
This sounds like a question a programmer might ask after one medicinal cigarette too many. The computer science equivalent of “what is the sounds of one hand clapping?”. But it is a question I have to decide the answer to.
I am adding indexOf() and lastIndexOf() operations to the Calculate transform of my data wrangling (ETL) software (Easy Data Transform). This will allow users to find the offset of one string inside another, counting from the start or the end of the string. Easy Data Transform is written in C++ and uses the Qt QString class for strings. There are indexOf() and lastIndexOf() methods for QString, so I thought this would be an easy job to wrap that functionality. Maybe 15 minutes to program it, write a test case and document it.
Obviously it wasn’t that easy, otherwise I couldn’t be writing this blog post.
First of all, what is the index of “a” in “abc”? 0, obviously. QString( “abc” ).indexOf( “a” ) returns 0. Duh. Well only if you are a (non-Fortran) programmer. Ask a non-programmer (such as my wife) and they will say: 1, obviously. It is the first character. Duh. Excel FIND( “a”, “abc” ) returns 1.
Ok, most of my customers, aren’t programmers. I can use 1 based indexing.
But then things get more tricky.
What is the index of an empty string in “abc”? 1 maybe, using 1-based indexing or maybe empty is not a valid value to pass.
What is the index of an empty string in an empty string? Hmm. I guess the empty string does contain an empty string, but at what index? 1 maybe, using 1-based indexing, except there isn’t a first position in the string. Again, maybe empty is not a valid value to pass.
I looked at the Qt C++ QString, Javascript string and Excel FIND() function for answers. But they each give different answers and some of them aren’t even internally consistent. This is a simple comparison of the first index or last index of text v1 in text v2 in each (Excel doesn’t have an equivalent of lastIndexOf() that I am aware of):

Changing these to make the all the valid results 1-based and setting invalid results to -1, for easy comparison:
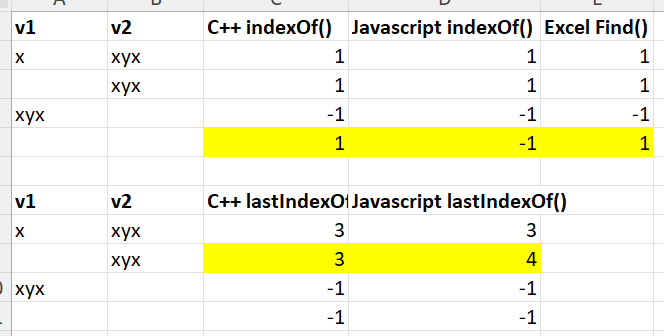
So:
- Javascript disagrees with C++ QString and Excel on whether the first index of an empty string in an empty string is valid.
- Javascript disagrees with C++ QString on whether the last index of an empty string in a non-empty string is the index of the last character or 1 after the last character.
- C++ QString thinks the first index of an empty string in an empty string is the first character, but the last index of an empty string in an empty string is invalid.
It seems surprisingly difficult to come up with something intuitive and consistent! I think I am probably going to return an error message if either or both values are empty. This seems to me to be the only unambiguous and consistent approach.
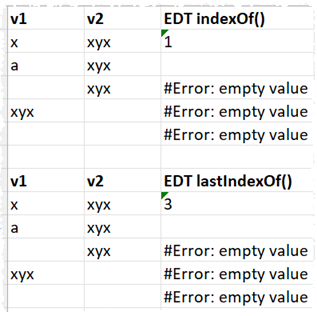
I could return a 0 for a non-match or when one or both values are empty, but I think it is important to return different results in these 2 different cases. Also, not found and invalid feel qualitatively different to a calculated index to me, so shouldn’t be just another number. What do you think?
