






Large language models like ChatGPT and Bard have raised machine learning to the status of a phenomenon. Their use for coding assistance has quickly earned these tools a place in the developer’s toolkit. Other use cases are being explored, ranging from image generation to disease detection.
Tech companies are investing heavily in machine learning, so knowing how to train and work with models is becoming essential for developers.
This article gets you started with machine learning in Java. You will get a first look at how machine learning works, followed by a short guide to implementing and training a machine learning algorithm. We'll focus on supervised machine learning, which is the most common approach to developing intelligent applications.
Machine learning and AI
Machine learning has evolved from the field of artificial intelligence (AI), which seeks to produce machines capable of mimicking human intelligence. Although machine learning is a hot trend in computer science, AI is not a new field in science. The Turing test, developed by Alan Turing in the early 1950s, was one of the first tests created to determine whether a computer could have real intelligence. According to the Turing test, a computer could prove human intelligence by tricking a human into believing it was also human.
Many state-of-the-art machine learning approaches are based on decades-old concepts. What has changed over the past decade is that computers (and distributed computing platforms) now have the processing power required for machine learning algorithms. Most machine learning algorithms demand a huge number of matrix multiplications and other mathematical operations to process. The computational technology to manage these calculations didn't exist even two decades ago, but it does today. Parallel processing and dedicated chips, as well as big data, have radically increased the capacity of machine learning platforms.
Machine learning enables programs to execute quality improvement processes and extend their capabilities without human involvement. Some programs built with machine learning are even capable of updating or extending their own code.
How machines learn
Supervised learning and unsupervised learning are the most popular approaches to machine learning. Both require feeding the machine a massive number of data records to correlate and learn from. Such collected data records are commonly known as a feature vectors. In the case of an individual house, a feature vector might consist of features such as overall house size, number of rooms, and the age of the house.
Supervised learning
In supervised learning, a machine learning algorithm is trained to correctly respond to questions related to feature vectors. To train an algorithm, the machine is fed a set of feature vectors and an associated label. Labels are typically provided by a human annotator and represent the right answer to a given question. The learning algorithm analyzes feature vectors and their correct labels to find internal structures and relationships between them. Thus, the machine learns to correctly respond to queries.
As an example, an intelligent real estate application might be trained with feature vectors including the respective size, number of rooms, and age of a range of houses. A human labeller would label each house with the correct house price based on these factors. By analyzing the data, the real estate application would be trained to answer the question, "How much money could I get for this house?"
After the training process is over, new input data is not labeled. The machine is able to correctly respond to new queries, even for unseen, unlabeled feature vectors.
Unsupervised learning
In unsupervised learning, the algorithm is programmed to predict answers without human labeling, or even questions. Rather than predetermine labels or what the results should be, unsupervised learning harnesses massive data sets and processing power to discover previously unknown correlations. In consumer product marketing, for instance, unsupervised learning could be used to identify hidden relationships or consumer grouping, eventually leading to new or improved marketing strategies.
This article focuses on supervised machine learning, which is currently the most common approach to machine learning.
A supervised machine learning project
Now let's look at an example: a supervised learning project for a real estate application.
All machine learning is based on data. Essentially, you input many instances of data and the real-world outcomes of that data, and the algorithm forms a mathematical model based on those inputs. The machine eventually learns to use new data to predict unknown outcomes.
For a supervised machine learning project, you will need to label the data in a meaningful way for the outcome you are seeking. In Table 1, note that each row of the house record includes a label for "house price." By correlating row data to the house price label, the algorithm will eventually be able to predict market price for a house not in its data set (note that house size is based on square meters, and house price is based on euros).
Table 1. House records
| FEATURE | FEATURE | FEATURE | LABEL |
| Size of House | Number of Rooms | Age of House | Estimated Cost |
|
90 m2 / 295 ft |
2 | 23 years |
249,000 € |
|
101 m2 / 331 ft |
3 | N/A |
338,000 € |
|
1330 m2 / 4363 ft |
11 | 12 years |
6,500,000 € |
In the early stages, you will likely label the data records by hand, but you could eventually train your program to automate this process. You've probably seen this with email applications, where moving email into your spam folder results in the query "Is this spam?" When you respond, you are training the program to recognize mail that you don't want to see. The application's spam filter learns to label and dispose of future mail from the same source or containing similar content.
Labeled data sets are only required for training and testing purposes. After this phase is over, the machine learning model works on unlabeled data instances. For instance, you could feed the prediction algorithm a new, unlabeled house record and it would automatically predict the expected house price based on training data.
Training a machine learning model
The challenge of supervised machine learning is to find the proper prediction function for a specific question. Mathematically, the challenge is to find the input/output function that takes the input variable x and returns the prediction value y. This hypothesis function (hθ) is the output of the training process. Often, the hypothesis function is also called target or prediction function.
