

Announcing Cloudera’s Enterprise Artificial Intelligence Partnership Ecosystem
Cloudera
DECEMBER 20, 2023
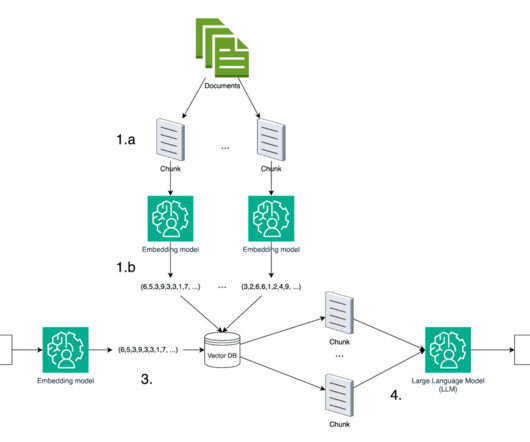
Founding AI ecosystem partners | NVIDIA, AWS, Pinecone NVIDIA | Specialized Hardware Highlights: Currently, NVIDIA GPUs are already available in Cloudera Data Platform (CDP), allowing Cloudera customers to get eight times the performance on data engineering workloads at less than 50 percent incremental cost relative to modern CPU-only alternatives.











Let's personalize your content