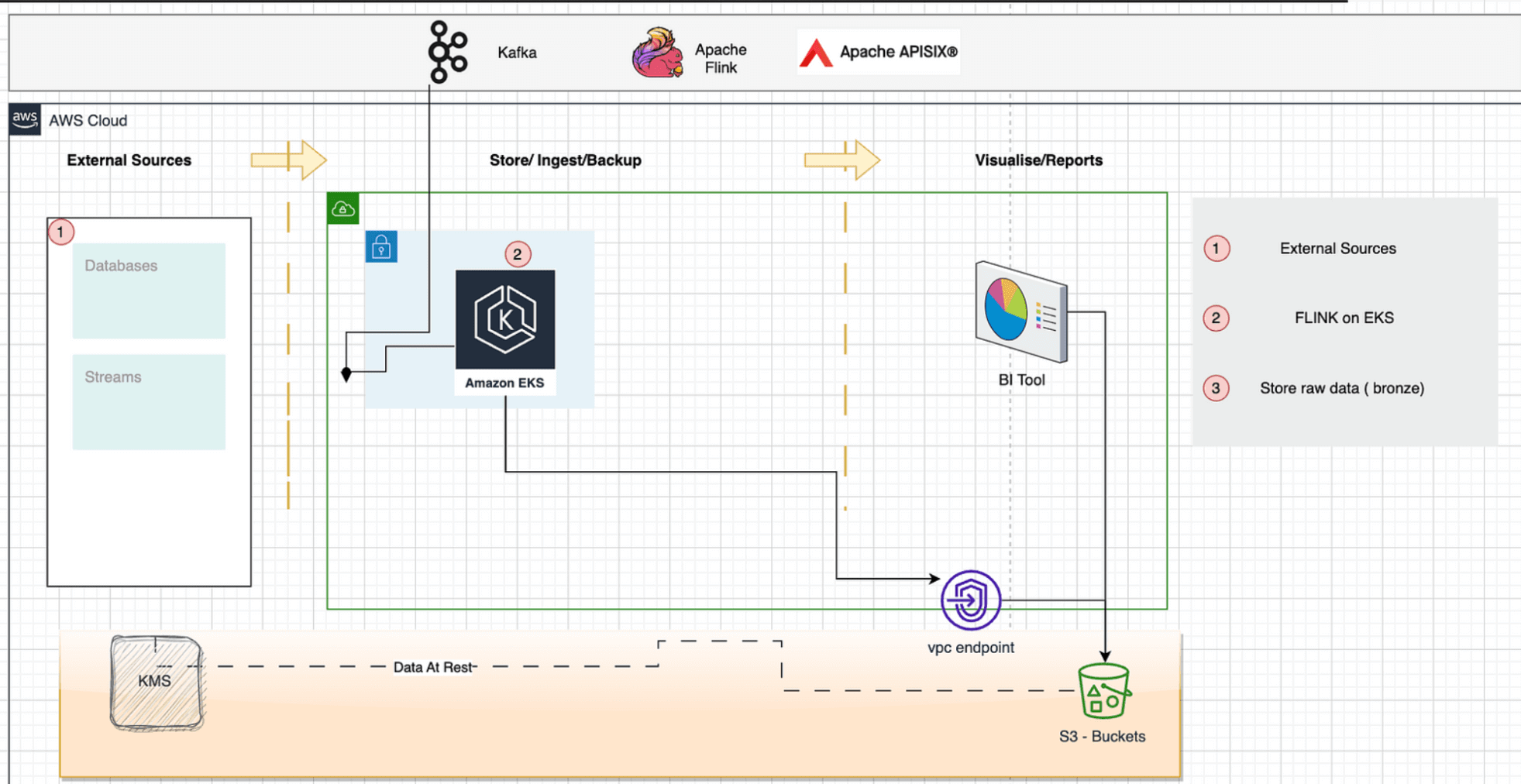
Our data lake is a medallion architecture for this solution, with each bucket having a bronze, silver and gold folder. We provisioned it using Terraform.
Terraform was orchestrated using a Terragrunt format to handle multiple tenants. A tenant is the owner of the data. The main acceptance criteria are to classify the data and segment it by region; security is enabled by Virtual Private Network (VPC) or VPCe for access to the buckets. We expect applications to be deployed in a VPC, in this case, EKS, which runs Flink apps.
terraform {
source = "git::git@github.com:opencredo/terraform-modules.git//s3_datalake"
}
inputs = {
region = local.environment_vars.region_name #eu-west
tenant_id = "897823709432" #some randomized id
data_classification = ["GDPR"]
account_id = "614871886104" #aws account
vpc_ids = "\"vpc-18d8eee21dfcf1807\", \"vpc-0a4e76cf16be657664\""
# can be vpc data resource by tags as well instead of ids
tags = merge(local.common_vars.tags, {
workload = "datalake"
environment = local.environment_vars.environment_name
})
}Apache Flink can be set up in various ways, and I chose the Deployment Job and Session Job using the Kubernetes Operator.
