




In today’s digital age, the resilience of software and technology is vital to the success of any business. Organizations must continuously adapt and prepare for potential disruptions and system failures. This post will explore ways to achieve greater resilience holistically and encourage a culture of technology resilience.
Succeed as a Team and Fail as a Team
In a resilient organization, teams and managers prioritize problem-solving and prevention over assigning blame when issues arise. Encouraging a culture where team members feel safe to expose vulnerabilities, weaknesses, and even individual mistakes is essential for building stronger, more resilient software and technology organizations. Celebrating those who identify these areas for improvement fosters a positive environment that prioritizes resilience.
A blame-free culture also encourages open communication and transparency, facilitating faster problem resolution and improving overall system stability. When team members are empowered to discuss issues and work together to find solutions, it creates a stronger sense of ownership and responsibility.
Listen to Your Metrics, They Don’t Lie
Resilient teams use metrics to measure their performance and identify areas for improvement. By closely monitoring incidents they created or those with recurring root causes, teams learn from their mistakes and work towards developing more resilient solutions.
Metrics can include system uptime, incident response time, mean time to recovery (MTTR), and mean time between failures (MTBF) – as well as any industry or domain-specific metrics that affect the business or operations. By analyzing these metrics, teams can identify trends, weaknesses, and areas for improvement. Regularly reviewing and adjusting metrics ensures that teams are always working towards greater resilience.
Tabletop Exercises Help to Play the Tape Forward
Preparing for potential problems is a critical aspect of building resilience. Teams should practice their response to complete system outages, severe scaling problems, or the impact of losing access to a dependency, starting with individual applications and moving up to entire services. This iterative process helps teams become more adept at handling crises when they occur.
Outage rehearsals can involve tabletop exercises, simulations, or even real-life drills. By practicing their response to various scenarios, teams can identify gaps in their plans and make adjustments to improve their resilience. Additionally, rehearsing the outage helps teams better understand their dependencies and interconnections, which can be critical in a crisis. Lastly, it creates a shared responsibility for reliability and incident response, building the team’s confidence in their capacity to address such challenges.
Ruthlessly Prioritize your Systems, Services, and Applications
It is crucial to recognize that not all business services and applications require the same level of resilience. Organizations should first identify their most critical services, which are essential for meeting obligations to customers, business partners, regulators, and operational users. By understanding the technology landscape and the dependencies and interconnections between applications and systems, organizations can assess their current resilience levels and prioritize improvements and the order of operations during a crisis accordingly.
Establishing a clear hierarchy of critical services helps organizations allocate resources more effectively and ensures that the most important systems receive the attention they need. This prioritization also informs decisions about backup and recovery strategies, redundancy, investment in infrastructure, and potential temporary alternatives during an outage event.
Measure Resilience Continually
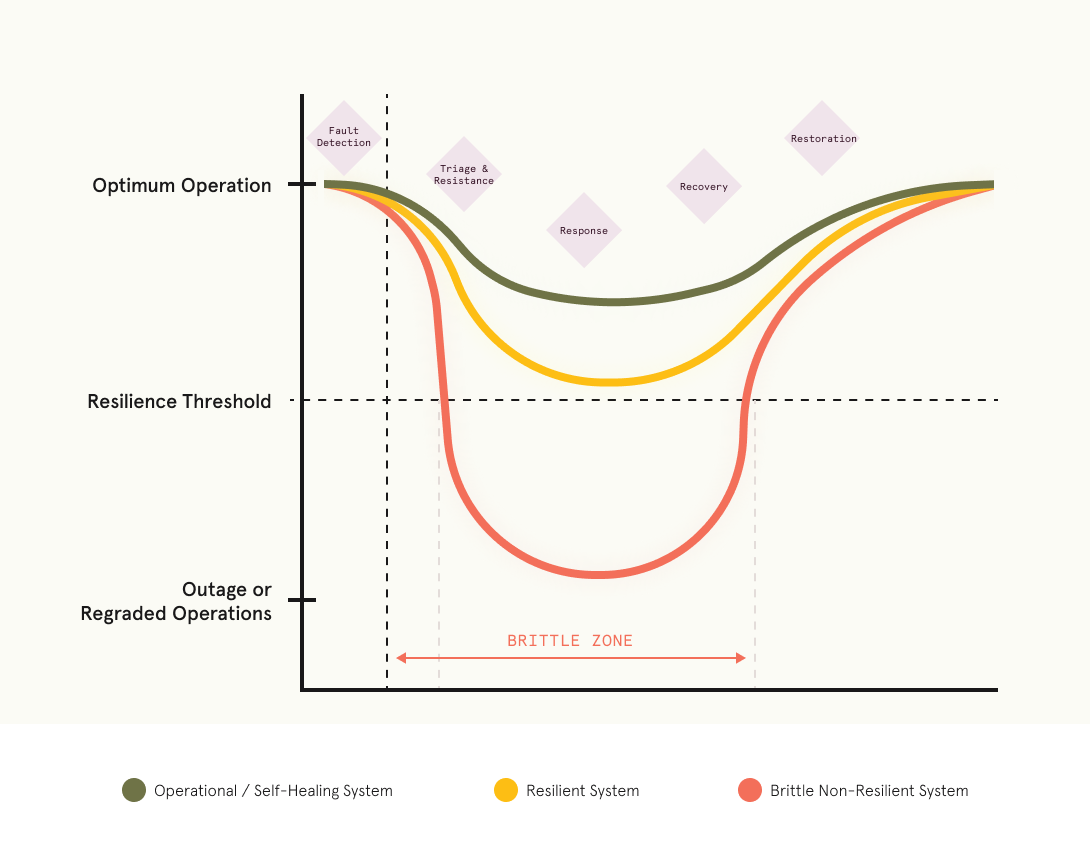
Evaluating existing technology resilience is the next step. Organizations should assess their maturity on an S-curve, examining whether they possess resilient system architecture and software across the stages of a typical outage or service degradation event. Such an assessment may be different for the particulars of your organization but in general the following questions should be answerable on a continuous basis:
- Fault Detection: How quickly can infrastructure or operations teams identify that a fault or outage has occurred? Are the ideal tools in place for notification of such errors to be sent to the correct individuals or teams to handle the issue?
- Triage and Resistance: How long does it take to identify the root cause of issues? How available are mitigating measures to resist catastrophic outcomes such as lost revenue, lost data, etc?
- Response: Does your average response time meet expectations? When a response is necessary is it to pull the system back from the brink or is it an adjustment that allows a speedy recovery?
- Recovery: When a response has been implemented, how quickly does the overall system (or network of systems) take to fully recover? Does your infrastructure support rapid deployment of fixes?
- Restoration: Once restored, are there frequently after-event issues to be resolved, such as ensuring data integrity? Does the team refactor any quick fixes to be more stable over the long-term? What does your post-mortem review process look like and is it effective?
The most mature organizations incorporate technology resilience into application and system architecture by design. In deployment and operations, resilient operations should consider not only operational contingencies but also the root cause of incidents that arise during business as usual to improve procedures, training, and technology solutions. Monitoring and validation involve reactive or backward-looking metrics at lower maturity levels. At higher maturity levels, organizations shift to proactive measures to look for early indicators of resilience issues and test responses and contingency plans for the most likely eventualities.
Reviewing and Learning from Past Incidents
In addition to assessing the current level of resilience, organizations should analyze past technology-related incidents to uncover common factors that can be addressed to improve resilience. This process involves reviewing incident reports, logs, and other documentation, as well as interviewing those involved in the incident and response. By conducting a thorough review of past incidents, organizations can identify trends and patterns that may indicate areas of weakness or vulnerability.
When analyzing past crises, it is essential to consider both internal and external factors. Internal factors may include outdated systems, insufficient training, or a lack of standard operating procedures. External factors could involve supply chain disruptions, natural disasters, or cyberattacks.
Understanding the full context of past crises helps organizations develop more comprehensive resilience strategies. Moreover, learning from past incidents enables organizations to implement necessary changes, improve their overall resilience, and be better prepared for future challenges. This proactive approach to reviewing and learning from past crises is a vital component of building a resilient organization.
Cross-Functional Remediation
After identifying gaps in technology resilience, organizations must work to remediate them. This process often requires a cross-functional approach, with collaboration between different departments and teams to ensure that resilience is addressed holistically. Some specific steps include:
- Assigning clear ownership and accountability for technology resilience activities is essential. Distributed systems can have multiple owners, and developers aren’t always incentivized to architect and design for resilience. Applications and systems must have clear ownership, developers need accountability tied to the resilience of the applications they build, and third-party contracts must include resilience/SLA requirements.
- Enhancing governance toward resiliency levels, the C-suite needs to communicate its intention and prioritization of resilience down through all levels of the organization with continuous and consistent messaging.
- Establish dedicated teams composed of representatives from various departments, including IT, operations, and business functions. These teams can work together to address resilience gaps and ensure that all aspects of the organization are aligned in their efforts to improve resilience.
Need help assessing your team’s resilience? Let’s talk.



