Semi-supervised Image Classification With Unlabeled Data
Supervised learning is the key to computer vision and deep learning. However, what happens when you don’t have access to large, human-labeled datasets?
In this article, Toptal Computer Vision Developer Urwa Muaz demonstrates the potential of semi-supervised image classification using unlabeled datasets.

Supervised learning is the key to computer vision and deep learning. However, what happens when you don’t have access to large, human-labeled datasets?
In this article, Toptal Computer Vision Developer Urwa Muaz demonstrates the potential of semi-supervised image classification using unlabeled datasets.

Urwa is a Fulbright scholar and data science graduate from NYU. He loves leveraging machine learning to solve practical problems.
Expertise
PREVIOUSLY AT

Supervised learning has been at the forefront of research in computer vision and deep learning over the past decade.
In a supervised learning setting, humans are required to annotate a large amount of dataset manually. Then, models use this data to learn complex underlying relationships between the data and label and develop the capability to predict the label, given the data. Deep learning models are generally data-hungry and require enormous amounts of datasets to achieve good performance. Ever-improving hardware and the availability of large human-labeled datasets has been the reason for the recent successes of deep learning.
One major drawback of supervised deep learning is that it relies on the presence of an extensive amount of human-labeled datasets for training. This luxury is not available across all domains as it might be logistically difficult and very expensive to get huge datasets annotated by professionals. While the acquisition of labeled data can be a challenging and costly endeavor, we usually have access to large amounts of unlabeled datasets, especially image and text data. Therefore, we need to find a way to tap into these underused datasets and use them for learning.
Transfer Learning from Pretrained Models
In the absence of large amounts of labeled data, we usually resort to using transfer learning. So what is transfer learning?
Transfer learning means using knowledge from a similar task to solve a problem at hand. In practice, it usually means using as initializations the deep neural network weights learned from a similar task, rather than starting from a random initialization of the weights, and then further training the model on the available labeled data to solve the task at hand.
Transfer learning enables us to train models on datasets as small as a few thousand examples, and it can deliver a very good performance. Transfer learning from pretrained models can be performed in three ways:
1. Feature Extraction
Usually, the last layers of the neural network are doing the most abstract and task-specific calculations, which are generally not easily transferable to other tasks. By contrast, the initial layers of the network learn some basic features like edges and common shapes, which are easily transferable across tasks.
