
Ethan Batraski
More posts from Ethan Batraski
Thanks to the cloud, the amount of data being generated and stored has exploded in scale and volume.
Every aspect of the enterprise is being instrumented for data, so new operations are built based on that data, pushing every company into becoming a data company.
One of the most profound and maybe non-obvious shifts driving this is the emergence of the cloud database. Services such as Amazon S3, Google BigQuery, Snowflake and Databricks have solved computing on large volumes of data and have made it easy to store data from every available source.
The enterprise wants to store everything they can in the hopes of being able to deliver improved customer experiences and new market capabilities.
It’s a good time to be a database company
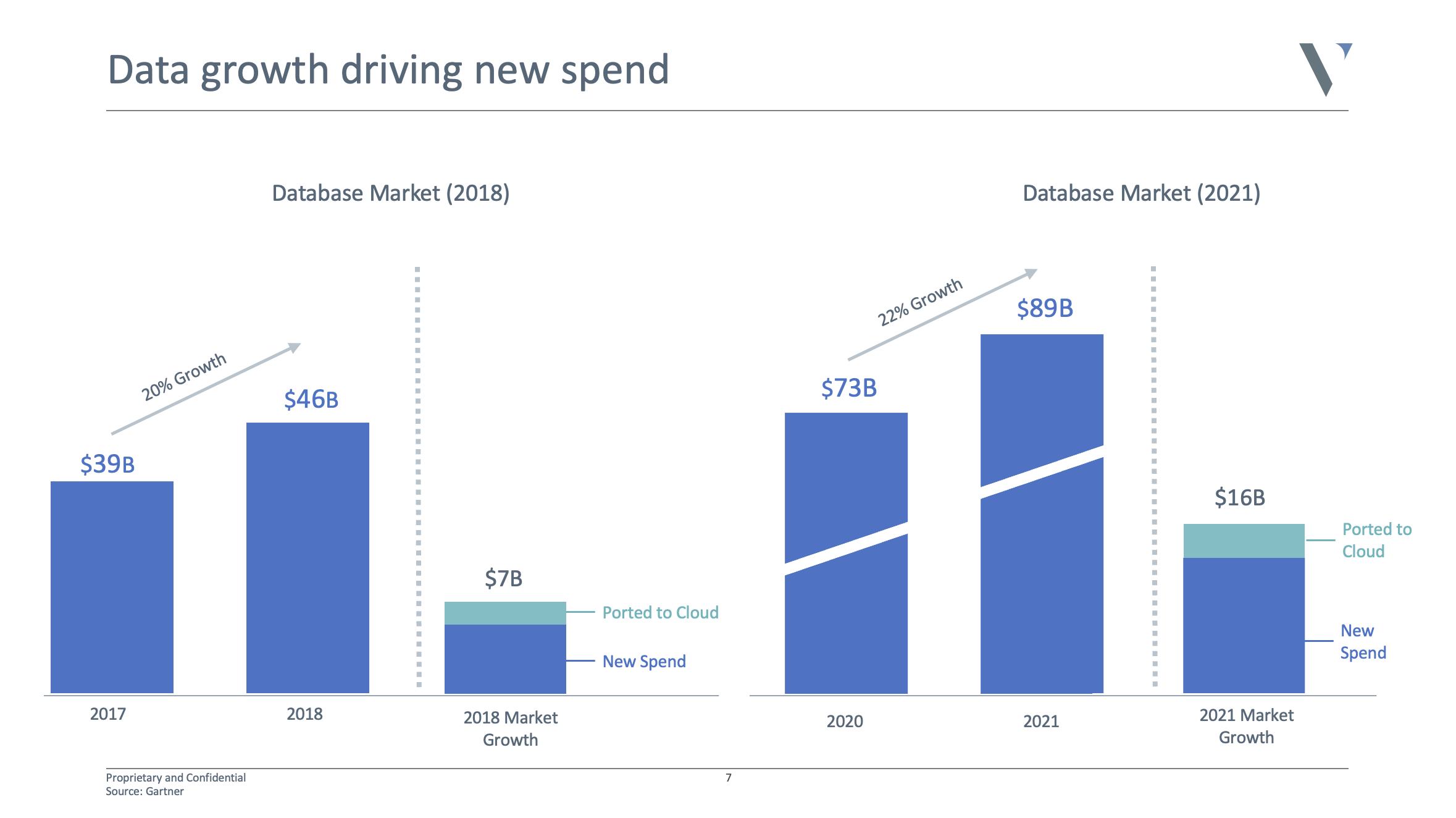
Database companies have raised over $8.7 billion over the last 10 years, with almost half of that, $4.1 billion, just in the last 24 months, according to CB Insights.
