OpenAI’s generative pre-trained transformers (GPTs) bring powerful AI language models to every IT community. Within the past few months, ChatGPT has become an incredibly popular derivative of GPT. GPT also has the potential to shake up the DevOps and DevSecOps communities. This article will provide an overview of GPT, its history, current status and future effects on IT, especially DevOps.
Learning Overview
Understanding the difference between supervised and unsupervised learning is essential before understanding GPT. Machine learning and artificial intelligence (AI) use unsupervised and supervised learning approaches. A supervised model uses labeled data to predict outcomes, while an unsupervised model does not. In general, supervised models have some limitations. They need a large amount of annotated data to learn a particular task, which is often unavailable, and they also need to generalize beyond the task for which they were trained.
A generative language model is a class of statistical models that differ from discriminative models. You can, for example, generate photos of animals that look like real ones using a generative model. Whereas with a discriminative model, you can determine whether an animal is a dog or a cat. Generative models can assign probabilities to a series of words, such as those that predict the next word or sentence. A generative pre-trained transformer is unique because it uses both unsupervised and supervised learning from unsupervised unlabeled text and follows up with discriminative supervised fine-tuning.
GPT-based models—ChatGPT, for example—always return the text “I am” when asked, “I think, therefore …” On the other hand, if you ask ChatGPT, “Why did the rabbit cross the road?” it may respond thusly:
“The age-old riddle still awaits an answer: Why did the rabbit cross the road? It’s a mystery that has stumped people for centuries and will likely remain an enigma for years to come.”




In this way, we can better understand how GPT-3 works. When asked, “Why did the rabbit cross the road?” most humans will answer, “To get to the other side.” A Google search for “Why did the rabbit cross the road?” mainly yields joke punchlines on the first page of the results. GPT doesn’t differentiate between humorous or cynical answers or specific matter-of-fact answers. The model makes only guesses based on the data. Since, in this example, most of the highest-ranked answers are jokes, GPT’s answer is enigmatic at best. GPT is not pixie dust; it doesn’t have a sense of humor, is not sentient, doesn’t understand juxtapositions and, most importantly, doesn’t evaluate context. As another example, I asked a GPT-3 tool to provide biographical information about two individuals. Abraham Lincon was the first. Approximately ten paragraphs of accurate facts were generated by the GPT-3 tool. Second, I used Gene Kim, the author of The Phoenix Project and The DevOps Handbook. GPT-3 began inventing facts about the companies he worked for by the second paragraph. Additionally, it suggested that he had spoken at TEDx. While a Dr. Gene Kim has spoken at TEDx, that Dr. Kim is an opthamologist.
History of GPT
GPT was released for the first time on June 11, 2018. Sometimes it is referred to as the GPT-1 model. A large dataset of online books was used to train it. A database called BookCorpus also was used for training. There were 7,000 unpublished books in the original BookCorpus dataset at the time of training.
OpenAI’s GPT-2 model was created in 2019 as a direct scale-up of the original GPT model. There were ten times as many parameters and ten times as much data in that training set. The GPT-2 dataset was based on an internal OpenAI dataset called WebText. A focus was placed on the quality of the documents when scraping web pages for this tool. The authors scraped all Reddit outbound links receiving at least three upvotes. GPT-2 used about 40GB of Internet text, 8 million web pages, and 1.5 billion parameters. In neural networks, parameters are often used as synonyms for weights (found more often in statistics literature). Parameters in GPT are the weights and biases of the dataset and generally indicate the power.
As the third-generation language model, GPT-3 was introduced in May 2020. It has 175 billion parameters, making it more accurate than its predecessors—an increase of tenfold in capacity over the next largest NLP model available. Sixty percent of GPT-3’s weighted pre-training dataset is filtered Common Crawl. Common Crawl is a nonprofit organization that crawls the web and makes its archives and datasets freely available. Since 2011, Common Crawl has collected petabytes of data. About 37% of the GPT-3 sources were WebText2 and other sources, while about 3% came from Wikipedia. OpenAI Codex was also included with GPT-3, which generated code and served as the basis for GitHub’s Copilot.