The image sets below depict what the convolution kernels at different levels in a convolutional neural network (CNN) are essentially learning. We see a hierarchical representation, with the initial layers learning basic shapes, and progressively, higher layers learning more complex semantic concepts.
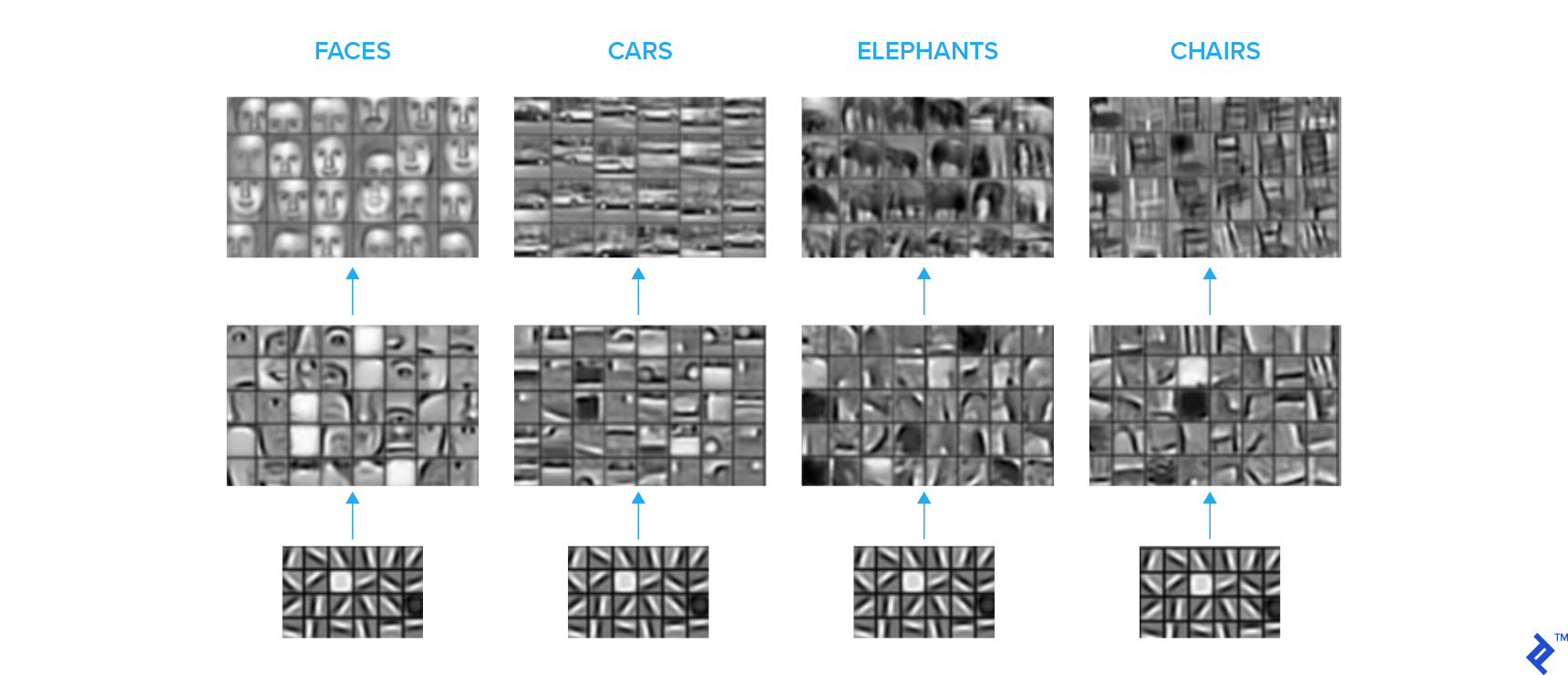
A common practice is to take a model pretrained on large labeled image datasets (such as ImageNet) and chop off the fully connected layers at the end. New, fully connected layers are then attached and configured according to the required number of classes. Transferred layers are frozen, and the new layers are trained on the available labeled data for your task.
In this setup, the pretrained model is being used as a feature extractor, and the fully connected layers on the top can be considered a shallow classifier. This setup is more robust than overfitting as the number of trainable parameters is relatively small, so this configuration works well when the available labeled data is very scarce. What size of dataset qualifies as a very small dataset is usually a tricky problem with many aspects of consideration, including the problem at hand and the size of the model backbone. Roughly speaking, I would use this strategy for a dataset consisting of a couple of thousand images.
2. Fine-tuning
Alternatively, we can transfer the layers from a pretrained network and train the entire network on the available labeled data. This setup needs a little more labeled data because you are training the entire network and hence a large number of parameters. This setup is more prone to overfitting when there is a scarcity of data.
3. Two-stage Transfer Learning
This approach is my personal favorite and usually yields the best results, at least in my experience. Here, we train the newly attached layers while freezing the transferred layers for a few epochs before fine-tuning the entire network.
Fine-tuning the entire network without giving a few epochs to the final layers can result in the propagation of harmful gradients from randomly initialized layers to the base network. Furthermore, fine-tuning requires a comparatively smaller learning rate, and a two-stage approach is a convenient solution to it.
The Need for Semi-supervised and Unsupervised Methods
This usually works very well for most image classification tasks because we have huge image datasets like ImageNet that cover a good portion of possible image space—and usually, weights learned from it are transferable to custom image classification tasks. Moreover, the pretrained networks are readily available off the shelf, thus facilitating the process.
However, this approach will not work well if the distribution of images in your task is drastically different from the images that the base network was trained on. For example, if you are dealing with grayscale images generated by a medical imaging device, transfer learning from ImageNet weights will not be that effective and you will need more than a couple of thousand labeled images for training your network to satisfactory performance.
In contrast, you might have access to large amounts of unlabeled datasets for your problem. That is why the ability to learn from unlabeled datasets is crucial. Additionally, the unlabeled dataset is typically far greater in variety and volume than even the largest labeled datasets.
