Analytics Engineering | Data Engineering | Data Governance | Data Platforms | dbt | Python | Technology | Topics
dbt + SODA: how to manage your data at scale 
Guillermo Sánchez Dionis 08 Mar, 2022





As data projects and teams grow in complexity and volume, maintaining data integrity becomes increasingly challenging. Making sure changes made in one project don’t affect dependent ones – or even worse, business-critical applications – become even more important. This is where data contracts come into play, providing the tools for ensuring data quality and consistency.
In this article, we will explore the concepts of data contracts and how they can be effectively implemented using dbt.
First, we will quickly dive into the fundamentals of data contracts, which serve as agreements between data producers and consumers. Next, we will get our hands dirty and implement it in dbt, also touching model versioning and constraints. Finally, we will use dbt Cloud to make sure we prevent breaking changes to be implemented, using its CI/CD features.
Imagine a scenario where a data team develops a pipeline to extract, transform, and load customer data from various sources into a centralized data warehouse. Now, let’s say the marketing team relies on this customer data to run targeted campaigns. They expect the data to include attributes like “customer_name“, “email_address“, and “created_date“. However, due to a miscommunication or oversight, the data team changes the data pipeline, causing the customer name field to be renamed as “customer_full_name” in the final dataset.
Without a data contract in place, the marketing team may not immediately notice the change and continue using their existing processes and code that rely on the “customer_name” field. As a result, their processes and campaigns will fail, leading to wasted resources and potentially damaging the company’s reputation.
With a data contract in place, the change in the data pipeline would have triggered an alert or validation error, highlighting the discrepancy between the expected and actual data structure, preventing the issue.
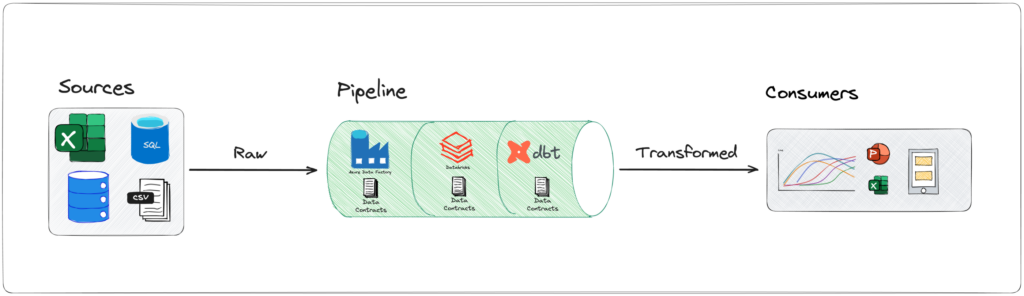
Data contracts, much like an API in software engineering, serve as agreements between producers and consumers. Just as API contracts define the expected behavior, inputs, and outputs of API endpoints, data contracts outline the structure, format, and quality expectations of data and output models. These contracts establish a foundation for building robust and scalable data solutions.
By defining clear data contracts, organizations can avoid data inconsistencies, misinterpretations, and costly errors. By embracing data contracts and versioning, organizations can ensure backward compatibility, reproducibility, and seamless data integration, aligning with the principles of software engineering best practices and avoiding breaking changes.
Now that the concept and (hopefully) its importance is clear, how can we actually implement data contracts, without adding extra complexity to our project, which probably already has a lot of different players in action?
For the past years, dbt is becoming a must-have for data transformation in the Modern Data Stack (and also one of my favorite tools), being a leader in the Analytics Engineer domain. From the release of v1.5, and more recently v1.6, dbt started to focus on multi-project features, as project sizes and complexity are growing fast.
Of course it is not only because you can that you should. However, in this case, it makes sense: the models and business logic rests in your dbt project, therefore the logical place for your contracts definitions and enforcement to be is: your dbt project. This way, you can easily maintain and further develop your data modeling, relying on automated checks instead of only yourself, preventing accidental mistakes.