*** Update 14-Dec-2023 ***
I’ve been around the houses a bit more following feedback on this blog, the Easy Data Transform forum and hacker news and this what I have decided:
IndexOf() v1 in v2:
| v1 | v2 | IndexOf(v1,v2) |
|---|---|---|
| 1 | ||
| aba | ||
| aba | 1 | |
| a | a | 1 |
| a | aba | 1 |
| x | y | |
| world | hello world | 7 |
This is the same as Excel FIND() and differs from Javascript indexOf() (ignoring the difference in 0 or 1 based indexing) only for “”.indexOf(“”) which returns -1 in Javascript.
LastIndexOf() v1 in v2:
| v1 | v2 | LastIndexOf(v1,v2) |
|---|---|---|
| 1 | ||
| aba | ||
| aba | 4 | |
| a | a | 1 |
| a | aba | 3 |
| x | y | |
| world | hello world | 7 |
This differs from Javascript lastIndexOf() (ignoring difference in 0 or 1 based indexing) only for “”.indexOf(“”) which returns -1 in Javascript.
Conceptually the index is the 1-based index of the first (IndexOf) or last (LastIndexOf) position where, if the V1 is removed from the found position, it would have to be re-inserted in order to revert to V2. Thanks to layer8 on Hacker News for clarifying this.
Javascript and C++ QString return an integer and both use -1 as a placeholder value. But Easy Data Transform is returning a string (that can be interpreted as a number, depending on the transform) so we aren’t bound to using a numeric value. So I have left it blank where there is no valid result.
Now I’ve spent enough time down this rabbit hole and need to get on with something else! If you don’t like it you can always add an If with Calculate or use a Javascript transform to get the result you prefer.
*** Update 15-Dec-2023 ***
Quite a bit of debate on this topic on Hacker News.

I recall that in Ada (for which arrays are typically indexed starting from 1, but can be changed), index of an item returns 0 if there’s no item found.
And does it also return 0 is either or both the strings are empty?
Unless I misunderstand your goal:
I believe that “empty string” is, in essence, not a string but a boolean.
A string is either empty or not.
So looking for an empty string in “abc” is like looking for a NO in YES. And looking for an empty string in an empty string is like looking for a NO in NO.
I’m sure you’ll get much smarter replies from other developers soon.
I consider an empty string to be a string and different to a boolean.
Oh yeah, it’s definitely formally a string.
It’s just an empty string is an entity by itself, it cannot be a part of a non-empty string. We can only check if a string is empty or not. That is, a boolean check.
That’s at least my understanding.
To quote a commenter from hackernews
“`
The subset relation is defined as “X is a subset of Y if for all x in X, x is in Y”. The negation of this is “X is not a subset of Y if there exists some x in X, such that x is not in Y”. We can see from this that the empty set is NOT NOT a subset of every set. Therefore the empty set is a subset of every set.
“`
So every valid index position within a string /should/ also be a valid index for an empty string within that string. A function to return the index of the empty string should define its own semantics of the return value, but it would be typical to return the lowest index of the provided substring, which would always be 0. Likewise if the function’s semantics were defined as returning an array if indices for every occurrence of the substring, an empty substring should return an array that contains every valid index of the string being checked.
Seems there is a difference in the QString implementation and std C++ (string::find)
Running the below (sorry about formating):
int main() {
std::string s = “123”;
auto i = s.find(“”);
std::cout << s << ":" << i << std::endl;
return 0;
}
Outputs:
123:0
So vanilla C++ assumes the empty string is found at the beginning of any string?
if you look at the first image you will see that QString and Javascript strings also return 0 (I added 1 for easy comparison with Excel in the later image).
I would say these are corner cases. Like in math dividing a zero by a zero, or converting 1.5 to an integer. What is the correct result? 1 or 2? …. 0 divided by 0 is infinite? or it is zero?
It is up to the programmer implementing the code to choose the correct result between the many that could be considered correct.
[assuming zero-based indexing]
return -1 (not found) if empty string is passed to the function (i.e. v2 is empty). Seems preferable to say an empty string is not found anywhere inside another string to say it occurs at all letter boundaries.
