

Optimized joins & filtering with Bloom filter predicate in Kudu
Cloudera
JANUARY 15, 2021
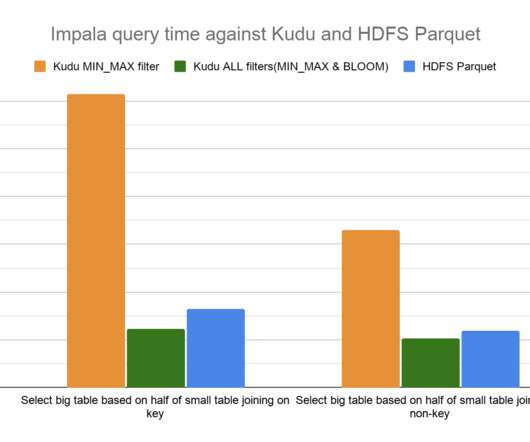
One of the ways Apache Kudu achieves this is by supporting column predicates with scanners. Pushing down column predicate filters to Kudu allows for optimized execution by skipping reading column values for filtered out rows and reducing network IO between a client, like the distributed query engine Apache Impala, and Kudu.









Let's personalize your content