Enough with the talk, let’s get our hands dirty. Here you can find the repository we are using to set our first contracts in dbt.
First, let’s checkout the branch start-here. There, we have a very simple project, with some staging, intermediate and marts models, and basic documentation.
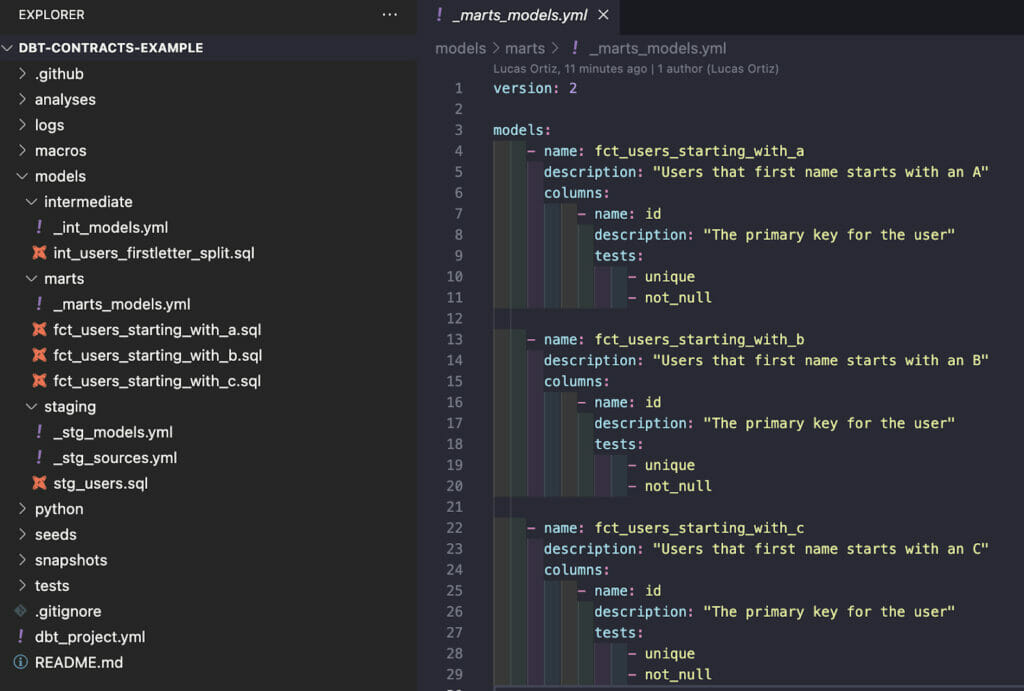
For us to use data contracts enforcement in our dbt project, we must define the name and data_type parameters for every column, as it is still not allowed for “partial” contracts.
Let’s focus on our first marts model. Below you can find the added parameters that were missing.
models:
- name: fct_users_starting_with_a
description: "Users that first name starts with an A"
columns:
- name: id
data_type: int
description: "The primary key for the user"
tests:
- unique
- not_null
- name: first_name
data_type: string
- name: first_name
data_type: string
- name: last_name
data_type: string
- name: email
data_type: string
Once we have all our columns with a defined name and data_type, the next step is to actually include the contract enforcement. It can easily be done by adding the correct parameters to the models file.
models:
- name: fct_users_starting_with_a
config:
contract:
enforced: true
description: "Users that first name starts with an A"
columns:
- name: id
data_type: int
description: "The primary key for the user"
tests:
- unique
- not_null
- name: first_letter
data_type: string
- name: first_name
data_type: string
- name: last_name
data_type: string
- name: email
data_type: string
You can see the code we have so far in the branch contract-enforcement.
For a basic implementation, that’s it! Dbt will now compare your data contract definitions and your actual model, throw an error and not materialize the model if there is any mismatch.
But we are not here for the basics, right?
