Terraform AWS Cloud: Sane Infrastructure Management
Writing an application is only part of the story. In order for it to be of value, it needs deploying somewhere it can scale; it has to run with high availability, have backups, and so on. Deployment and infrastructure management isn’t a simple process. And Terraform does nothing to hide the complexity. However, it does make your infrastructure declarative and reproducible, like your code.
In this article, Toptal Freelance DevOps Engineer Radosław Szalski teaches us what Terraform is, how its components work, and how to configure an entire AWS Cloud solution in minutes using its configuration language.

Writing an application is only part of the story. In order for it to be of value, it needs deploying somewhere it can scale; it has to run with high availability, have backups, and so on. Deployment and infrastructure management isn’t a simple process. And Terraform does nothing to hide the complexity. However, it does make your infrastructure declarative and reproducible, like your code.
In this article, Toptal Freelance DevOps Engineer Radosław Szalski teaches us what Terraform is, how its components work, and how to configure an entire AWS Cloud solution in minutes using its configuration language.

Radosław is a Python enthusiast and full-stack developer with over half a decade of professional experience engineering web apps.
PREVIOUSLY AT

Writing an application is only part of the story. In order for it to be of value, it needs deploying somewhere it can scale, it has to run with high availability, it needs backups, and so on.
More and more developers are required to at least have a grasp on this deployment process. This manifests as, for example, in DevOps becoming an often requested role nowadays, as system complexity grows. We cannot let ourselves ignore those shifts and need to be aware of how to design applications to be easily deployable.
This is also in the interest of our clients: They hire us as experts in our fields and expect us to deliver the whole product, often from start to finish. They have requirements and are often oblivious to the stack their business solution runs on. In the end, it’s the business value of the product that matters.
Introducing Terraform
Deployment and infrastructure management isn’t a simple process. On top of a lot of ever-changing, domain expertise we need to learn Yet Another Tool or a new workflow. If you have been putting this off, this article is a chance for you go get acquainted with one approach to infrastructure management. I hope in the end you will be more confident in using Terraform and know more about the possible approaches and challenges. You should be able to use this tool to at least start managing some part of your cloud infrastructure.
Terraform is an abstraction layer, yes, and abstractions are leaky, I agree. But in the end, we are in the business of solving problems and managing abstractions. This one aims to provide us with more sanity in our day-to day tasks.
The Goal
I will explain what Terraform is, how it fits the whole ecosystem, and how it compares to other, similar tools. Then I’ll show you steps needed to configure a multi-environment and production-ready Terraform setup for a team. I’ll explain the basics of writing Terraform configuration—how to manage complexity and duplicate code with shareable modules.
The examples will all be focused on one cloud provider: Amazon Web Services (AWS). This is just a cloud that I have the most experience with but all the information should apply to other clouds as well.
I’ll end with some notes that I wish I had known when I started: some syntax gotchas, quirks, and cases where Terraform would not be my tool of choice.
I will not focus on nitty gritty details of syntax. You can quickly get up to speed on that by reading fantastic documentation and guides that HashiCorp provides for Terraform. I’d like to focus on things that might not be obvious from the beginning and that I wish I had known before I started working with Terraform. Hopefully, this will point you in the right direction and allow you to consider Terraform as a tool to use in future projects.
Infrastructure Management Is Hard
There are multiple steps involved in setting up an environment for an app in the cloud. Unless you write them all down as detailed checklists and follow them closely, all the time, you will make mistakes; we are human, after all. Those steps are hard to share. You need to document a lot of manual procedures and docs can quickly get outdated. Now multiply all that by the total number of environments for a single app: dev, test/qa, stage, and prod. You also need to think about security for each of them.
Doesn’t Every Tool Have a UI That I Can Use and Forget about the Complexity?
They do have UIs—AWS Management Console is a prime example. But those tools do a lot under the hood. One click on the UI may actually invoke a cascade of changes that are hard to grasp. There is usually no way to undo what you did in the UI (the usual “Are you sure?” prompts are often not enough). Moreover, it’s always a good idea to have a second pair of eyes to check the changes, but when we use UIs we would need to sit with this person together or check our changes after they are made, which is more of an audit than a review. Each cloud provider has their own UI which you need to master. UIs are designed to be easy to use (not necessarily simple!) and as such are prone to delusional approaches such as “this is just a tiny tweak,” or a quick production hotfix that you will forget about in 48 hours. Such manual clicking is also very hard to automate.
