

Since the release of Cloudera Data Engineering (CDE) more than a year ago, our number one goal was operationalizing Spark pipelines at scale with first class tooling designed to streamline automation and observability. In working with thousands of customers deploying Spark applications, we saw significant challenges with managing Spark as well as automating, delivering, and optimizing secure data pipelines. We wanted to develop a service tailored to the data engineering practitioner built on top of a true enterprise hybrid data service platform.
A key tenant of CDE is modularity and portability, that’s why we focused on delivering a fully managed production ready Spark-on-Kubernetes service. This allowed us to have disaggregated storage and compute layers, independently scaling based on workload requirements.
We also introduced Apache Airflow on Kubernetes as the next generation orchestration service. Data pipelines are composed of multiple steps with dependencies and triggers. A flexible orchestration tool that enables easier automation, dependency management, and customization — like Apache Airflow — is needed to meet the evolving needs of organizations large and small. Packaging Apache Airflow and exposing it as a managed service within CDE alleviates the typical operational management overhead of security and uptime while providing data engineers a job management API to schedule and monitor multi-step pipelines.
To ensure these key components scale rapidly and meet customer workloads, we integrated Apache Yunikorn, an optimized resource scheduler for Kubenetes that overcomes many of the deficiencies in the default scheduler, and allows us to provide new capabilities such as queuing, prioritization, and custom policies.
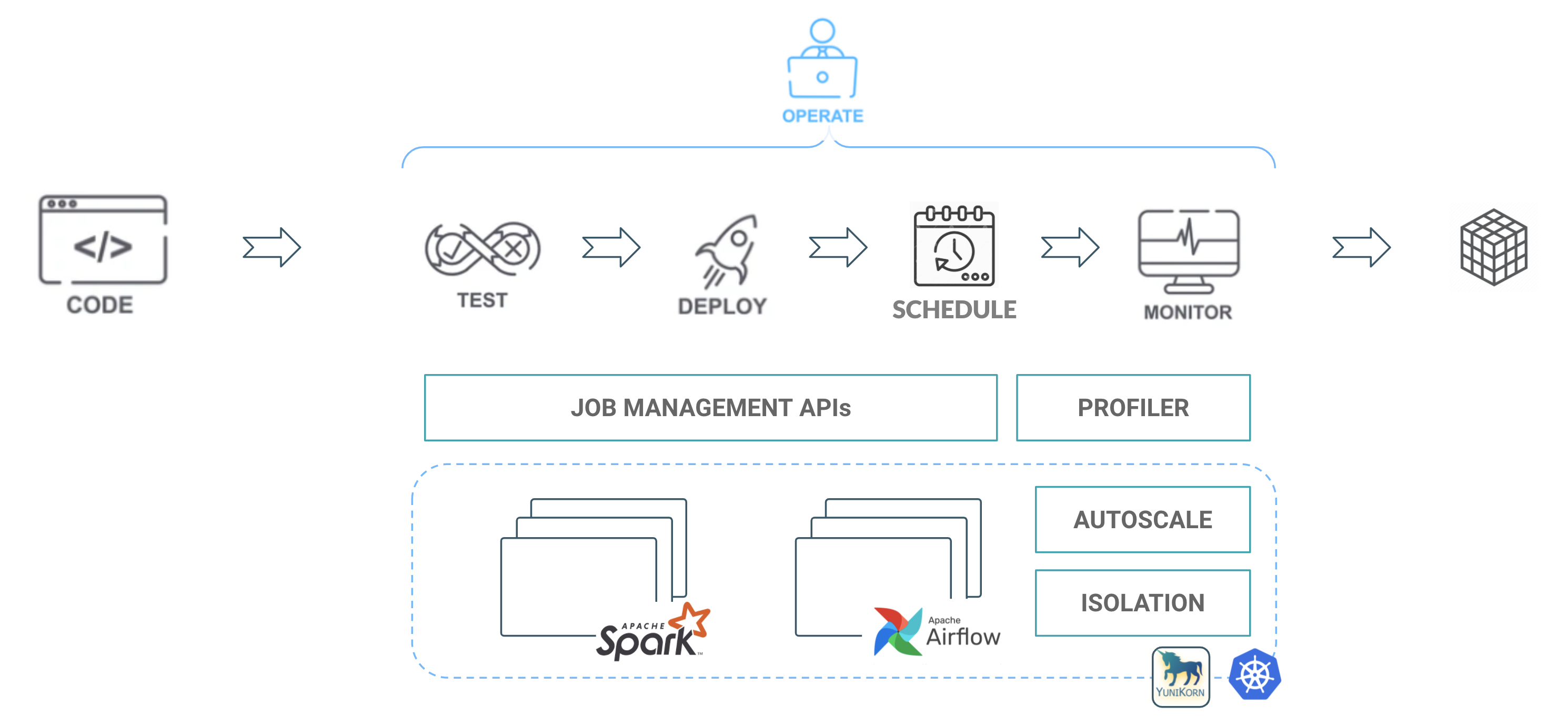
Figure 1: CDE service components and practitioner functions
New in 2021
Over the past year our features ran along two key tracks; track one focused on the platform and deployment features, and the other on enhancing the practitioner tooling.