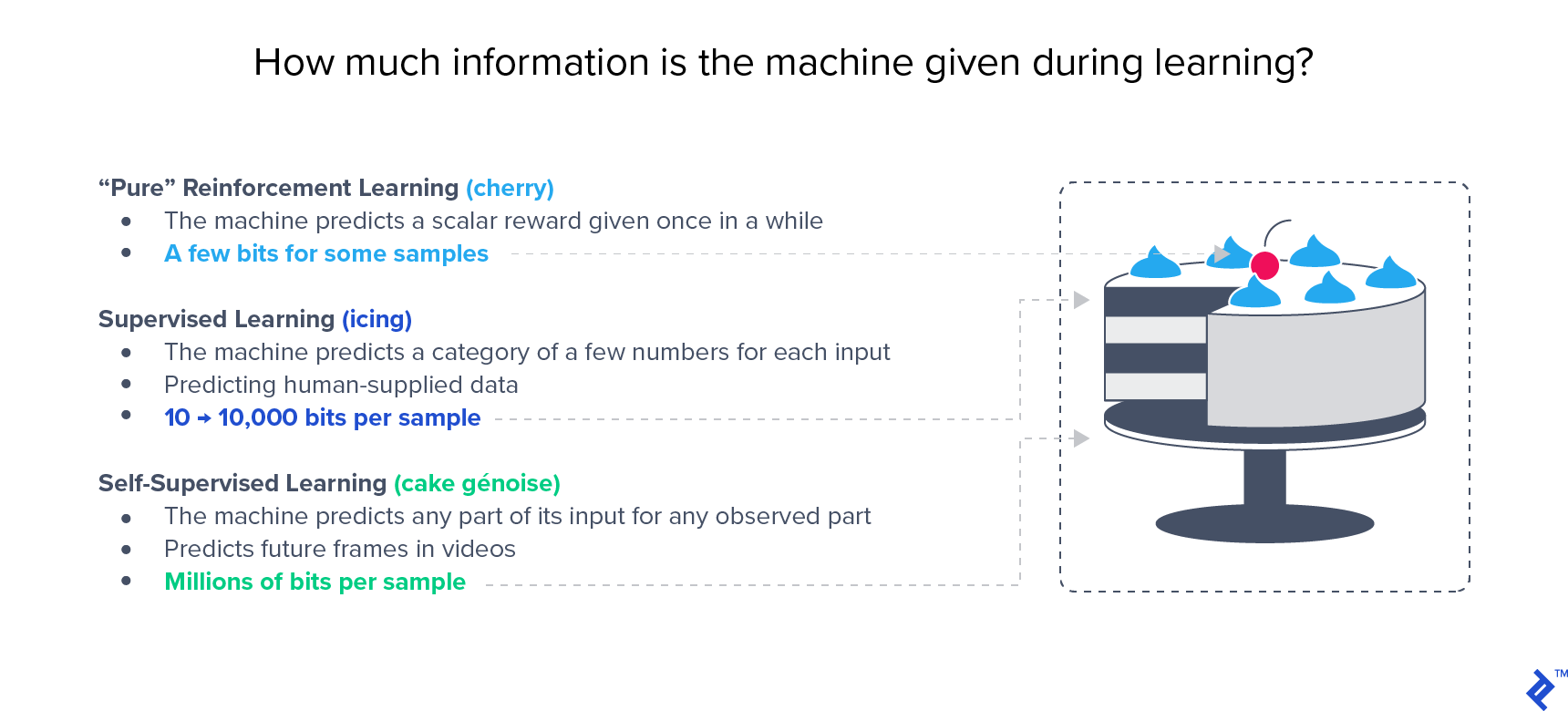
Semi-supervised approaches have shown to yield superior performance to supervised approaches on large benchmarks like ImageNet. Yann LeCun’s famous cake analogy stresses the importance of unsupervised learning:
Semi-supervised Learning
This approach leverages both labeled and unlabeled data for learning, hence it is termed semi-supervised learning. This is usually the preferred approach when you have a small amount of labeled data and a large amount of unlabeled data. There are techniques where you learn from labeled and unlabeled data simultaneously, but we will discuss the problem in the context of a two-stage approach: unsupervised learning on unlabeled data, and transfer learning using one of the strategies described above to solve your classification task.
In these cases, unsupervised learning is a rather confusing term. These approaches are not truly unsupervised in the sense that there is a supervision signal that guides the learning of weights, but thus the supervision signal is derived from the data itself. Hence, it is sometimes referred to as self-supervised learning but these terms have been used interchangeably in literature to refer to the same approach.
The major techniques in self-supervised learning can be divided by how they generate this supervision signal from the data, as discussed below.