What about CLI Tools?
They would be better than UI tools for our use cases. However, you are still prone to doing changes by hand or writing bash scripts which can easily get out of hand. Moreover each provider has their own CLI tools. With those tools, you can’t see your changes before you commit to them. Thankfully this is not a new problem and there are tools that help with this.
Orchestration vs. Configuration Management
I will define some categories of tools and practices that are used to manage infrastructure. These are orchestration and configuration management. You can think of them roughly as declarative and imperative programming models (think Prolog vs. Python). Each has their own pros and cons but it’s best to know them all and apply the best tool for a given job. Also, orchestration usually involves a higher abstraction level than configuration management.
Orchestration
Orchestration resembles more of a declarative programming paradigm. I like to think of it as being the conductor of an orchestra. The work of a conductor is nicely summed up by Wikipedia (link) as “the art of directing the simultaneous performance of several players or singers by the use of gesture.” Conductors communicate the beat and tempo, dynamics, and cueing of the music but the actual work is performed by individual musicians who are experts at playing their musical instruments. Without such coordination, they wouldn’t be able to perform a perfect piece.
This is where Terraform fits. You use it to conduct a piece of IT infrastructure: You tell it what do deploy, and Terraform links it all together and performs all the necessary API calls. There are similar tools in this space; one of the most well-known is AWS Cloud Formation. It has better support for recovery and rollbacks in case of errors than Terraform, but also, in my opinion, a steeper learning curve. It is also not cloud-agnostic: It works only with only with AWS.
Configuration Management
The complementary side of these practices is the configuration management approach. In this paradigm, you specify the exact steps that a tool has to make to arrive at a given, desired configuration. The steps themselves might be small and support multiple operating systems, but you need to actively think about the order of their execution. They have no awareness of current state and surroundings (unless you program them with that) and, as such, will blindly execute whatever steps you give them. This may lead to a problem known as configuration drift, where your resources will slowly desynchronize with what they were intended to represent initially, especially if you made some manual changes to them. They are great at managing and provisioning services on individual instances. Examples of tools that excel at this workflow are Chef, Puppet, Ansible, and Salt.
Orchestration enforces an approach to your infrastructure where you treat your resources as cattle, not as pets. Instead of manually “nurturing” each VPS, you are able to replace them with an exact copy when something goes wrong. I don’t mean that you simply don’t care and restart the thing hoping for the best.

Instead, you should investigate and fix the problem in the code and then deploy it.
Ansible (and other CM tools) can be used to manage AWS infrastructure, but this would involve a lot of work and is more error prone, especially when the infrastructure changes often and grows in complexity.
One important thing to remember is that orchestration and configuration management approaches do not conflict with each other. They are compatible. It is perfectly OK to have a group of EC2 (VPS) instances in an AutoScaling group managed by Terraform but running an AWS Application Image (AMI), which is a snapshot of the disk, that was prepared with imperative steps with, e.g., Ansible. Terraform even has a concept of “providers” that allow you to run external, provisioning tools once a machine boots up.
Terraform documentation makes a great work of explaining this further and helping you place Terraform in the whole ecosystem.
What Is Terraform?
Its an open source tool, created by HashiCorp that allows you to codify your infrastructure as declarative configuration files that are versioned and shared and can be reviewed.
The HashiCorp name should ring a bell—they also make Nomad, Vault, Packer, Vagrant, and Consul. If you have used any of those, tools you already know the quality of documentation, vibrant community, and usefulness that you can expect out of their solutions.
Infrastructure as Code
Terraform is platform-agnostic; you can use it to manage bare metal servers or cloud servers like AWS, Google Cloud Platform, OpenStack, and Azure. In Terraform lingo, these are called providers, You can get a sense of the scale by reading a full list of supported providers. Multiple providers can be used at the same time, for example when provider A configures VMs for you, but provider B configures and delegates DNS records.