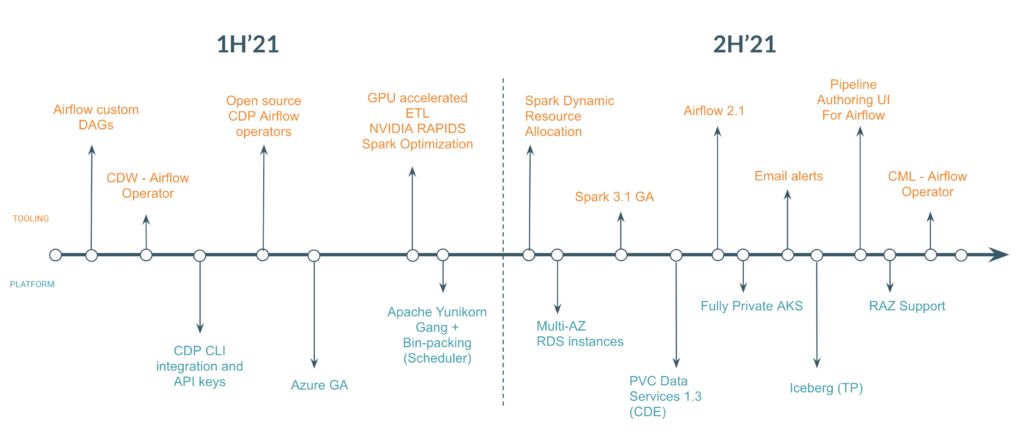
Figure 2 – CDE product launch highlights in 2021
Platform
Hybrid
Early in the year we expanded our Public Cloud offering to Azure providing customers the flexibility to deploy on both AWS and Azure alleviating vendor lock-in. And we followed that later in the year with our first release of CDE on Private Cloud, bringing to fruition our hybrid vision of develop once and deploy anywhere whether it’s on-premise or on the public cloud.
Autoscaling speed and scale
We tackled workload speed and scale through innovations in Apache Yunikorn by introducing gang scheduling and bin-packing. This allowed us to increase throughput by 2x and reduce scaling latencies by 3x at 200 node scale. Customers using CDE automatically reap these benefits helping reduce spend while meeting stringent SLAs.
Securing and scaling storage
At the storage layer security, lineage, and access control play a critical role for almost all customers. Cloudera’s Shared Data Experience (SDX) provides all these capabilities allowing seamless data sharing across all the Data Services including CDE. A new capability called Ranger Authorization Service (RAZ) provides fine grained authorization on cloud storage. Customers can go beyond the coarse security model that made it difficult to differentiate access at the user level, and can instead now easily onboard new users while automatically giving them their own private home directories. This also enables sharing other directories with full audit trails. As data teams grow, RAZ integration with CDE will play an even more critical role in helping share and control curated datasets.