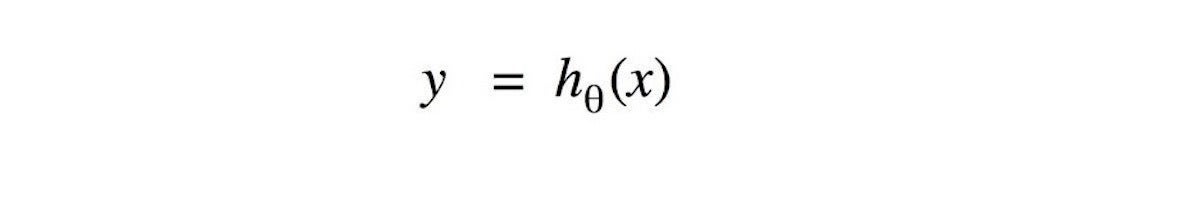 Gregor Roth
Gregor Roth
Figure 1. Example of a target function
In most cases, x represents a multiple-data point. In our example, this could be a two-dimensional data point of an individual house defined by the house-size value and the number-of-rooms value. The array of these values is referred to as the feature vector. Given a concrete target function, the function can be used to make a prediction for each feature vector, x. To predict the price of an individual house, you could call the target function by using the feature vector { 101.0, 3.0 }, which contains the house size and the number of rooms:
Listing 1. Calling the target function with a feature vector
// target function h (which is the output of the learn process)
Function<Double[], Double> h = ...;
// set the feature vector with house size=101 and number-of-rooms=3
Double[] x = new Double[] { 101.0, 3.0 };
// and predicted the house price (label)
double y = h.apply(x);
In Listing 1, the array variable x value represents the feature vector of the house. The y value returned by the target function is the predicted house price.
The challenge of machine learning is to define a target function that will work as accurately as possible for unknown, unseen data instances. In machine learning, the target function (hθ) is sometimes called a model. This model is the result of the learning process, also called model training.
 Gregor Roth
Gregor Roth
Figure 2. A machine learning model
Based on labeled training examples, the learning algorithm looks for structures or patterns in the training data. It does this with a process known as back propagation, where values are gradually modified to reduce loss. From these, it produces a model that is able to generalize from that data.
Typically, the learning process is explorative. In most cases, the process will be executed multiple times using different variations of learning algorithms and configurations. When a model is settled upon, the data is run through it many times as well. These iterations are known as epochs.
Eventually, all the models will be evaluated based on performance metrics. The best one will be selected and used to compute predictions for future unlabeled data instances.
Linear regression
To train a machine to think, the first step is to choose the learning algorithm you'll use. Linear regression is one of the simplest and most popular supervised learning algorithms. This algorithm assumes that the relationship between input features and the output label is linear. The generic linear regression function in Figure 3 returns the predicted value by summarizing each element of the feature vector multiplied by a theta parameter (θ). The theta parameters are used within the training process to adapt or "tune" the regression function based on the training data.
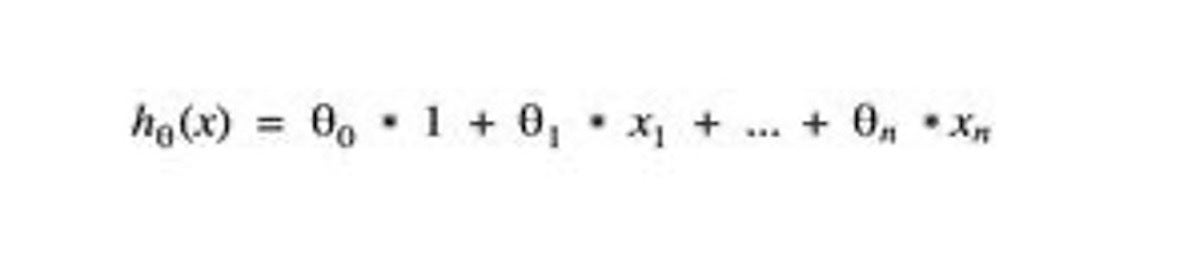 Gregor Roth
Gregor Roth
Figure 3. A generic linear regression function
Linear regression is a simple kind of learning function, but it provides a good basis for the more advanced forms like gradient descent, which is used in feed forward neural networks. In the linear regression function, theta parameters and feature parameters are enumerated by a subscription number. The subscription number indicates the position of theta parameters (θ) and feature parameters (x) within the vector. Note that feature x0 is a constant offset term set with the value 1 for computational purposes. As a result, the index of a domain-specific feature such as house-size will start with x1. So, if x1 is set for the first value of the House feature vector, house-size, then x2 will be set for the next value, number-of-rooms, and so forth.
Listing 2 shows a Java implementation of this linear regression function, shown mathematically as hθ(x). For simplicity, the calculation is done using the data type double. Within the apply() method, it is expected that the first element of the array has been set with a value of 1.0 outside of this function.