Two other great features added in the latest versions of dbt are constraints and model versioning.
Constraints are used to perform validations on the model’s output data, before the model is materialized. If a constraint fails, the operation is stopped and all changes rolled back, preventing the model from being updated.
You may ask what is the difference between constraints and tests:
As you can see, they are not mutually exclusive, the best approach is to use both in synergy.
Constraints can be defined both in model-level or column-level. If the constraint refers to one column only, the best approach is to define it in a column-level.
Let’s have a look on how our code will look like with the constraints applied.
models:
- name: fct_users_starting_with_a
config:
contract:
enforced: true
description: "Users that first name starts with an A"
constraints:
- type: check
columns: [first_name, last_name]
expression: "first_name != last_name"
name: first_and_last_name_diff_check
columns:
- name: id
data_type: int
description: "The primary key for the user"
constraints:
- type: not_null
#- type: primary_key # Works on Databricks only if using Unity Catalog (doesn't work for hive_metastore)
tests:
- unique # actually validate uniqueness for this column
- name: first_letter
data_type: string
- name: first_name
data_type: string
- name: last_name
data_type: string
- name: email
data_type: stringYou can see the code we have so far in the branch constraints.
As you can see, we removed the not_null test and replaced it with a constraint, but kept the unique test.
You can find more information about constraints options and enforcements for each data platform on dbt’s official documentation.
dbt Models and the Data model itself evolve over time. How can we make sure we are able to make the necessary changes and improvements, and still not break the applications and pipelines of our consumers?
Versioning is a long-established practice in APIs, and now we can use the same concept with our models. In summary, we should create a new model version whenever implementing a breaking-change intentionally, or when a substantial business logic is being changed in the model. Otherwise, there is no reason to add a version of a model, if the consumers can still use the same model as they used to.
Note that Model versioning is different from Version control, since it is not intended to allow parallel working, or managing conflicting changes.
Now, let’s implement a simple versioning on our model.
First, we will create a duplicate file of our model and add _v2 at the end, in our case, fct_users_starting_with_a_v2.sql – this is the pattern used by dbt to identify the model versions.
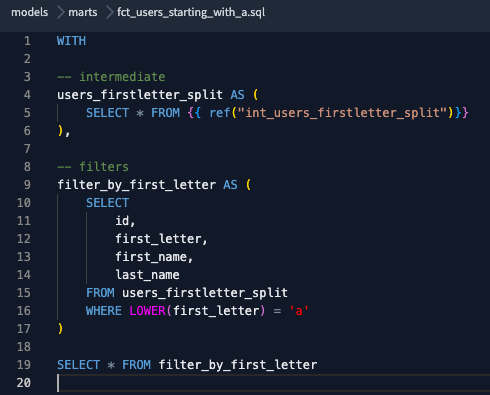
We will rename one of the columns, for example, email → email_address. This change could break some of the downstream consumers who rely on this column, so we will create a new version of this model.
WITH
-- intermediate
users_firstletter_split AS (
SELECT * FROM {{ ref("int_users_firstletter_split")}}
),
-- filters
filter_by_first_letter AS (
SELECT
id,
first_letter,
first_name,
last_name,
email AS email_address
FROM users_firstletter_split
WHERE LOWER(first_letter) = 'a'
)
SELECT * FROM filter_by_first_letterNow back to our .yml, we will add the necessary parameters.
models:
- name: fct_users_starting_with_a
latest_version: 1
config:
contract:
enforced: true
description: "Users that first name starts with an A"
constraints:
- type: check
columns: [first_name, last_name]
expression: "first_name != last_name"
name: first_and_last_name_diff_check
columns:
- name: id
data_type: int
description: "The primary key for the user"
constraints:
- type: not_null
#- type: primary_key # Works on Databricks only if using Unity Catalog (doesn't work for hive_metastore)
tests:
- unique # actually validate uniqueness for this column
- name: first_letter
data_type: string
- name: first_name
data_type: string
- name: last_name
data_type: string
- name: email
data_type: string
versions:
- v: 2
columns:
- include: all
exclude: [email]
- name: email_address
data_type: string
- v: 1
config:
alias: fct_users_starting_with_a
You can see the code we have so far in the branch model-versions.