Calling the function ON an empty string is valid but always returns -1 (not found), whatever value passed. On the grounds that empty string is a normal string of zero length. You could argue that the empty string contains an empty string and return 0, but returning an index implies string.length>0 which is not true, and is likely to lead to confusion.
Throwing an error if v2 is null would also be an option.
So:
v1.indexOf(v2)
v1 v2
“” “x” : -1
“” “” : -1
“x” “” : -1
“x” “x”: 0
The position of an empty string is at the start of the string, imo. Or the end if you’re going backwards. It’s a bit of a divide-by-zero case, where you can decide what’s best for you. On one project I’m on, it’s a compiler error if the compiler can detect a constant divine-by-zero, and 20,000 if not. It eliminated a whole category of crashes for us.
In favor of finding “”:
ab in abc is 1. a is 1 as well. Why should this change if we trim off more letters? I think we’re philosophically looking for the start of first sequence that matches the input here. Or at least, doesn’t NOT match – consider how regex works. Therefore, starting at 1, and having no argument against it, 1 is a reasonable return value when looking for “”. Now, if “” is 1 in abc, and in ab, and a, why not “”? Nothing can be found in nothing, after all. It’s the only thing that can.
As for making it an error, separate from not-found? I’d definitely avoid that, because I’d like all my non -matching logic in one branch plz. I don’t usually care why my string wasn’t found, just that it wasn’t.
As I have thought about this more I have come around to the same way of thinking. It seems to be the most internally consistent way to look at it.
pos = s.IndexOf(b) should tell you the first value of pos such that b == a.substr(pos,len=b.length()). Which depends on your substr method. So be consistent with that. Nothing else makes sense to me. “”.substr(0,0)==””-> TRUE so pos is 0.
First, the index is the number of characters you skip over to get to the start of the substring. Ergo zero-based, as in all sensible programming languages.
Second, indexOf should return the minimum index (if one exists) at which the substring occurs within the string, ergo zero for an empty string regardless of the string being searched, as an empty string is a valid substring of any string at any index from zero to the length of the string (inclusive).
Finally, lastIndexOf should return the maximum index at which the substring occurs within the string, ergo the length of the string (i.e., skipping over all the characters in the string) for an empty substring within any string, including the empty string for which the length is zero. Surprisingly JavaScript was the only one to get this right for the case of the empty substring within a non-empty string, though the article called the result “invalid”; Qt did not return the *last* index.
I agree. That is pretty much what I have gone with. But I have used a 1-based index as that is more intuitive to non-prgrammers and it is what Excel FIND() uses. The Qt QString gives some odd results, such as QString( “” ).indexOf( “” ) = 0, but QString( “” ).lastIndexOf( “” ) = -1. And Javascript string returns -1 in both cases. So it seems that Excel is the most consistent!
@Jesse McDonald: “Second, indexOf should return the minimum index (if one exists) at which the substring occurs within the string, ergo zero for an empty string regardless of the string being searched, as an empty string is a valid substring of any string at any index from zero to the length of the string (inclusive).”
I’m sorry but this is incorrect. Strings do NOT contain any empty strings. Zero is the index of the first character of a string. It’s not an index of anything else. If a function returns zero when searching for the index of an empty string, then this function either doesn’t function correctly or its result is wrongly interpreted.
Here on Mac both Objective-C and JavaScript return the correct result when searching for an empty string in a string: “Not found” (NSNotFound, -1 etc.)
Strings can be CHECKED for being empty or not (YES/NO). But empty strings don’t exist within strings. Therefore, an index of an empty strings can never be a valid index.
That’s why, in my view, any string simply must first be checked for being empty – and treated accordingly if it is empty.
@Leo Ravzin: “Strings do NOT contain any empty strings. Zero is the index of the first character of a string. It’s not an index of anything else.”