Generative Methods
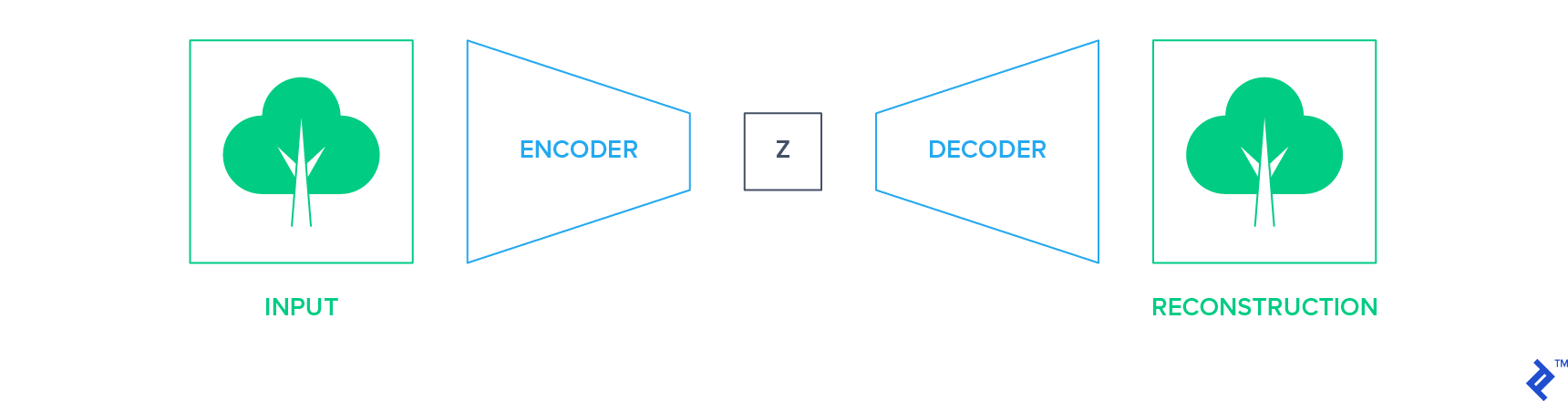
Generative methods aim at the accurate reconstruction of data after passing it through a bottleneck. One example of such networks is autoencoders. They reduce the input into a low-dimensional representation space using an encoder network and reconstruct the image using the decoder network.
In this setup, the input itself becomes the supervision signal (label) for training the network. The encoder network can then be extracted and used as a starting point to build your classifier, using one of the transfer learning techniques discussed in the section above.
Similarly, another form of generative networks - Generative Adversarial Networks (GANs) - can be used for pretraining on unlabeled data. Then, a discriminator can be adopted and further fine-tuned for the classification task.
Discriminative Methods
Discriminative approaches train a neural network to learn an auxiliary classification task. An auxiliary task is chosen such that the supervision signal can be derived from the data itself, without human annotation.
Examples of this type of tasks are learning the relative positions of image patches, colorizing grayscale images, or learning the geometric transformations applied on images. We will discuss two of them in further detail.
Learning Relative Positions of Image Patches
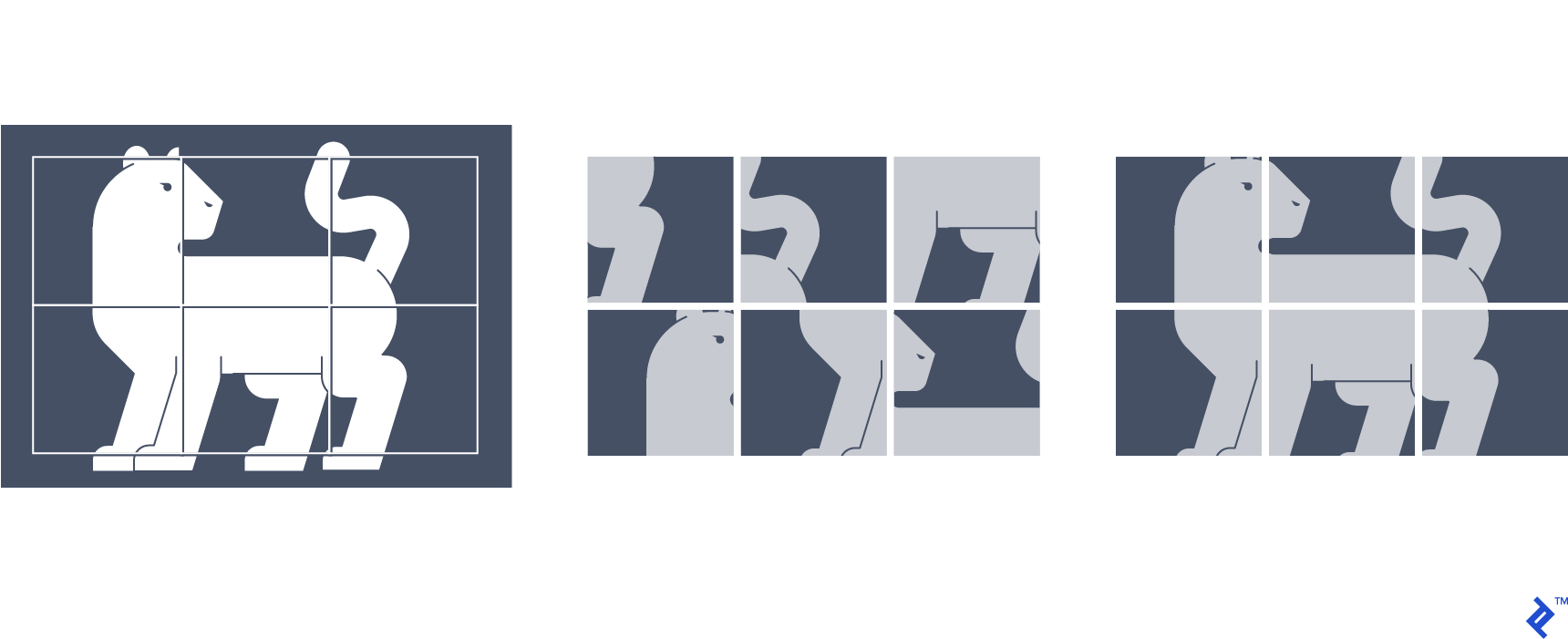
In this technique, image patches are extracted from the source image to form a jigsaw puzzle-like grid. The path positions are shuffled, and shuffled input is fed into the network, which is trained to correctly predict the location of each patch in the grid. Thus, the supervision signal is the actual position of each path in the grid.