In summary, we are keeping the first version as the latest, while we test our new version (v2). In the versions parameter, we have to declare the difference between the version and the top-level configs. In this case, we are excluding the column email and adding the column email_address.
This is what you will have once you run your models, with model versions.

There are several more options for defining model versions and deprecating old models, you can find all the relevant information on dbt’s official documentation.
So far, we have configured our schema and contract enforcement, added constraints and model version. However, how can we make sure that if we change a schema and oversight creating a new version, it won’t be a breaking change?
Hopefully, we have dbt Cloud and its CI/CD capabilities to help us. By using the state:modified selector and with our contract enforced, dbt Cloud will keep track of changes in the schema and raise an error if any possible breaking changes is detected and a new version wasn’t created.
The “breaking changes” that dbt Cloud keeps track are:
Note: For this setup, we are considering you already have a dbt Cloud project with multiple Environments set and at least one Job for each Environment, building all the models (dbt build). If you don’t, you can follow the blog posts below to set it up.
Now, let’s open our project in dbt Cloud.
We will create a job that is triggered whenever a Pull Request is opened. This Job should run the necessary tests and validations to ensure that the code changes are ready to be merged into the main branch. The job will build only the modified models and their dependent downstream models.
In this case, we’ll assume that you’re using GitHub as your code repository, but other services like GitLab and Azure DevOps are also supported.
We will name the job “CI preprod” and select the preprod environment.
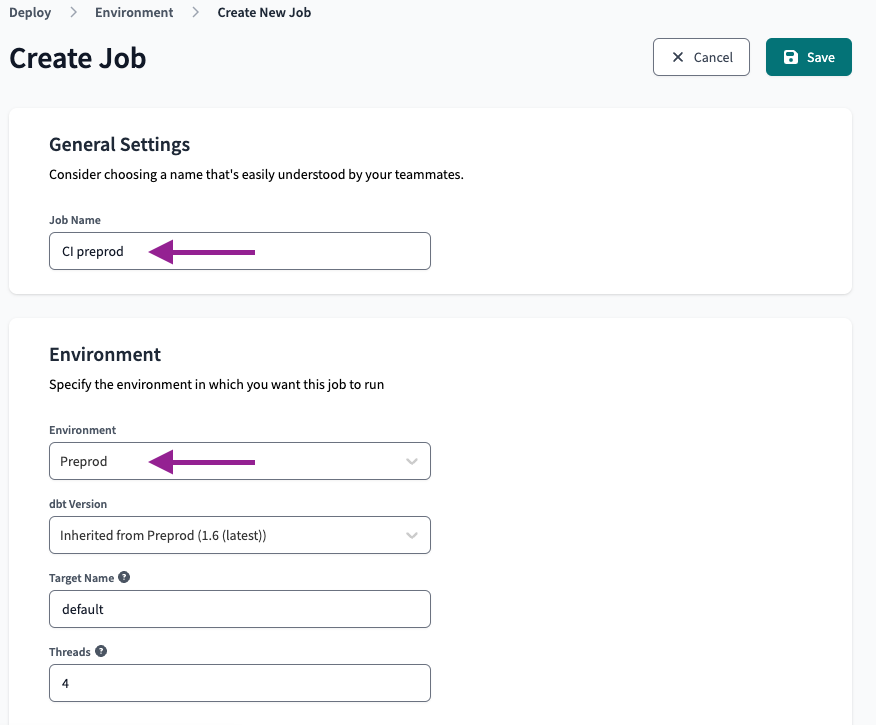
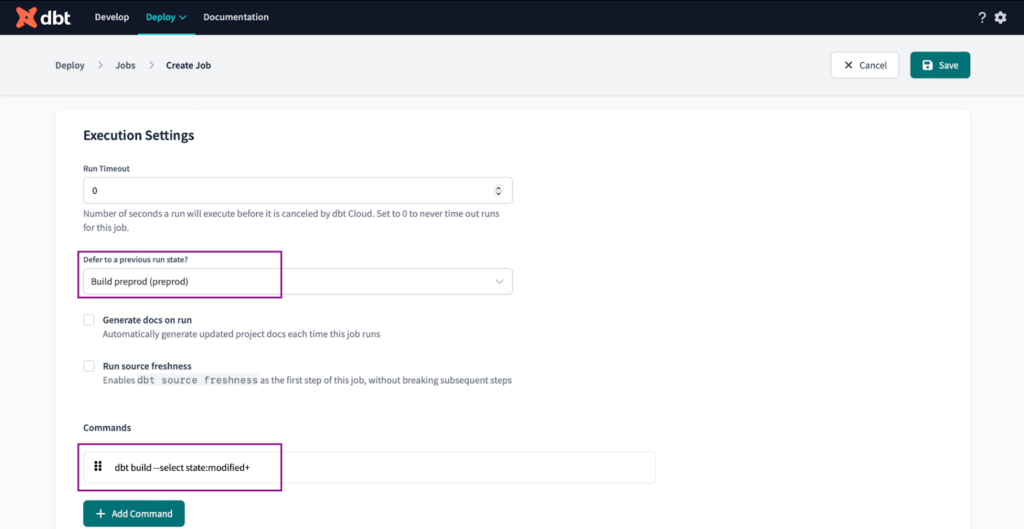
On the Execution settings we set the following:
We execute this command to build only the modified models and their dependent downstream models, which are identified by the ‘+’ symbol at the end of the command.
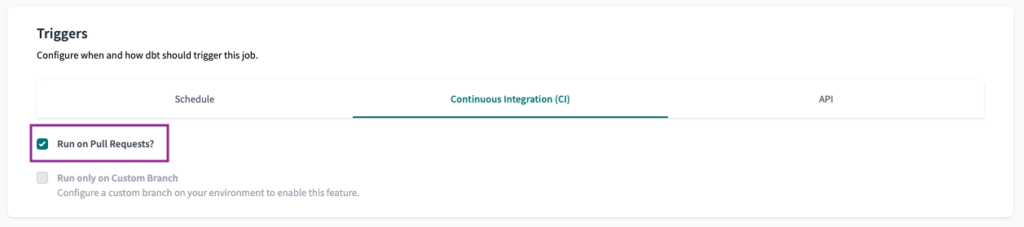
Finally, to set the Continuous Integration (CI) trigger, all we have to do is select the Run on Pull Request? checkbox.
Note: To enable the CI trigger, you must connect your dbt Cloud project with either GitHub, GitLab or Azure DevOps.
We are all set! To test it, first we have to run the Job that builds all the models first (Build preprod in our case), so dbt Cloud creates a manifest to compare the latest changes.