I’m sorry but this is all incorrect. Strings do contain empty strings. This is easily demonstrated; pretty much every language has a substring or slice operation which can be used to request a substring of length zero at any given index within a string, which will return the empty string. An empty set is a subset of every set, and an empty sequence is a subsequence of every sequence. Strings are just sequences of characters.
Zero is the index of many things, but in this case it’s the index of the substring (empty or otherwise) within the string, or in other words the distance in characters from the start of the string to the start of the substring.
An empty string is merely a string with a length of zero. It’s not some special object which can only be tested to determine whether it’s empty, any more than zero is a special number which can only be tested for equality with zero. In general any operation which works on strings can work on an empty string, provided the preconditions are met. For example to extract a character (a substring with length 1) from a string you need an index which is greater than or equal to zero and strictly less than the length of the string, which is impossible when the length is zero. However the more general substring extraction (slicing) only requires the starting index plus the substring length to be less then or equal to the length of the string, so it works just fine on an empty string so long as the index and substring length are both zero (yielding an empty substring).
Likewise the process of searching for a substring within a string has no constraints which preclude searching for an empty string. The basic unoptimized algorithm is simply this: for each index from zero up to the length of the given string minus the length of the given substring (inclusive) compare the given substring to an equal-length substring extracted from the given string starting at that index. Return the minimum/maximum index where a match was found, or a language-appropriate value indicating failure if there was no match.
The ability to search for, and find, an empty string within any string follows from the fact that an empty substring can be extracted from any string—as described above—at any index from zero to the length of the string, inclusive.
> I’m sorry but this is all incorrect. Strings do contain empty strings.
> This is easily demonstrated; pretty much every language has a substring
> or slice operation which can be used to request a substring of length
> zero at any given index within a string
If you request a substring of length zero it means that you simply don’t request anything from that string. If you don’t request anything then you receive nothing, as expected. It doesn’t mean that this “nothing” (i.e. the returned empty string) actually exists at any given index in the target string.
As a proof, if you attempt to get an index of an empty string, you’ll get an invalid index (i.e., ‘not found’).
And actually that’s exactly why Andy gets this result:
QString( “” ).indexOf( “” ) = 0
It doesn’t mean that there’s anything at the index zero in the source string. The function returns zero because zero is an INVALID INDEX in an empty string.
And that’s why, again, we need to check if a string is empty or not to interpret certain return values correctly (or just skip this string altogether).
> The function returns zero because zero is an INVALID INDEX in an empty string.
QString would return -1 for invalid index. 0 is a valid index. You are free to define QString( “” ).indexOf( “” ) is invalid in your own system, but personally I have decided 0 (0-based) or 1 (1-based) is more consistent.
First, after running some additional tests, I found out that I was wrong in at least one thing: that I get consistent results between languages and methods here.
To elaborate further I’d need to write an lengthy article similar to yours, which sure as hell nobody wants to see.
For example, in JS:
“”.charAt() = “”
while a similar method in Objective-C will produce an exception when using any index, including 0.
So I should paraphrase my earlier conclusion:
The return values achieved when working with empty strings are either invalid OR irrelevant. That is, you won’t know the exact truth by looking at the return value alone.
Which brings me back to what I already mentioned: we simply must know if we deal with an empty string in the first place – and then act accordingly.
I just noticed that text enclosed in angle brackets got helpfully deleted from my post.
What I meant is:
“”.charAt([any index here]) = “”
Honestly, disregarding a lot of the discussion, if you want to define the indexOf of the empty string in for example “abc” to 1, you should absolutely change the name to firstIndexOf. It matches lastIndexOf, and logically makes sense since the empty string appears at index 1,2 and 3 so the name should make it clear that it is the first index that is returned.
Doesn’t really have anything to do with the empty string. If you query for the index of “a” in “aba”, the name of the function should make it clear which index will be returned for multiple hits. Naming functions correctly does matter.