And we didn’t stop there, CDE also introduced support for Apache Iceberg. For those less familiar, Iceberg was developed initially at Netflix to overcome many challenges of scaling non-cloud based table formats. Today it’s used by many innovative technology companies at petabyte scale, allowing them to easily evolve schemas, create snapshots for time travel style queries, and perform row level updates and deletes for ACID compliance. We are excited to offer in Tech Preview this born-in-the-cloud table format that will help future proof data architectures at many of our public cloud customers.
Tooling
Modernizing pipelines
One of the key benefits of CDE is how the job management APIs are designed to simplify the deployment and operation of Spark jobs. Early on in 2021 we expanded our APIs to support pipelines using a new job type — Airflow. With the same familiar APIs, users could now deploy their own multi-step pipelines by taking advantage of the native Airflow capabilities like branching, triggers, retries, and operators. To date we have thousands of Airflow DAGs being deployed by customers in a variety of scenarios, ranging from simple multi step Spark pipelines to re-usable templatized pipelines orchestrating a mix of Spark, Hive SQL, bash and other operators.
CDP Airflow Operators
Since Cloudera Data Platform (CDP) enables multifunction analytics such as SQL analytics and ML, we wanted a seamless way to expose these same functionality to customers as they looked to modernize their data pipelines. Besides the CDE Airflow operator, we introduced a CDW operator that allows users to execute ETL jobs on Hive within an autoscaling virtual warehouse. This enabled new use-cases with customers that were using a mix of Spark and Hive to perform data transformations.
Secondly, instead of being tied to the embedded Airflow within CDE, we wanted any customer using Airflow (even outside of CDE) to tap into the CDP platform, that’s why we published our Cloudera provider package. And we look forward to contributing even more CDP operators to the community in the coming months.
Performance boost with Spark 3.1
With the release of Spark 3.1 in CDE, customers were able to deploy mixed versions of Spark-on-Kubernetes. This provided users with more than a 30% boost in performance (based on internal benchmarks). A new option within the Virtual Cluster creation wizard allowed new teams to spin up auto-scaling Spark 3 clusters within a matter of minutes. Once up and running, users could seamlessly transition to deploying their Spark 3 jobs through the same UI and CLI/API as before, with comprehensive monitoring including real-time logs and Spark UI.
Airflow 2.1 refresh
We track the upstream Apache Airflow community closely, and as we saw the performance and stability improvements in Airflow 2 we knew it was critical to bring the same benefits to our CDP PC customers. In the latter half of the year, we completely transitioned to Airflow 2.1. As the embedded scheduler within CDE, Airflow 2 comes with governance, security and compute autoscaling enabled out-of-the-box, along with integration with CDE’s job management APIs making it an easy transition for many of our customers deploying pipelines.
Self-service pipeline authoring
As we worked with data teams using Airflow for the first time, writing DAGs and doing so correctly, were some of the major onboarding struggles. That’s why we saw an opportunity to provide a no-code to low-code authoring experience for Airflow pipelines. This way users focus on data curation and less on the pipeline gluing logic. The CDE Pipeline authoring UI abstracts away those complexities from users, making multi-step pipeline development self-service and point-and-click driven. Providing an easier path than before to developing, deploying, and operationalizing true end-to-end data pipelines.