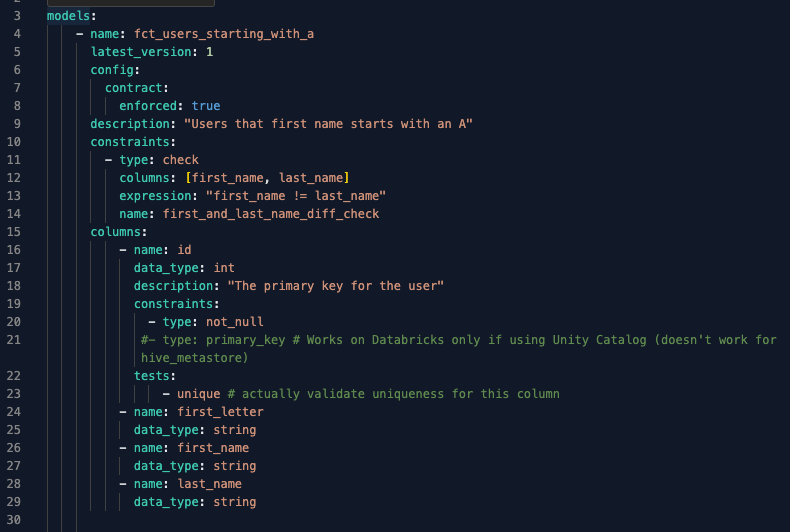
Once it is done, we will create a new branch and insert a breaking change without creating a new version on purpose. In this case, let’s remove the email column, both from the latest version of the model (fct_users_starting_with_a.sql) and from the models .yml file.
Email column removed from the model’s latest version schema definition in the .yml file.
Finally, we will create a Pull Request, which will trigger our CI preprod Job and fail due to a change in the contract.
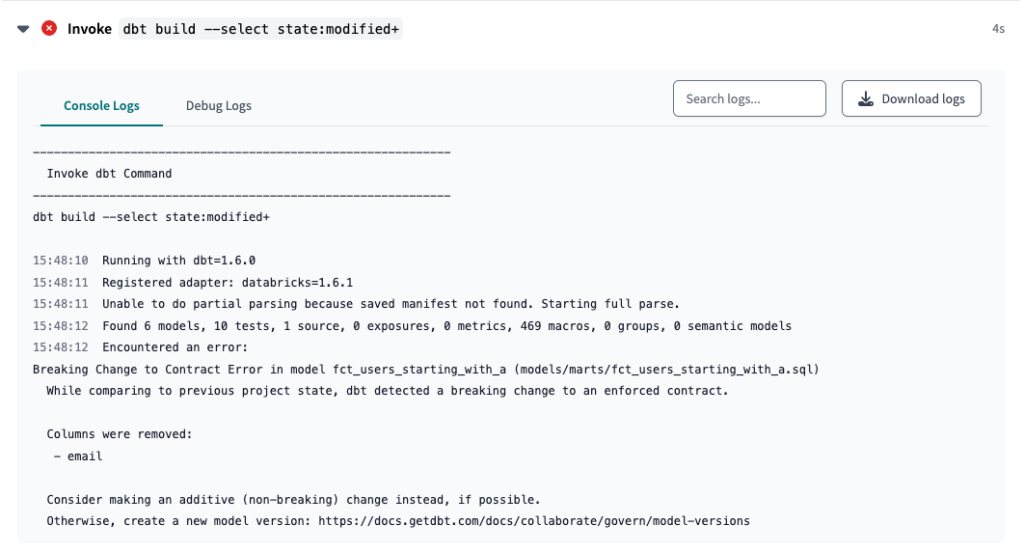
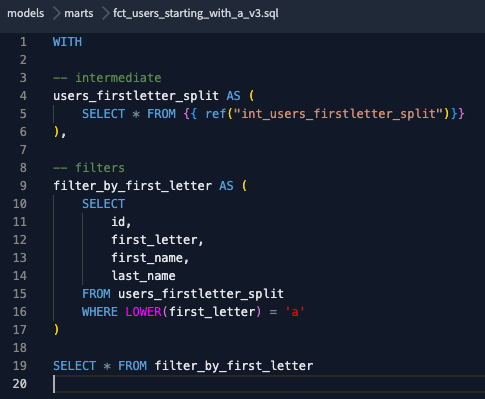
As expected, we have our error! To fix it, we will first create a new version of the model with the change we did, then add the version to the .yml file. Once we commit, the Job will run again and (hopefully) succeed.
New model version (_v3), with the email column removed.
