Disaster Recovery for Multi-Datacenter Apache Kafka Deployments
Confluent
NOVEMBER 29, 2022
Apache Kafka multi-datacenter with Confluent Replicator, Schema Registry, timestamp preservation, consumer offset reset, failover and failback workflows.

 confluent-replicator
confluent-replicator 
Confluent
NOVEMBER 29, 2022
Apache Kafka multi-datacenter with Confluent Replicator, Schema Registry, timestamp preservation, consumer offset reset, failover and failback workflows.

Confluent
APRIL 10, 2019
Instead of having many point-to-point connections between sites, the Confluent Platform provides an integrated event streaming architecture with frictionless data replication between sites. The key to the solution is Confluent Replicator, which enables frictionless data replication between sites.
This site is protected by reCAPTCHA and the Google Privacy Policy and Terms of Service apply.

Confluent
MAY 2, 2019
To be fair, a lot of things turn into significant burdens at scale, and it’s Confluent Control Center’s job to ease as many of them as possible. In Confluent Platform 5.2, Confluent Platform 5.2 Those statistical variations notwithstanding, Control Center has leveled up significantly in Confluent Platform 5.2.
Honeycomb
APRIL 8, 2021
This led us toward the Tiered Storage feature in Confluent Platform 6.0, The new hosts were replicating slower than expected. Both profiles below are as likely, and we possibly hit each one of them in succession: Just replicating data out of the m6g.large instances was over-saturating the host. Operational costs.

Confluent
MAY 2, 2019
To be fair, a lot of things turn into significant burdens at scale, and it’s Confluent Control Center’s job to ease as many of them as possible. In Confluent Platform 5.2, Confluent Platform 5.2 Those statistical variations notwithstanding, Control Center has leveled up significantly in Confluent Platform 5.2.

Perficient
MARCH 29, 2023
And this is just the technical aspects of replicating data from point A to point B, skipping over governance, MDM, CDC and all the other details around duplicate data. Most of these intermediate steps required custom code. Meanwhile, your business sponsors are waiting not-so-patiently for any results.
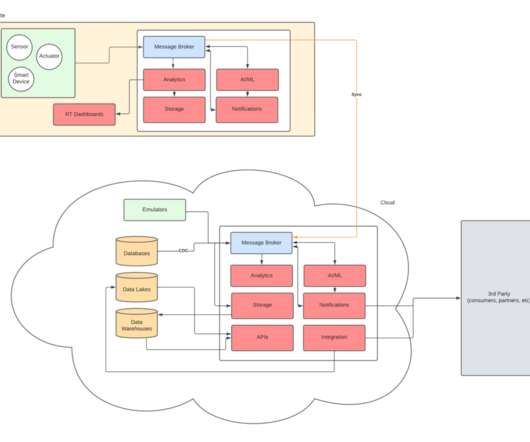
Perficient
DECEMBER 2, 2022
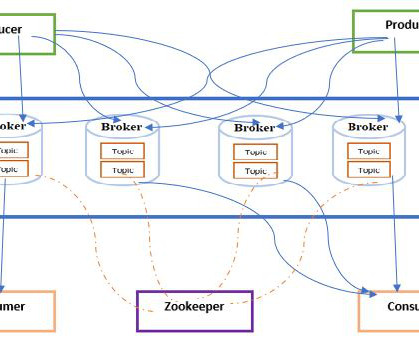
Kafka also supports replication between sites so it’s a great option to move data between sites and to the cloud. If you’re running your own MQTT broker, you can use MQTT replication to the cloud in some instances (Mosquitto Mirroring, HiveMQ Replication), but a better option is to use Kafka and leverage the mirroring feature.

Expert insights. Personalized for you.



































Let's personalize your content