


The Importance of Distributed Tracing for Apache-Kafka-Based Applications
Confluent
MARCH 26, 2019
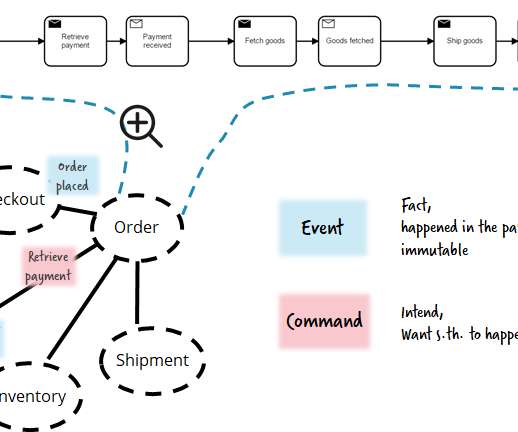
Apache-Kafka ® -based applications stand out for their ability to decouple producers and consumers using an event log as an intermediate layer. This article describes how to instrument Kafka-based applications with distributed tracing capabilities in order to make dataflows between event-based components more visible.
































Let's personalize your content