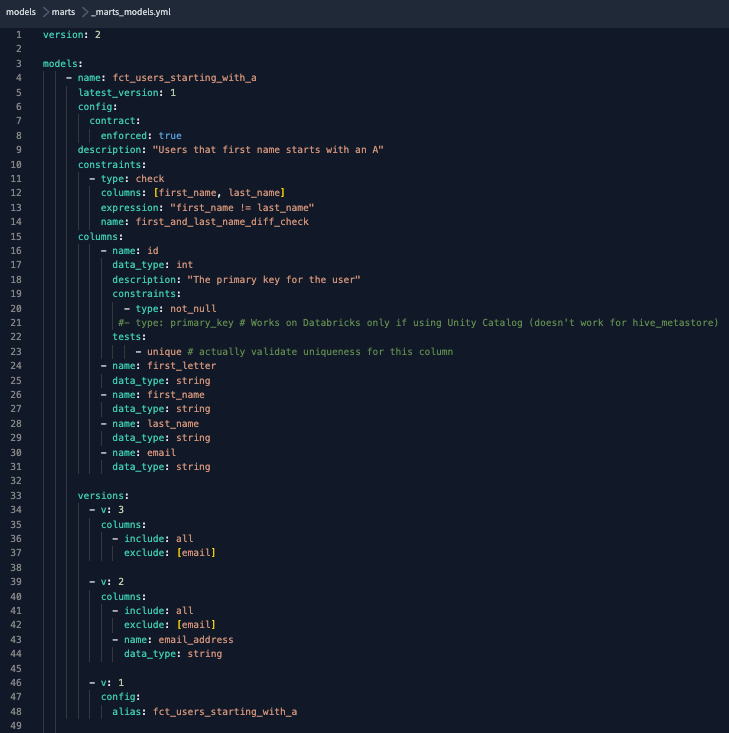
New version added to the .yml file, and email column reinserted into the model’s latest version schema definition.
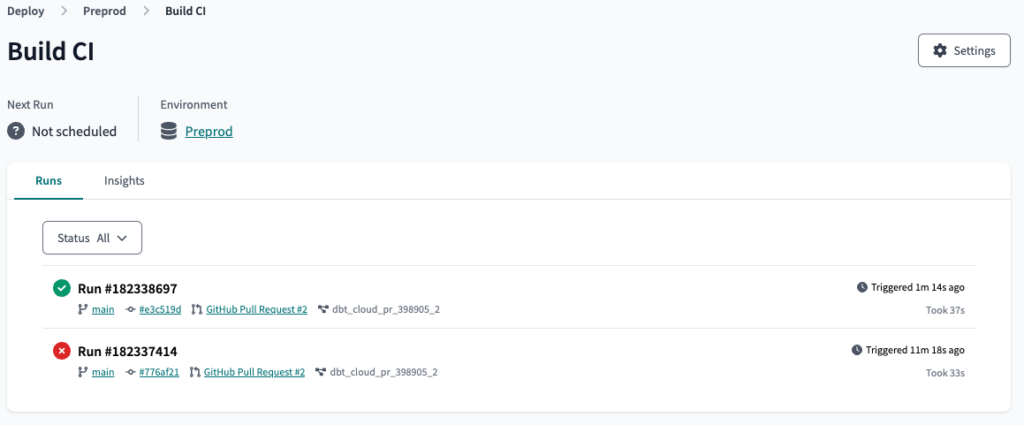
After commiting, the Job will rerun and, this time, succeed.
In the world of data projects and teams, maintaining data integrity is crucial to ensure the quality and consistency of data. By implementing data contracts using dbt, organizations can prevent data inconsistencies, misinterpretations, and costly errors. With dbt’s contract enforcement capabilities, any discrepancies between expected and actual data structures can be highlighted, preventing issues from arising. By embracing data contracts and versioning, organizations can ensure backward compatibility, reproducibility, and seamless data integration. dbt’s features make it a powerful tool for implementing and enforcing data contracts, providing a foundation for building robust and scalable data solutions.
