RAG: Amplifying the Generative AI
Information is all around us, currently the matter is what to believe and what not to, right information and misleading information both exist together and that is when we turn to reliable sources and some concrete evidence to support our thought and belief. AI has access to all the information available on the internet, making us rely on it for answers.
For example, if you are asked which planet has the most moons, you might say Jupiter as it seems an obvious answer but as you are asked the source or evidence supporting it, you will be left blank and then when you proceed to verify your confident answer, you find that it is Saturn according to the latest data, this does not just apply to you but also to the generative AI chatbots which people rely on for common queries like this, LLMs can be outdated and even retrieve answers from non-reliable sources, this is where RAG AI comes to solve the issues. RAG Generative AI ensures that the query is answered and supported by facts and data from a reliable source, making it more accurate.
RAG or Retrieval Augmented Generation is the technology which ensures that LLM models can base their outputs upon reliable sources from the internet (which is an open source) or a set of documents or internal data (which is closed source). This will strengthen the answer with evidence, reducing hallucinations in the application.
Vital Components of RAG
RAG has primarily three components which complete the model, all these are equally important and contain a chain of processes within them.
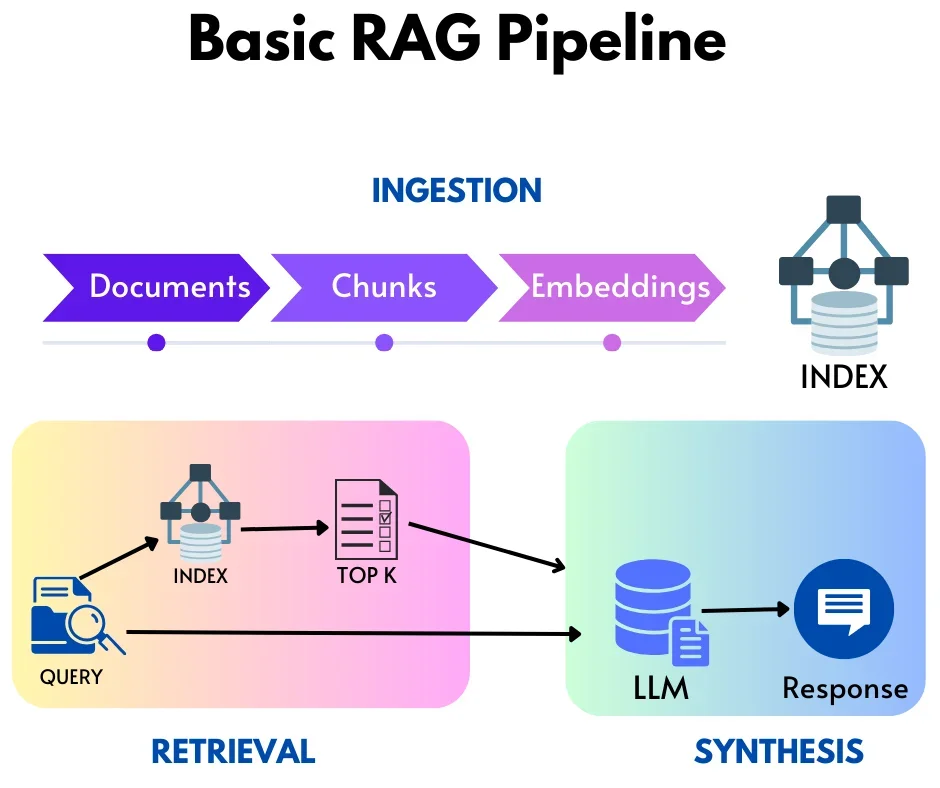
Ingestion, we first load a set of documents for each document, we split more text documents into chunks and then we proceed to create embeddings for these chunks, finally for these chunks with embeddings we offload it into a storage system. Once the data is stored, we can move onto retrieval, launch a user query for the index, we fetch the top results with similar chunks, and we take these relevant chunks to combine with the user query and put it in the prompt window of the LLM model.
Meeting the RAG Triad
Putting it into Work
We can look below to see the exact process which the program goes through:
- A user requests the system when a user submits a message or inquiry to the chat program, the procedure starts.
- Application transmits an inquiry. The user’s query is sent to the Retrieval Augmented Generation (RAG) model by the chat application for processing.
- RAG obtains and produces an answer. The user’s query is processed by the RAG AI model, which combines retrieval and generating capabilities. Prior to employing the LLM to produce a logical and contextually appropriate answer based on the information gathered and the user’s inquiry, it first retrieves pertinent information from a vast corpus of data.
- LLM responds back. The LLM returns the generated response to the chat application.
- Responses are seen in the app. The user interface is completed when the chat program shows the created response to them.
Evaluating for Refinement
The outputs can be evaluated for refining and testing them for certain benchmarks which are then used to improve the model.
Feedback Function
You can evaluate and determine how to enhance the quality of retrieval for your RAG by using the feedback functions. Additionally, they can be utilized to optimize your RAG’s setup settings, which include various metrics, parameters, and models.
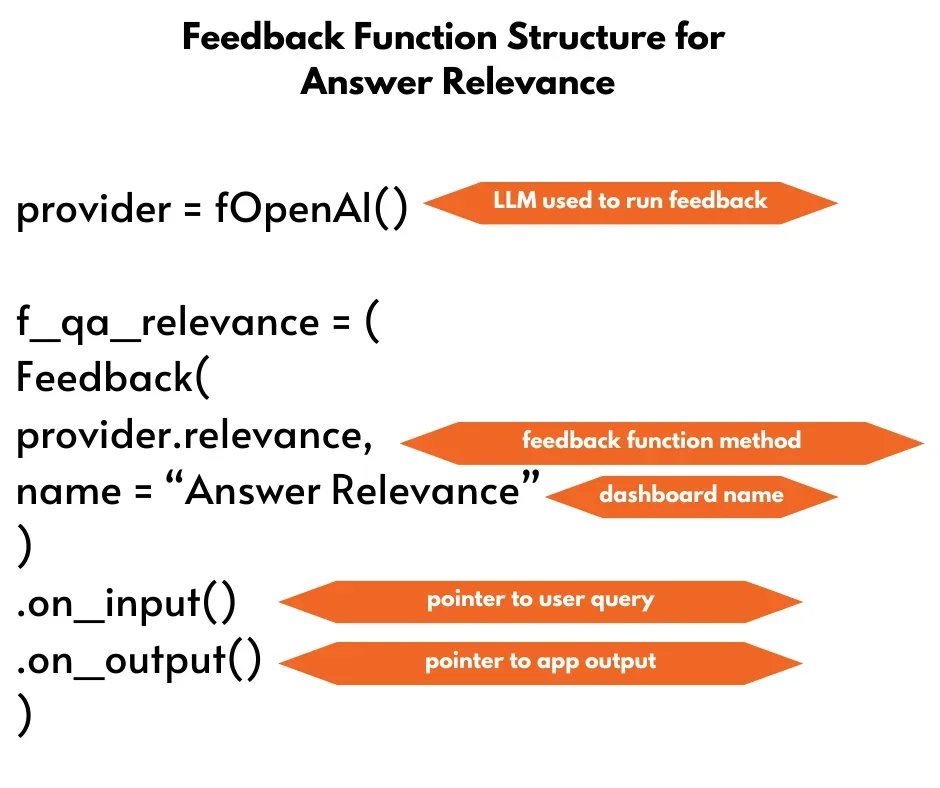