In learning to do that, the network learns the relative structure and orientation of objects as well as the continuity of low-level visual features like color. The results show that the features learned by solving this jigsaw puzzle are highly transferable to tasks like image classification and object detection.
Learning Geometric Transformations Applied to Images
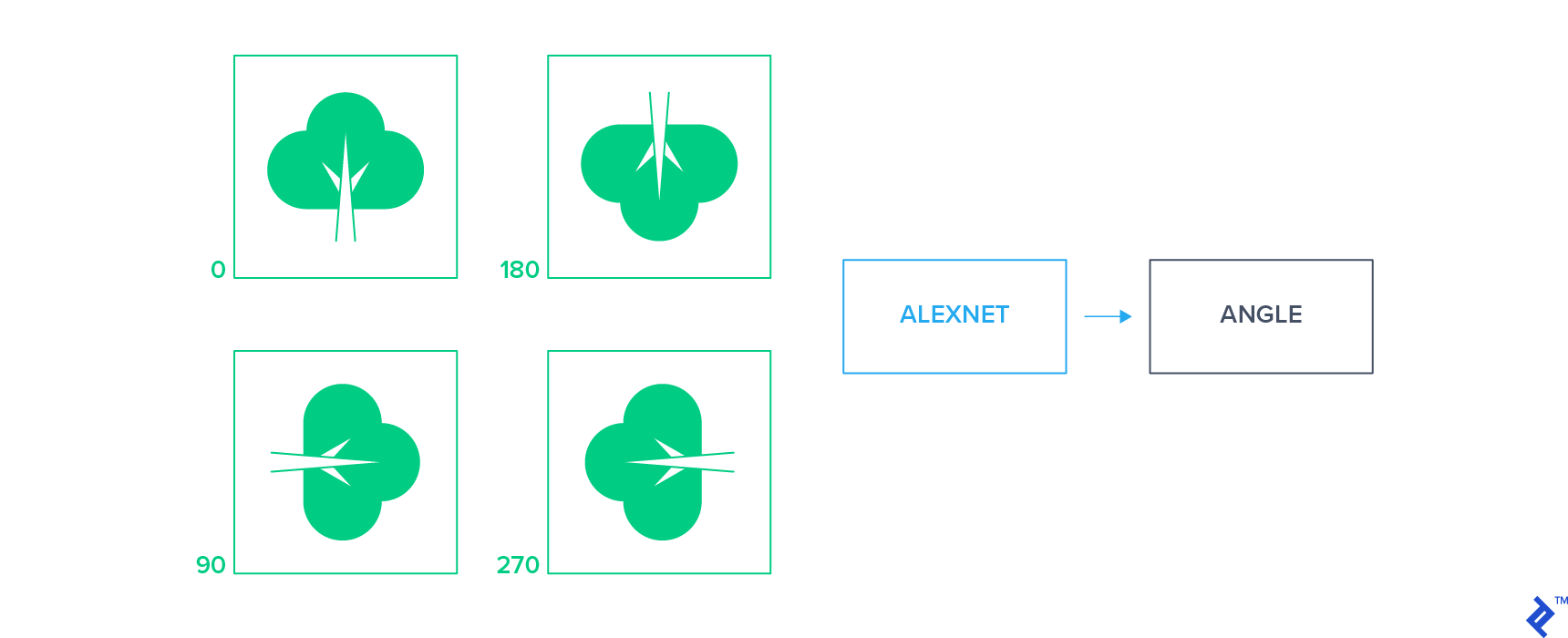
These approaches apply a small set of geometric transformations to the input images and train a classifier to predict the applied transformation by looking at the transformed image alone. One example of these approaches is to apply a 2D rotation to the unlabeled images to obtain a set of rotated images and then train the network to predict the rotation of each image.
This simple supervision signal forces the network to learn to localize the objects in an image and understand their orientation. Features learned by these approaches have proven to be highly transferable and yield state of the art performance for classification tasks in semi-supervised settings.
