





In January, Dataiku’s Léo Dreyfus-Schmidt and Reda Affane presented our annual webinar on up-and-coming machine learning (ML) trends — this year, with a spin on grounding those research trends in reality with actual use cases from our data science team. In this blog series, we’re going to break up their main topics (data drift and anomaly detection, learning with small data, retail markdown optimization, and uplift modeling and causal inference) so they’re digestible and accessible as you aim to shift from theory to practice with your ML initiatives in 2022 and beyond. Last time, we tackled model changes, data, drift, and anomaly detection, so up next is a summary of the section on learning with small data. Enjoy!
Léo Dreyfus-Schmidt:
Another one of our research topics we've been working on for the past year is everything related to learning with small data. In a very general term, not only the quantity of data, but the quantity of labeled data and things like that. There's this cloud image which represents this huge question of how do you deal in general with unlabeled data? How can you leverage unlabeled data for your model?
You can have the first approach, like you did, Reda, which is fully unsupervised, fully focusing on the only data you have, which is the thing that you know. And then you want to move towards, as we say, leveraging this unlabeled data. There's three families of techniques, very broadly, that we can see, that we can study. The first one on the left is semi-supervised learning, which is this idea of having a pool of labeled data, which, usually, is very small with respect to a larger pool of unlabeled data. How can you make the best of both worlds?
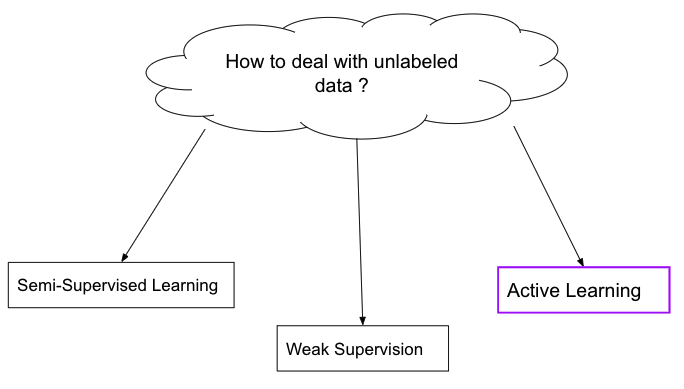
There's something in between, which is called weak supervision, which is something I won’t get into today, unless you ask specific questions. And then the third one, which is highlighted in purple, is active learning, which is actually going to help you move from the fully unlabeled data regime to semi-supervised learning, and then later on to fully supervised learning. It's about how to optimize the labeling of that data. For you, Reda, you said that you had a first model that outcome a potential set of anomalies. But then I guess somebody has to go and check and say, "Yeah, I agree. Anomaly is right. This is not okay. This is an anomaly on my production line." Then, you get a first labeled sample. So I can show you very quickly what's the definition of active learning and how we think it might help optimize the labeling process of the new data.
What you usually do is you have some existing unlabeled data, then you can randomly select some of those that you are going to be labeling. Here, it would be very bad for your use case, Reda. You'd be like, "I have lots of data coming in. I'm just going to randomly sample one and ask myself, is it okay? Is it not okay?" But most of the time here, as you said, it should be okay, so like random selection, you can tell from this, it will be a very bad option. And then you can send it to be labeled, what we call in literature by an oracle, but would actually be a human being, an expert who'll say, "Yeah, this is okay. This is not okay." And then use that. You train your model on the labeled data. Then, if you do that, or you can see in the image, then the more you label the data, hopefully the more accuracy gained.
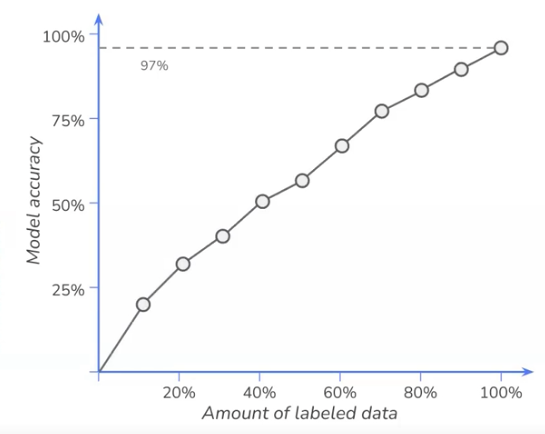
This is true, but with viewing those cases, it won't be that true because as we say, you will keep uncovering a lot of those data. Active learning is just this idea, I want to replace that random selection. I want to see if I can drive the selection process of the data that you should be labeling. Ultimately, and that's theoretically, sometimes when things go smooth, you can tell that it will actually give you an uplift, so we'll actually do more with less labeled data, and have a higher accuracy. Here in this example, we could go, “Oh, but that's super hard” and maybe find a way and that's actually what you described as your first model will be that sampler of active learning. It will give you a good proposal for things that could be anomalies.
This is actually doing active learning. Like I said, this is a topic module we've been interested in and here are three concrete deliverables we've been working on this year. It's two papers on the right and on the left, which we've been working on, which has been focusing on understanding how to help people choose the best way to do active learning. There's a lot of techniques out there and other robust literature in general, how you can choose and it's very time consuming to do so — when you can get the best of active learning methods. And in the middle, what you can see is something we're also very excited about, as we've been open sourcing our own Python package, which is called Cardinal. We put it in red, so you can really see the pun with AL as active learning. Also, a cardinal is a bird, so we're staying in the bird family at Dataiku.

This is another piece of our work that we've been trying to push to the community, and we hope will help us make a smooth transition from this fully unlabeled regime to a more supervised domain where we can rely on more classical ML. I'll be super curious, Reda, to see if that project, you will be able to bootstrap with this, then later you can move on to using similar supervised learning. It raised a level of question, how much labeled data do you need to get there? When does that make a difference? But that's all for this part.
Stay tuned for our next article which will deep dive into the next ML trends we outlined for 2022: markdown optimization and uplift modeling.