As part of its training, GPT-3 used data available until November 2019. Thus, GPT-3 was unaware of events beyond January 2020. COVID-19, for instance, was unknown to it. Even so, it did have extensive knowledge of coronaviruses, pandemics, Wuhan and SARS. As of September 22, 2020, Microsoft, through a considerable investment, received exclusive permission to use GPT-3; others can still access GPT-3’s public API, but Microsoft is the only one with access to the underlying model. OpenAI developed DALL-E in January 2021, which generated images using GPT-3. OpenAI introduced models in the “GPT-3.5” series on November 30, 2022, including the now-famous ChatGPT, derived from a model from the GPT-3.5 series. Unlike GPT-3, GPT-3.5 includes data up until November 2022.
Current Status
I have used several AI language model tools in the past few years based on GPT-3. It is used by Grammarly and by some useful writing tools like Jasper.ai and Wordtune. I also have had great success with GPT-3 research tools like Frase.io and Genei.io. One of my more recent go-to tools is called QuillBot. In my experience, these tools are aids, not replacements for writing. When I first started using these tools, I was writing a book about Dr. W. Edwards Deming. I would get inaccurate information about Dr. Deming’s childhood from a GPT-3-based tool. One time, it said he had six siblings. In fact-checking, GPT-3 confused Dr. Edwards Deming with Dr. Richard Deming. With surgically precise input, the results could be more accurate. One of my findings was that if I used a GPT-3 on a well-known subject, the information was primarily precise; however, lesser-known topics produce fewer facts. Furthermore, I learned from the documentation that when people talk about training GPT-3 models, what they really mean is that you can input a maximum of 2,048 linguistic tokens, which is about 1,500 words. In GPT-3, content is predicted by analyzing past context, one word at a time. The content you input to GPT-3 significantly impacts its output. As a result, it pulls words from a shortlist and calculates their probability of being used. A great set of tutorials on using GPT-3 can be found on Jasper.ai. This figure shows how Jasper (which is based on GPT-3) word prediction works.
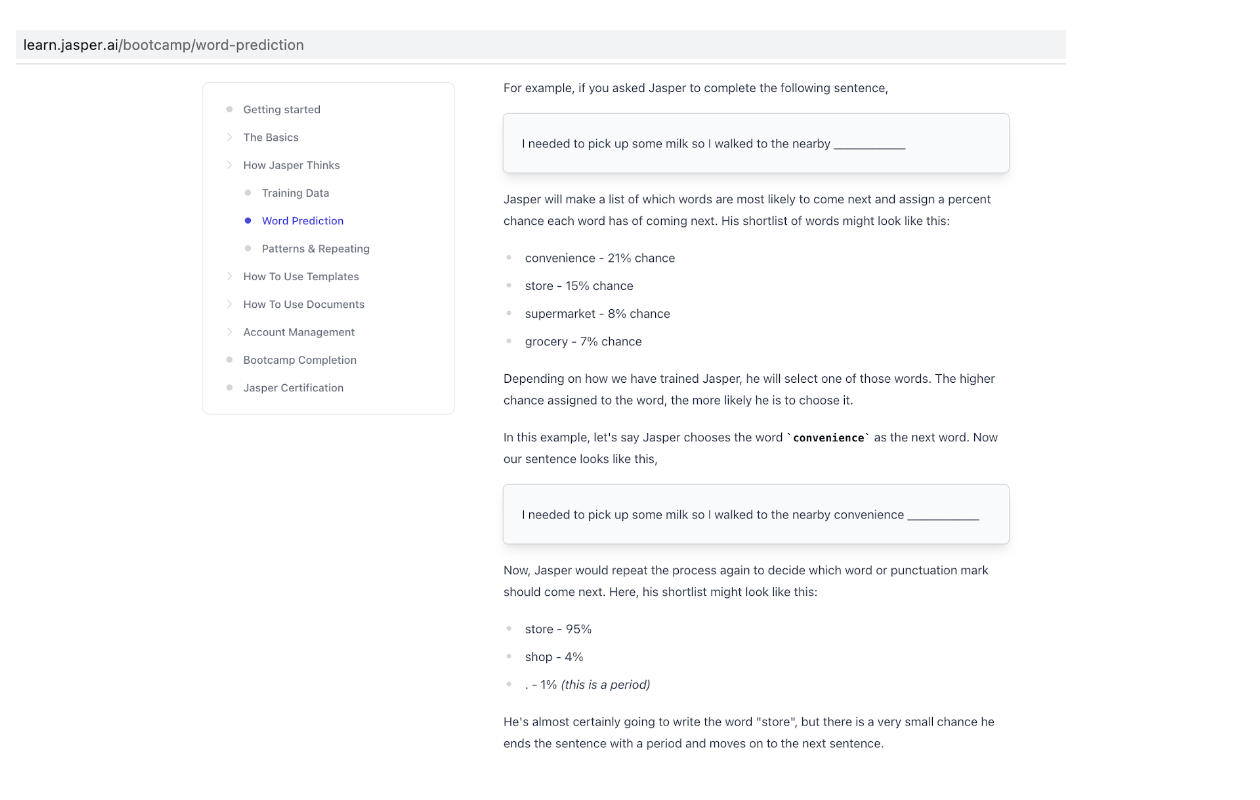
People have accomplished some remarkable things by using the 2,048 tokens creatively, but complex training still needs to be improved. Due to the Microsoft deal, the original GPT models were close sourced, and robust training of GPT-3 models is unlikely to happen any time soon.
Future Effects on IT