Similarity-based Approaches
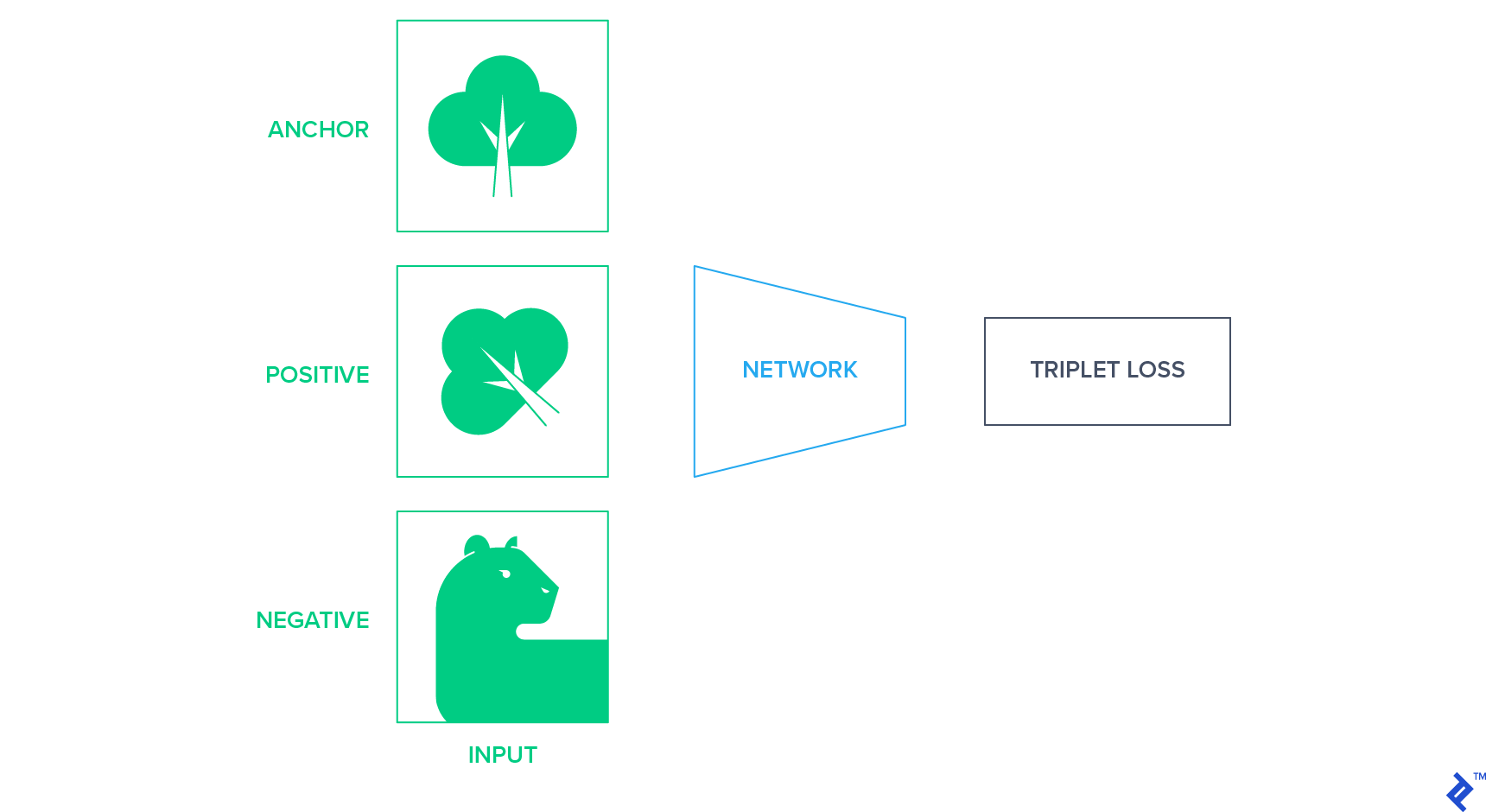
These approaches project the images into a fixed-sized representation space where similar images are closer together and different images are further apart. One way to achieve this is to use siamese networks based on triplet loss, which minimizes the distance between semantically similar images. Triplet loss needs an anchor, a positive example, and a negative example and tries to bring positive closer to the anchor than negative in terms of Euclidean distance in latent space. Anchor and positive are from the same class, and the negative example is chosen randomly from the remaining classes.
In unlabeled data, we need to come up with a strategy to produce this triplet of anchor positive and negative examples without knowing the classes of images. One way to do so is to use a random affine transformation of the anchor image as a positive example and randomly select another image as a negative example.