It’s not surprising given the sky-high valuations of Snowflake and Databricks. The market doubled in the last four years to almost $90 billion, and is expected to double again over the next four years. It’s safe to say there is a huge opportunity to go after.
See here for a solid list of database financings in 2021.
20 years ago, you had one option: A relational database
Today, thanks to the cloud, microservices, distributed applications, global scale, real-time data and deep learning, new database architectures have emerged to solve for new performance requirements.
We now have different systems for fast reads and fast writes. There are also systems specifically to power ad-hoc analytics or for data that is unstructured, semi-structured, transactional, relational, graph or time-series, as well as for data used for cache, search, based on indexes, events and more.
Each system comes with different performance needs, including high availability, horizontal scale, distributed consistency, failover protection, partition tolerance and being serverless and fully managed.
As a result, enterprises, on average, store data across seven or more different databases. For example, you may have Snowflake as your data warehouse, Clickhouse for ad-hoc analytics, Timescale for time-series data, Elastic for their search data, S3 for logs, Postgres for transactions, Redis for caching or application data, Cassandra for complex workloads and Dgraph* for relationship data or dynamic schemas.
That’s all assuming you are collocated to a single cloud and you’ve built a modern data stack from scratch.
The level of performance and guarantees from these services and platforms is on a very different level compared with what we had five to 10 years ago. At the same time, the proliferation and fragmentation of the database layer are increasingly creating new challenges.
For example, syncing across different schemas and systems, writing new ETL jobs to bridge workloads across multiple databases, constant cross-talk and connectivity issues, the overhead of managing active-active clustering across so many different systems, or data transfers when new clusters or systems come online. Each of these has different scaling, branching, propagation, sharding and resource requirements.
What’s more, we now have new databases every month that aim to solve the next challenge of enterprise scale.
The new-age database
So the question is, will the future of the database continue to be defined as it is today?
I’d make the case that it shouldn’t. Instead, I hope the next generation of databases will look very different from the last.
They should have the following capabilities:
- Primarily compute, query and/or be infrastructure engines that can sit on top of commodity storage layers.
- No migration or restructuring of the underlying data should be required.
- No rewriting or parsing of queries should be needed.
- Work on top of multiple storage engines, whether columnar, non-relational or graph.
- Moves the complexity of configuration, availability and scale into code.
- Allows applications to call into a single interface, regardless of the underlying data infrastructure.
- Works out of the box as a serverless or managed service.
- Be built for developer-first experiences in both single-player and multiplayer modes.
- Deliver day-zero value for both existing (brownfield) and new (greenfield) projects.
There are many secular trends driving this future
No one wants to migrate to a new database
The cost of every new database introduced into an organization is equal to N2 to the cost of the number of databases you already have. Migrating to a new architecture, schema or configuration and having to re-optimize for rebalancing, query planning, scaling and resource requirements means the value derived after the cost and spend is close to zero.
It may come as a surprise, but there are still billions of dollars in Oracle instances still powering critical apps today, and they likely aren’t going anywhere.
A majority of the killer features won’t be in the storage layer
Separating compute and storage has increasingly enabled new levels of performance, allowing for super cheap raw storage and finely tuned, elastically scaled compute, query and infrastructure layers.