The Deployment Job — uses a local jar that is part of the Flink Docker image, not the operator that runs locally. The Session Job — supports a remote file system that can download files from S3, https, etc.
Now, you could skip all of this and deploy it via the Flink image and forget about the operator, but I didn’t choose that option for the following reasons:
The Flink Kubernetes Operator allows you
The first issue is that if you want to allow S3 integration, the plugins for Hadoop or Presto are required; now, this is required because the operator downloads the jar, and you want to store the state in s3.
job:
jarURI: s3://897823709432-eu-west-datalake/jars/storekafkatopicsinlake.jarThe Flink filesystem allows just copying the jar, so I used the helm values postStart like this.
postStart:
exec:
command:
- "/bin/sh"
- "-c"
- |
wget -O /opt/flink/plugins/flink-s3-fs-presto-1.17.1.jar \
https://repo1.maven.org/maven2/org/apache/flink/flink-s3-fs-presto/1.17.1/flink-s3-fs-presto-1.17.1.jar
wget -O /opt/flink/plugins/flink-s3-fs-hadoop-1.17.1.jar \
https://repo1.maven.org/maven2/org/apache/flink/flink-s3-fs-hadoop/1.17.1/flink-s3-fs-hadoop-1.17.1.jar
operatorPod:
env:
- name: FLINK_PLUGINS_DIR
value: /opt/flink/plugins
- name: ENABLE_BUILT_IN_PLUGINS
value: "flink-s3-fs-presto-1.17.1.jar"This did not work, I believe the classloader is run before the start of postStart, which is why it’s not picked up, so a custom image needed to be built in Docker to allow the packages to be stored, which is also of benefit because it means the host doing the deployment doesn’t need direct access to the internet, which can be tricky if you’re deploying via a bastion host or similar within an existing K8S cluster.
#apps-flink-operator-with-s3presto
FROM apache/flink-kubernetes-operator
# Download the S3 Presto plugin
RUN mkdir -p /opt/flink/plugins/s3-fs-presto
RUN wget https://repo1.maven.org/maven2/org/apache/flink/flink-s3-fs-presto/1.17.1/flink-s3-fs-presto-1.17.1.jar -O /opt/flink/plugins/s3-fs-presto/flink-s3-fs-presto-1.17.1.jar
# Set the environment variable to enable the plugin
ENV ENABLE_BUILT_IN_PLUGINS=flink-s3-fs-presto-1.17.1.jarThe Helm Values File uses ArgoCD sync, which deploys the K8s Operator using a service account in AWS with policy access to the specific bucket.
app: flink-kubernetes-operator
# language=yaml
version: |
image:
repository: "ghcr.io/opencredo/apps-flink-operator-with-s3presto"
pullPolicy: IfNotPresent
tag: "main"
defaultConfiguration:
create: true
# Set append to false to replace configuration files
append: true
flink-conf.yaml: |+
parallelism.default: 4
kubernetes.operator.podAnnotations:
owner: oc-team
s3.iam-role: arn:aws:iam::614871886104:role/flink-dev
s3.endpoint: s3.eu-west-2.amazonaws.com
s3.region: eu-west-2
high-availability: org.apache.flink.kubernetes.highavailability.KubernetesHaServicesFactory
high-availability.storageDir: s3://897823709432-eu-west-datalake/state/flink-ha
state.checkpoints.dir: s3://897823709432-eu-west-2-datalake/state/checkpoints
state.savepoints.dir: s3://897823709432-eu-west-2-datalake/state/savepointsTip: Here are some key differences between Flink deployment and session jobs when using the Flink operators on Kubernetes.
Deployment Jobs:
Advantages
Disadvantages:
Session Jobs:
Disadvantages:
For our project, lakes by tenant (i.e. A multi-tenant Lakehouse) need to have a lifecycle policy to move data from bronze to gold, which we will go into the next article, but what we have achieved so far is a quick start guide to set the S3 bucket with prefixes for bronze and tailor that with policies for EKS integration running Apache Flink which stores the state in S3.