Experiment
In this section, I will relate an experiment that empirically establishes the potential of unsupervised pre-training for image classification. This was my semester project for a Deep Learning class I took with Yann LeCun at NYU last spring.
- Dataset. It is composed of 128K labeled examples, half of which are for training and the other half for validation. Furthermore, we are provided 512K unlabeled images. The data contains 1,000 classes in total.
- Unsupervised pre-training. AlexNet was trained for rotation classification using extensive data augmentation for 63 epochs. We used the hyperparameters documented by Rotnet in their paper.
- Classifier training. Features were extracted from the fourth convolution layer, and three fully connected layers were appended to it. These layers were randomly initialized and trained with a scheduled decreasing learning rate, and early stopping was implemented to stop training.
- Whole network fine-tuning. Eventually, we fine-tuned the network trained on the entire labeled data. Both the feature extractor and the classifier, which were separately trained before, were fine-tuned together with a small learning rate for 15 epochs.
We trained seven models, each using a different number of labeled training examples per class. This was done to understand how the size of the training data influences the performance of our semi-supervised setup.
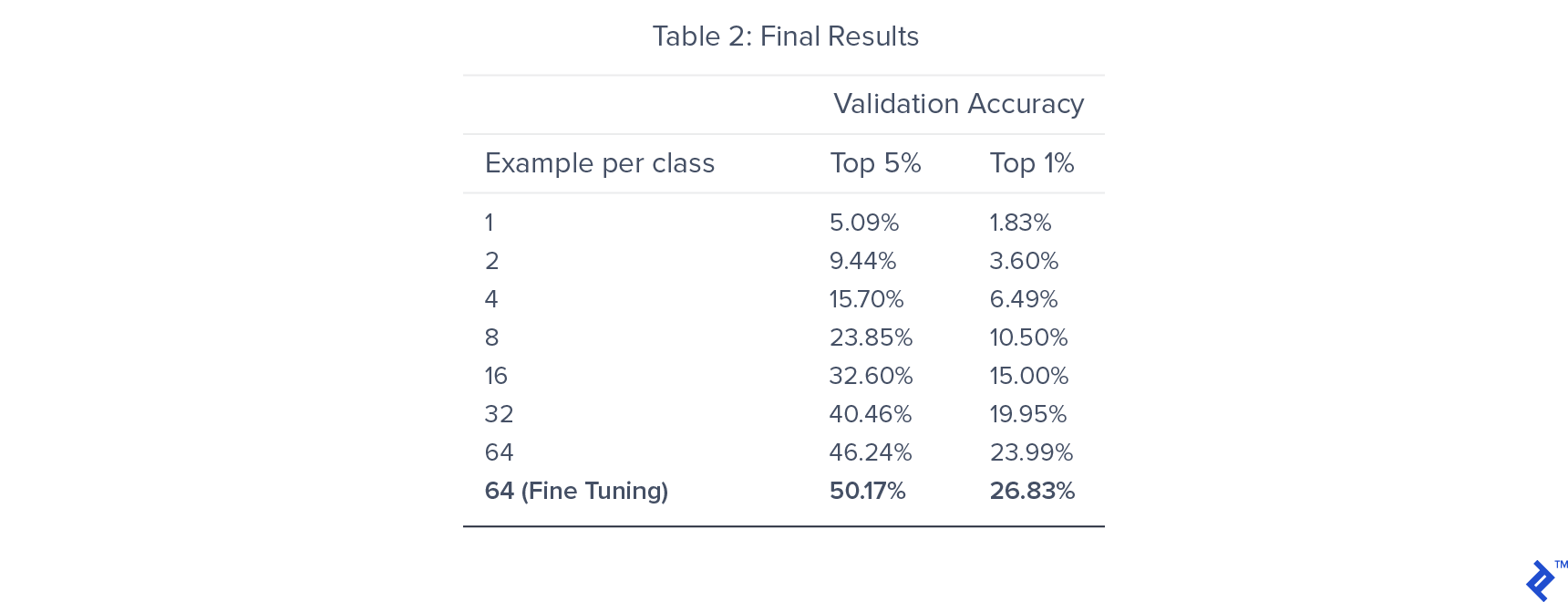
We were able to get an 82% accuracy rate for pre-training on rotation classification. For classifier training, the top 5% accuracy saturated around the value of 46.24%, and fine-tuning of the entire network yielded the final figure of 50.17%. By leveraging the pre-training, we got better performance than that of supervised training, which gives 40% top 5 accuracy.
As expected, the validation accuracy decreases with the decrease in labeled training data. However, the decrease in performance is not as significant as one would expect in a supervised setting. A 50% decrease in training data from 64 examples per class to 32 examples per class only results in a 15% decrease in the validation accuracy.