The storage layer can be at the center of data infrastructure and leveraged in various different ways by multiple tools to solve routing, parsing, availability, scale, translation and more.
The database is slowly unbundling into highly specialized services
It is moving away from the overly complex, locked-in approaches of the past. No single database can solve transactional and analytical use cases fully with fast reads and writes, high availability and consistency, all while solving caching at the edge and scaling horizontally as needed.
But separating the database into a set of layers sitting on top of the storage engine can introduce a set of new services to deliver new levels of performance and guarantees.
For example, you can have a dynamic caching service that can optimize caches based on user, query and data awareness; manage sharding based on data distribution query demand and data change rates; introduce a proxy layer to enable high availability and horizontal scale with connection pooling and resource management; add a data management framework to solve async and sync propagation between schemas; or introduce translation layers between GraphQL and relational databases.
Scale and simplicity have been trade-offs so far
Postgres, MySQL and Cassandra are very powerful but difficult to get right. Firebase and Heroku are super easy to use but don’t scale.
These database technologies have massive install bases and robust engines and have withstood the test of time at Facebook and Netflix-level scales. But tuning them for your needs often requires a Ph.D. and a team of database experts, as teams at Facebook, Netflix, Uber, Airbnb all have.
The rest of us struggle with consistency and isolation, sharding, locking, clock skews, query planning, security, networking, etc. What companies like Supabase and Hydras are doing in leveraging standard Postgres installs but building powerful compute and management layers on top, allows for the power of Postgres, but with the simplicity of Firebase or Heroku.
The database index model hasn’t changed in 30+ years
Today, we rely on general-purpose, one-size-fits-all indexes such as B-trees and hash maps, taking a black-box view of our data. Being more data aware, like leveraging a cumulative distribution function (CDF) as we’ve seen with Learned Indexes, can lead to smaller indexes, faster lookups, increased parallelism and lower CPU usage.
We’ve barely even begun to demonstrate next-generation indexes that have adapted both to the shape and changes of our data.
There is little to no machine learning used to improve database performance
Instead, today we define static rule sets and configurations to optimize query performance, cost modeling and workload forecasting. These combinatorial, multidimensional problem sets are too complex for humans to configure and are perfect machine learning problems.
Resources such as disk, RAM and CPU are well characterized, query history is well understood and data distribution can be defined. We could see 10x step-ups in query performance, cost and resource utilization, and never see another nested loop join again.
Data platform and engineering teams don’t want to be DBAs, DevOps or SREs
They want their systems and services to just work out of the box and not have to think about resources, connection pooling, cache logic, vacuuming, query planning, updating indexes and more. Teams today want a robust set of end points that are easy to deploy — and just work.
The need for operational real-time data is driving a need for hybrid systems
Transactional systems can write new records into a table rapidly at a high level of accuracy, speed and reliability. An analytics system can search across a set of tables and data rapidly to find an answer.
With streaming data and the need for faster responsiveness in analytical systems, the idea of HTAP (hybrid transaction/analytical processing) systems is emerging, particularly for use cases that are highly operational in nature. This means a very high level of new writes/records and more responsive telemetry or analytics on business metrics. This introduces a new architectural paradigm in which transactional and analytical data and systems start to reside much closer to each other but not together.
A new category of cloud database companies is emerging, effectively deconstructing the traditional database monolith stack into core layered services — storage, compute, optimization, query planning, indexing, functions and more. Companies like ReadySet, Hasura, Xata, OtterTune, Apollo and PolyScale are examples of this movement and quickly becoming the new developer standard.
These new unbundled databases are focused on solving the hard problems of caching, indexes, scale and availability, and are beginning to remove the trade-off between performance and guarantees. Fast databases that are always on, can handle mass scale and are data aware are blurring the lines between the traditional divisions between operational and analytical systems. The future looks bright.

























Comment