Listing 2. Linear regression in Java
public class LinearRegressionFunction implements Function<Double[], Double> {
private final double[] thetaVector;
LinearRegressionFunction(double[] thetaVector) {
this.thetaVector = Arrays.copyOf(thetaVector, thetaVector.length);
}
public Double apply(Double[] featureVector) {
// for computational reasons the first element has to be 1.0
assert featureVector[0] == 1.0;
// simple, sequential implementation
double prediction = 0;
for (int j = 0; j < thetaVector.length; j++) {
prediction += thetaVector[j] * featureVector[j];
}
return prediction;
}
public double[] getThetas() {
return Arrays.copyOf(thetaVector, thetaVector.length);
}
}
In order to create a new instance of the LinearRegressionFunction, you must set the theta parameter. The theta parameter, or vector, is used to adapt the generic regression function to the underlying training data. The program's theta parameters will be tuned during the learning process, based on training examples. The quality of the trained target function can only be as good as the quality of the given training data.
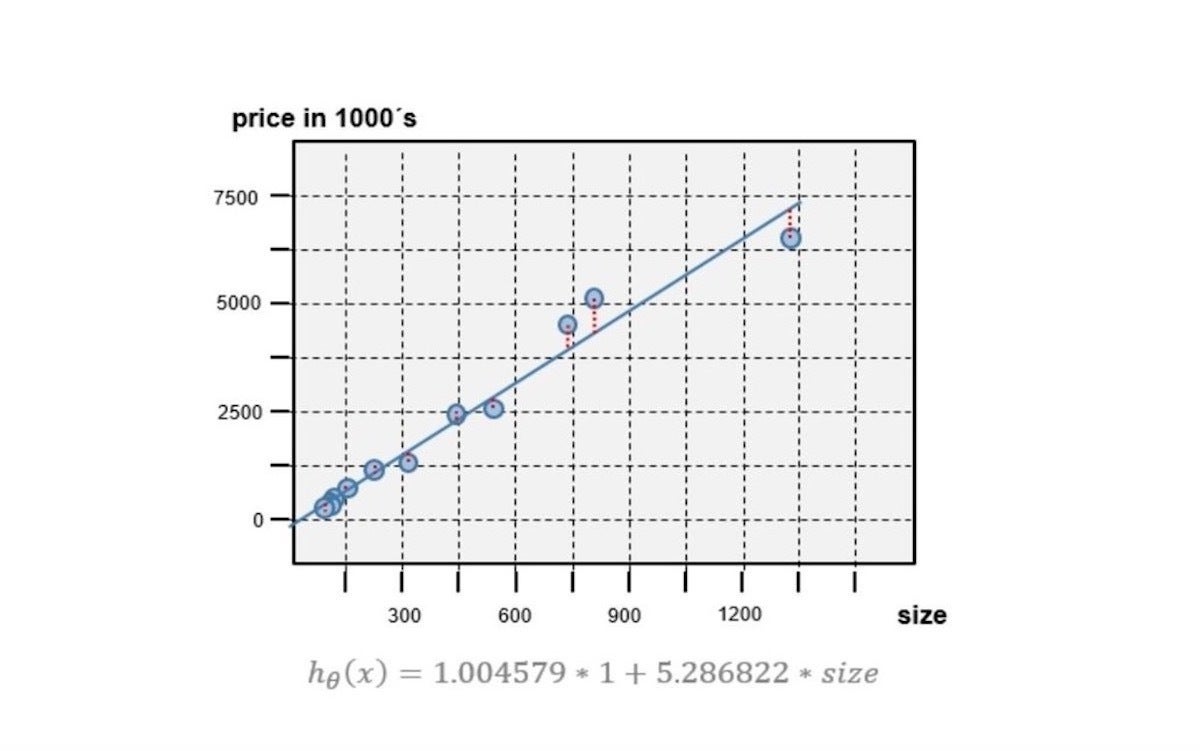
In the next example, the LinearRegressionFunction will be instantiated to predict the house price based on house size. Considering that x0 has to be a constant value of 1.0, the target function is instantiated using two theta parameters. The theta parameters are the output of a learning process. After creating the new instance, the price of a house with size of 1330 square meters will be predicted as follows:
// the theta vector used here was output of a train process
double[] thetaVector = new double[] { 1.004579, 5.286822 };
LinearRegressionFunction targetFunction = new LinearRegressionFunction(thetaVector);
// create the feature vector function with x0=1 (for computational reasons) and x1=house-size
Double[] featureVector = new Double[] { 1.0, 1330.0 };
// make the prediction
double predictedPrice = targetFunction.apply(featureVector);
The target function's prediction line is shown as a blue line in Figure 4. The line has been computed by executing the target function for all the house-size values. The chart also includes the price-size pairs used for training.
 Gregor Roth
Gregor Roth
Figure 4. The target function's prediction line