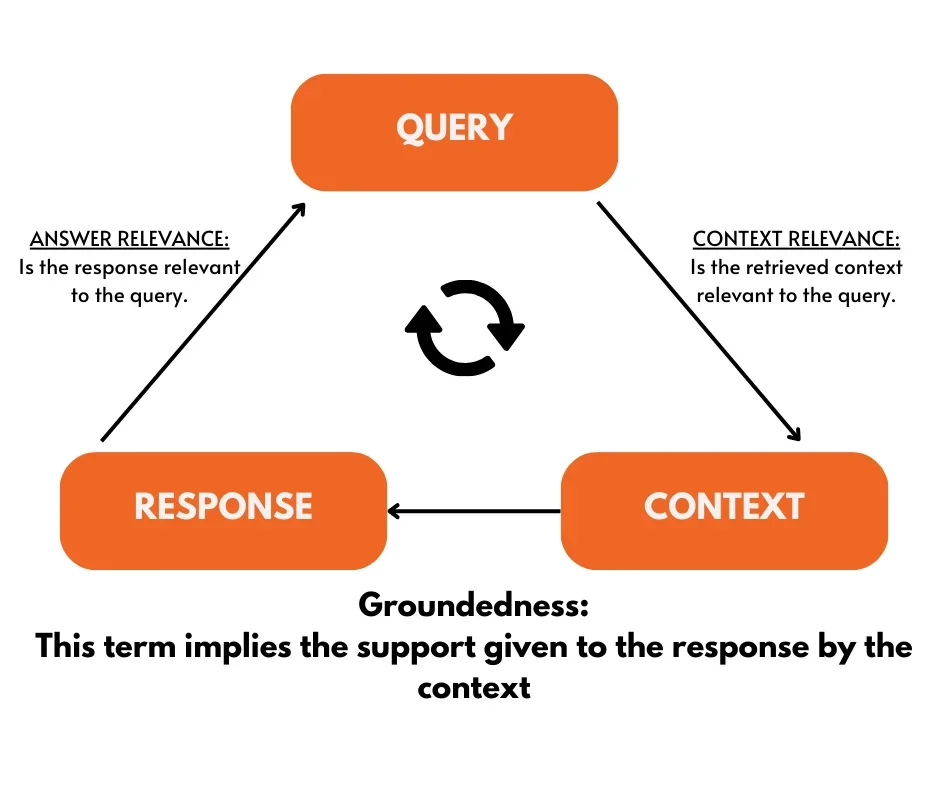
Answer Relevance
One of the RAG triad’s types of evaluation, answer relevance, is used to gauge how well the generated text is written. Its main objective is to evaluate the generated answer’s relevance to the provided prompt. Responses with redundant or incomplete information receive a lower score.

Context Relevance
All RAG Generative AI applications begin with a context relevance evaluation. By confirming that every bit of context is pertinent to the input query, it validates the quality of retrieval. This is crucial since the LLM will utilize the context to formulate an answer, and any irrelevant elements could be combined to create a hallucination.

Retrieiving Conclusion
As we have seen, Retrieval-Augmented Generation (RAG) enables LLMs to retrieve information from an external knowledge store to augment their internal representation of the world. RAG has various uses in question-answering, chatbots, and customer service, and is especially helpful in overcoming knowledge cutoff and hallucination issues. Businesses can enhance the quality and dependability of their LLM-generated responses and, consequently, the user experience by adhering to best practices for implementing RAG.
To progress in the constantly changing field of artificial intelligence, knowing RAG is vital regardless matter whether you’re a developer hoping to create smarter AI systems, a business trying to enhance customer experience, or just an AI enthusiast.
Sunflower Lab has worked with many industries and has proven the expertise of AI/ML which will expand your business capabilities through digital solutions, contact our experts today.
You might also like
Stay ahead in tech with Sunflower Lab’s curated blogs, sorted by technology type. From AI to Digital Products, explore cutting-edge developments in our insightful, categorized collection. Dive in and stay informed about the ever-evolving digital landscape with Sunflower Lab.