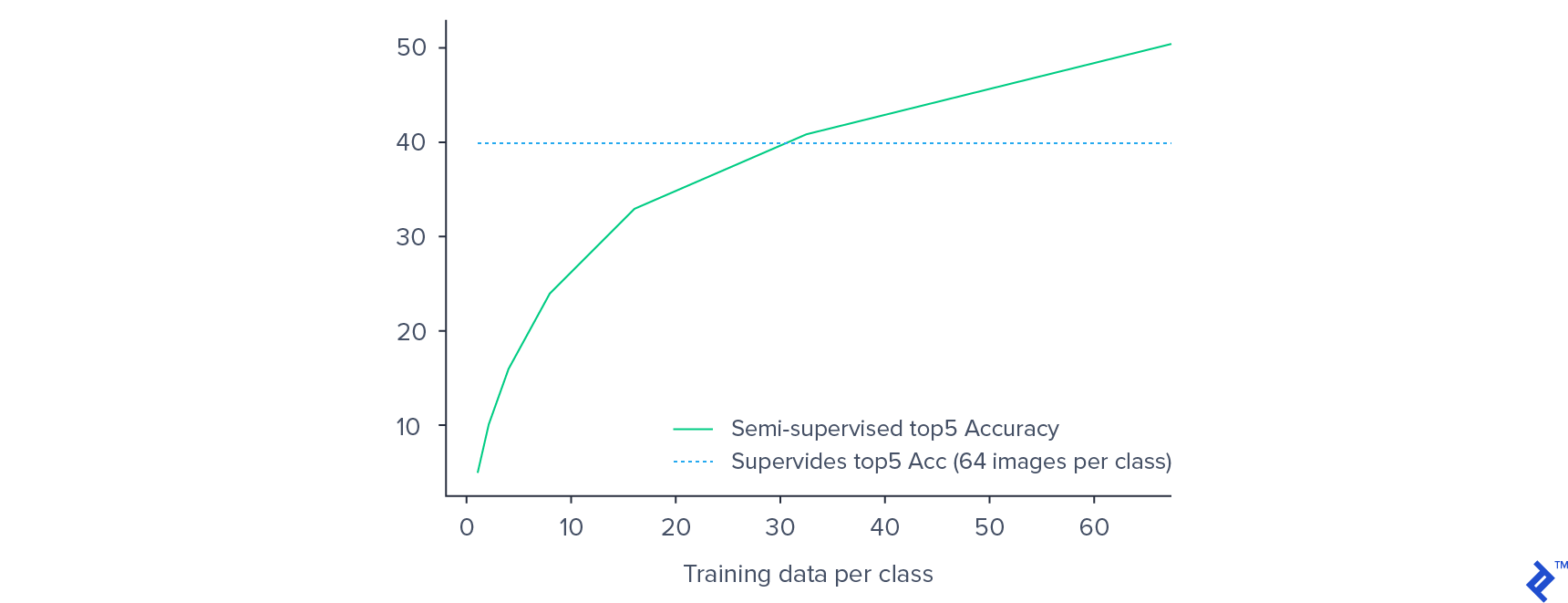
By using only 32 examples per class, our semi-supervised model achieves superior performance to the supervised model trained using 64 examples per class. This provides empirical evidence of the potential of semi-supervised approaches for image classification on low-resource labeled datasets.
Wrapping Up
We can conclude that unsupervised learning is a powerful paradigm that has the capability to boost performance for low-resource datasets. Unsupervised learning is currently in its infancy but will gradually expand its share in the computer vision space by enabling learning from cheap and easily accessible unlabeled data.
Further Reading on the Toptal Blog:
Understanding the basics
How does supervised machine learning work?
In a supervised learning setting, a model is provided with both data and the label, which is usually manually annotated. The model then learns the function that maps the data to the label and hence develops the capability to predict the label, given the data.
What are the supervised learning techniques?
Two categories of supervised machine learning are classification and regression. Regression attempts to map the input data into a continuous variable, while classification maps the input into a discrete variable.
What is the difference between supervised and unsupervised learning?
In supervised learning, we have labeled data that is essential to learning, while in unsupervised learning, we do not need to provide labels.
What is supervised learning in deep learning?
Deep learning is essentially a subset of machine learning, so the same definition of supervised learning applies.
What is supervised and unsupervised image classification?
Supervised image classification maps the images to the labels provided for them. Unsupervised image classification involves the separation of images into groups based on intrinsic similarities and differences between them, without any labeled data.
Urwa Muaz
Lahore, Punjab, Pakistan
Member since November 26, 2019
About the author
Urwa is a Fulbright scholar and data science graduate from NYU. He loves leveraging machine learning to solve practical problems.
Expertise
PREVIOUSLY AT