


Optimizing Cloudera Data Engineering Autoscaling Performance
Cloudera
SEPTEMBER 2, 2021
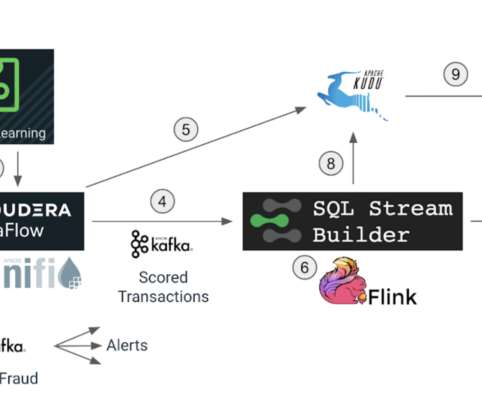
Normally on-premises, one of the key challenges was how to allocate resources within a finite set of resources (i.e., When building CDE, we integrated with Apache YuniKorn which offers rich scheduling capabilities on Kubernetes. . We tested the scaling capabilities of CDE with the following job runs to mimic a real-world scenario: .




















Let's personalize your content