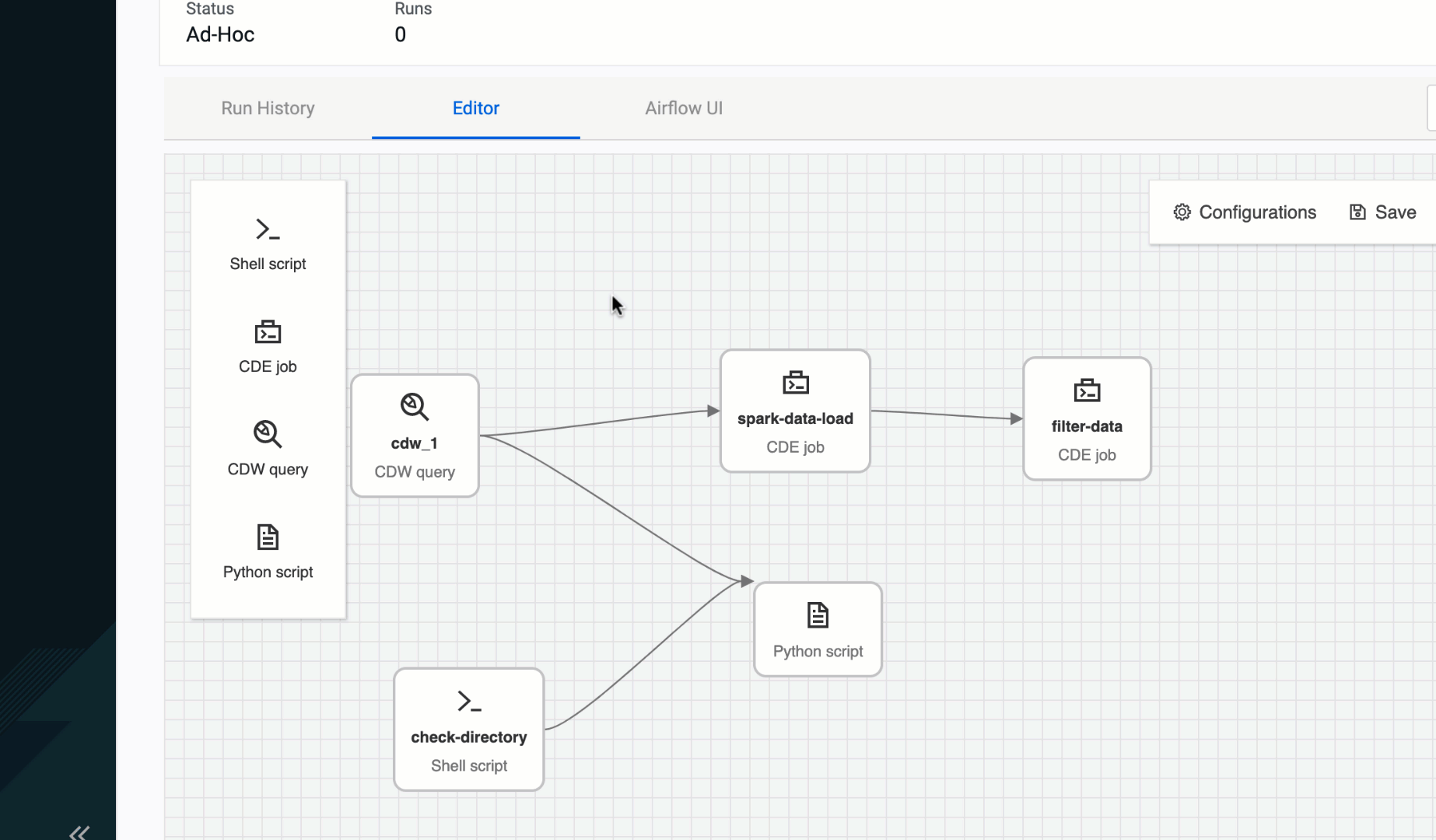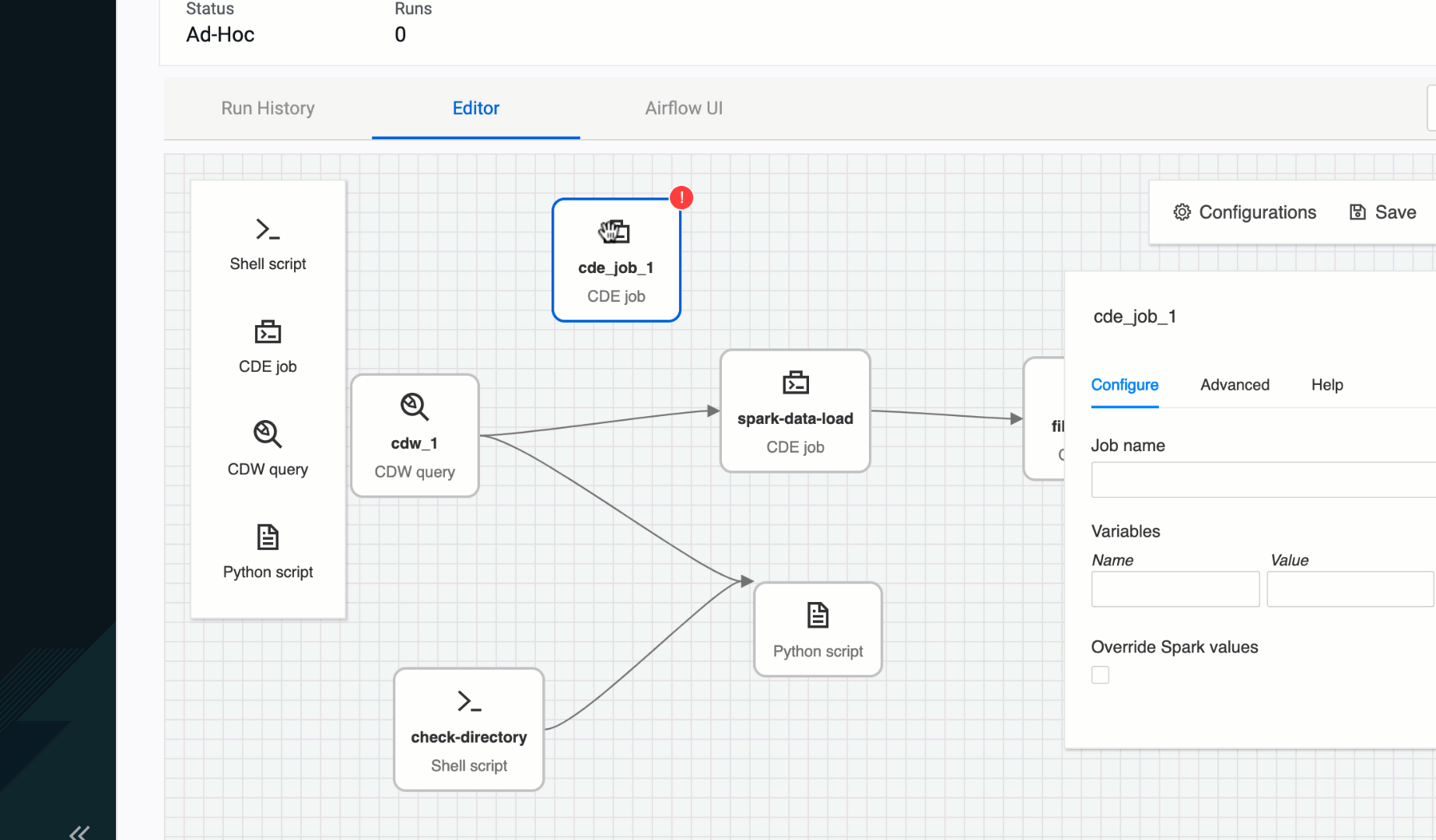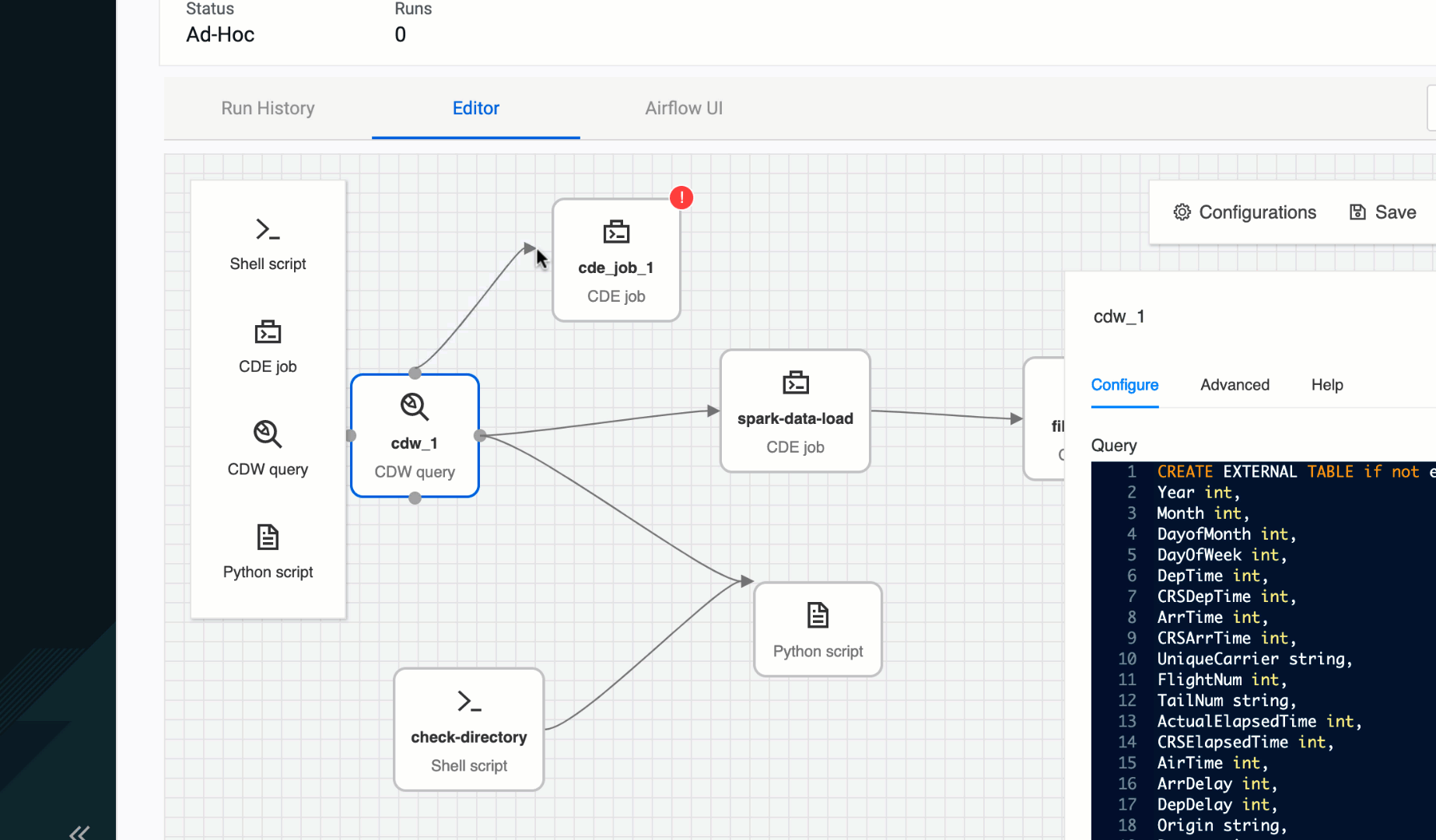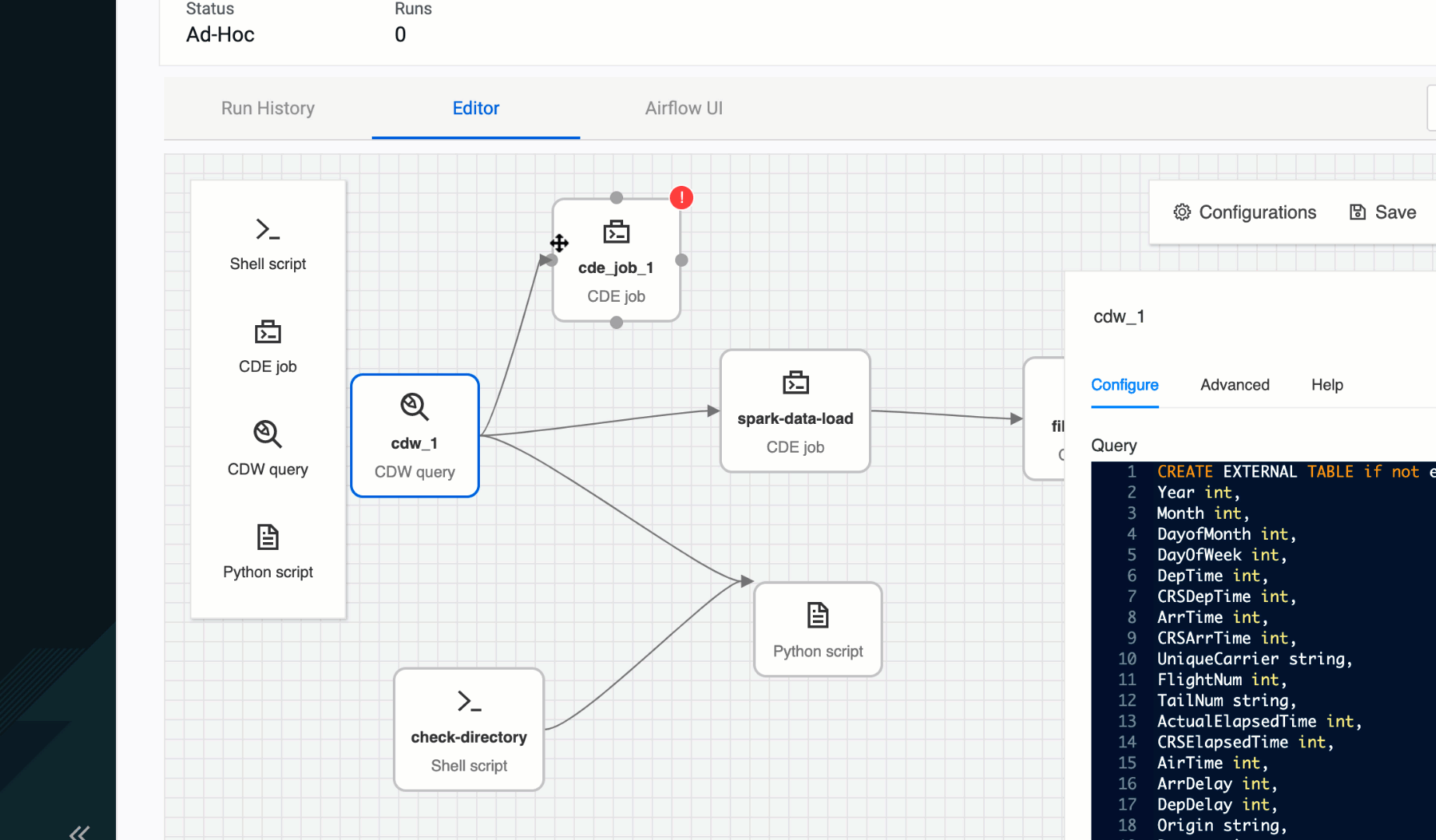
Figure 3: CDE Pipeline authoring UI
Partners
Lastly, we have also increased integration with partners. With our custom runtime support, ISV partner Precisely was able to integrate their own libraries to read and process data pipelines using Spark on customized container images. Modak Nabu™ a born-in-the-cloud, cloud-neutral integrated data engineering application was deployed successfully at customers using CDE. With Modak Nabu™, customers have deployed a Data Mesh and profiled their data at an unprecedented speed — in one use-case a pharmaceutical customer’s data lake and cloud platform was up and running within 12 weeks (versus the typical 6-12 months). This is the scale and speed that cloud-native solutions can provide — and Modak Nabu™ with CDP has been delivering the same.
Happy New Year
As exciting 2021 has been as we delivered killer features for our customers, we are even more excited for what’s in store in 2022. In the coming year, we’re expanding capabilities significantly to help our customers do more with their data and deliver high quality production use-cases across their organization. Along with delivering the world’s first true hybrid data cloud, stay tuned for product announcements that will drive even more business value with innovative data ops and engineering capabilities. Test Drive CDP Public Cloud.
Editor's Choice


Great product!
I would love to see some “auto-tune” capabilities powered by AI (historical runs, etc.) in 2022 allowing the service to auto-tune things like instance type, local disks and similar stuff. This will reduce operational overhead even more while it simplify provisioning and gives the service truly a “serverless” feeling.