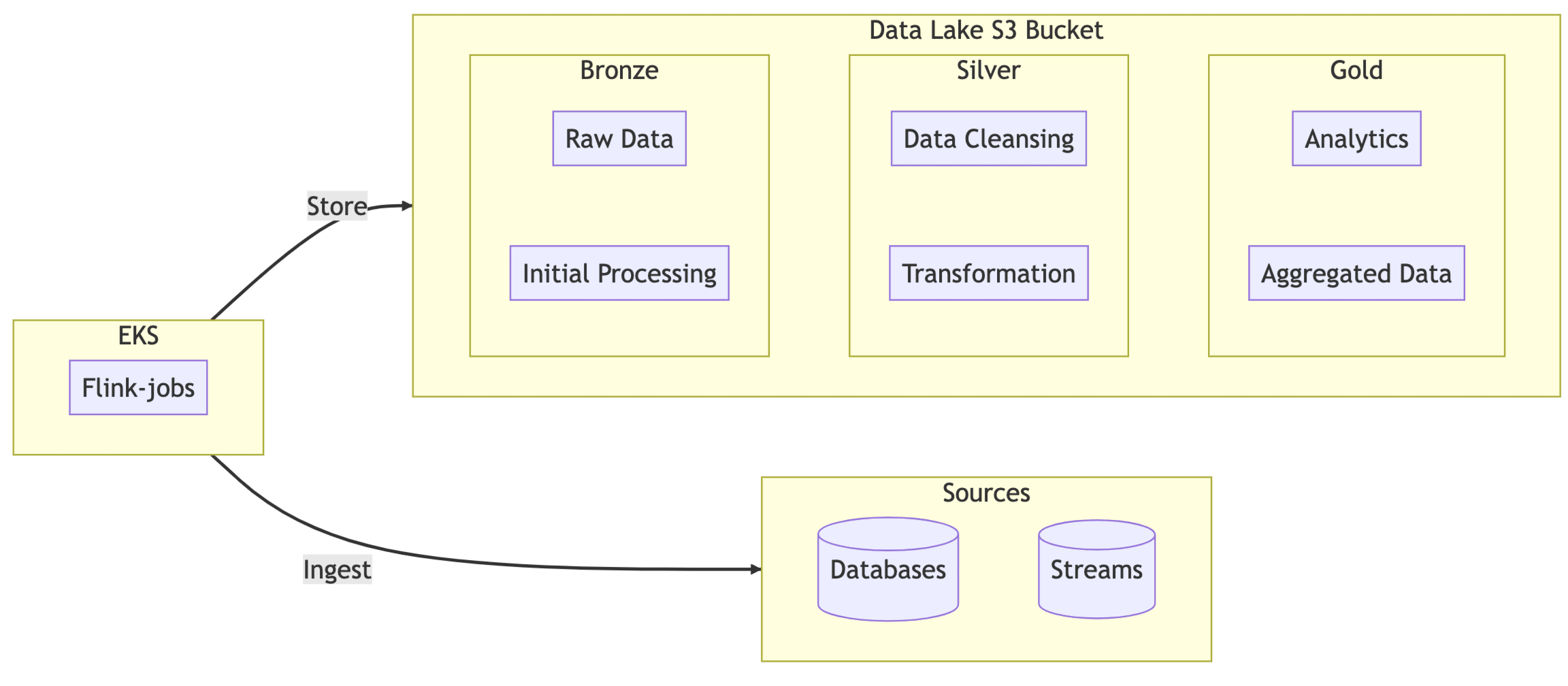
Kafka Topic ──> Apache Flink App ──> AWS S3 Bucket (Bronze Folder)
---
apiVersion: flink.apache.org/v1beta1
kind: FlinkSessionJob
metadata:
name: inv-job-1
spec:
deploymentName: oc-inventory-session-deployment-fdeploy
job:
jarURI: s3://897823709432-eu-west-2-datalake/jars/oc-inventory-app.jar
parallelism: 4
upgradeMode: statelessUse Case Design: This Flink Application reads data for every computer inventory to check compliance in multiple organisations. Each computer inventory is uploaded to a Topic via a Rest API. The data platform ingress sources this and handles the Medallion structure from bronze to gold.
In this article, we have outlined the technology choices behind our Flink implementation on Kubernetes and some of the configurations required to create an effective deployment for a Medallion data stack running on AWS. In the next part, we’ll dig a bit deeper into the metadata management in the data lake and how to deploy it.

We go into using Kustomize with Flink, the terraform setup for metadata management, policies, and EKS compute tolerations.
Use Case Solution
This blog is written exclusively by the OpenCredo team. We do not accept external contributions.
SHARE





Platform Engineering Day Europe 2024 – Maturing Your Platform Engineering Initiative (Recording)
Watch the recording of our CEO/CTO, Nicki Watt from the KubeCon + CloudNativeCon 2024 on her talk “To K8S and Beyond – Maturing Your Platform…
GOTO Copenhagen 2023 – The 12 Factor App For Data (Recording)
Watch the recording of our Technical Delivery Director, James Bowkett from the GOTO Copenhagen 2023 conference for his talk ‘The 12 Factor App For Data’
The 2023 Mayor’s Business Climate Challenge (BCC) – Final Part
Learn more about our efforts and our progress towards becoming an environmentally friendly company for the Mayor’s Business Climate Challenge (BCC) in 2023 in this…