Where does all the hype come from? Despite its limitations, GPT-3 has created some unique industry artifacts. DALL-E and Copilot by Github are excellent tools. On September 8, 2020, the Guardian published an article titled, “A robot wrote this entire article. Are you scared yet, human?” This article was written by GPT-3. Using GPT-3, some full-blown novels have also been written; they’re not horrible, but they could have been better. According to a study conducted by Drexel University in 2022, systems based on GPT-3 could be used to screen for Alzheimer’s disease at an early stage. Just five days after its launch, ChatGPT surpassed one million users. It took 41 months for Netflix to reach one million users and 10 months for Facebook to reach one million users. By the end of the first quarter of 2023, ChatGPT will have over one billion users. Based on GPT-3.5, ChatGPT is more robust and up-to-date.
How smart is ChatGPT? Using a verbal-linguistic IQ test and Raven’s ability test, ChatGPT has an IQ of 147. GPT-3.5 has passed the United States bar exam, CPA exam and U.S. medical licensing exam. People often ask if it is plagiarism to use GPT-3. Technically, the answer is no. The GPT datasets are estimated to represent 300 years of pre-training with a connection of trillions of words. However, using these tools for rewriting other people’s work is, from an ethical viewpoint, plain and straightforward plagiarism. A recent set of tweets by Greg Brockman, president and co-founder of OpenAI and Sam Altman, CEO of OpenAI, sums up the current status of ChatGPT.

What Does This Mean for DevOps Practitioners?
AI learning models based on GPT-3 are here to stay. From grammar correction to proposal writing to code generation, GPT-3 has revolutionized everything. In my opinion, GPT-3 still needs to solve some challenges before it is of actual value to DevOps and DevSecOps patterns and practices. For example, a great use case for GPT-3 is training it to deal with organizational incidents. If a GPT model could be trained this way, it would become an excellent tool for providing adaptive diagnostics. Based on the current GPT implementation, this is very difficult or impossible. Another example would be to train the model with the organization’s IT risk policies and enable predictive solutions. The opportunities are endless.
An alternative to GPT-3 is InstructGPT, which OpenAI describes as more truthful and less toxic. It has also been noted that GPT-3 can generate untruthful outputs. GPT models aren’t generally aligned with their users. InstructGPT models follow instructions much better than GPT-3. Furthermore, InstructGPT produces more truthful and less toxic outputs. Therefore, they generate fewer harmful outputs and more facts. The InstructGPT models use human feedback as part of the training model. Some of the real power behind ChatGPT is that it uses InstructGPT along with GPT-3.5. Some of my upcoming research will focus on prototyping some of the complex opportunities DevOps and DevSecOps practitioners currently face using InstructGPT.