Does that mean that one can switch cloud providers with one change in a config file? No, I don’t even think you would want that, at least not in an automated way. The problem is that different providers may have different capabilities, different offerings, flows, ideas, etc. It means you will have to use different resources for a different provider to express the same concept. However, this can all still be done in a single, familiar configuration syntax and be part of a cohesive workflow.
Essential Parts of a Terraform Setup
- The Terraform binary itself, that you have to install
- The source code files, i.e., your configuration
- The state (either local or remote) that represents the resources that Terraform manages (more on that later)
Writing Terraform Configuration
You write Terraform configuration code in *.tf files using the HCL language. There is an option to use JSON format (*.tf.json), but it’s targeted at machines and auto generation rather than humans. I recommend that you stick with HCL. I won’t dive deep into the syntax of HCL language; the official docs do a fantastic job of describing how to write HCL and how to use variables and interpolations. I’ll only mention the bare minimum needed to understand the examples.
Inside Terraform files, you are mostly dealing with resources and data sources. Resources represent components of your infrastructure, e.g., an AWS EC2 instance, an RDS instance, a Route53 DNS record, or a rule in a security group. They allow you to provision and change them inside the cloud architecture.
Assuming you have set Terraform up, if you issue a terraform apply, the code below would create a fully functional EC2 instance (only certain properties are shown):
resource "aws_instance" "bastion" {
ami = "ami-db1688a2" # Amazon Linux 2 LTS Candidate AMI 2017.12.0 (HVM), SSD Volume Type - ami-db1688a2
instance_type = "t2.nano"
key_name = "${var.key_name}"
subnet_id = "${module.network.public_subnets[0]}"
vpc_security_group_ids = ["${aws_security_group.bastion.id}"]
monitoring = "false"
associate_public_ip_address = "true"
disable_api_termination = "true"
tags = {
Name = "${var.project_tag}-bastion-${var.env}"
Env = "${var.env}"
ApplicationID = "${var.api_app_tag}"
ApplicationRole = "Bastion Host"
Project = "${var.project_tag}"
}
}
On the other hand, there are data sources which allow you to read data about given components without changing them. You want to get the AWS ID (ARN) of an ACM-issued certificate? You use a data source. The difference is that data sources are prefixed with data_ when referencing them in the configuration files.
data "aws_acm_certificate" "ssl_cert" {
domain = "*.example.com"
statuses = ["ISSUED"]
}
The above references an issued ACM SSL certificate that can be used together with AWS ALBs. Before you do that all though, you need to set up your environment.
Folder Structure
Terraform environments (and their states) are separated by directories. Terraform loads all *.tf files in a directory into one namespace, so order does not matter. I recommend the following directory structure:
/terraform/
|---> default_variables.tf (1)
/stage/ (2)
|---> terraform.tfvars (3)
|---> default_variables.tf (4)
|---> terraform.tf (5)
|---> env_variables.tf (6)
/prod/
/<env_name>/
-
default_variables.tf– define all the top-level variables and optionally their default values. They can be reused in each environment (nested directory) with symlinks. -
/stage/– a directory holding the configuration for a whole separate environment (here namedstage, but it can be anything). Any changes made inside this folder are totally independent from other environments (env—likeprod) which is something you want in order to avoid messing up the production env with changes made tostage! -
terraform.tfvars– define variable values..tfvarsfiles are similar to.envfiles in that they hold thekey=valpairs for defined variables. For example, this specifies the AWSprofile, AWSkey_nameand AWSkey_paththat I use. It can be ignored in Git. -
default_variables.tf– this is a symlink to the file (2), which allows us to share env-independent variables without repeating ourselves. -
terraform.tf– this is the main configuration of each env; it holds theterraform {}block which configures the back-end. I also configure providers here. -
env_variables.tf– this file holds env-specific variables. I tag all resources withEnv=<env_name>in AWS, so this file usually defines only one variable:env.
Of course, this is not the only way of structuring your environment. This is just something that worked well for me by enabling clear separation of concerns.
Back-end Configuration
I already mentioned Terraform state. This is an essential part of Terraform workflow. You might wonder if state is actually required. Couldn’t Terraform just query the AWS API all the time to get the actual state of the infrastructure? Well, if you think about it, Terraform needs to maintain a mapping between what it manages in declarative configuration files and what those files actually correspond to (in the cloud provider’s environment). Note that, while writing Terraform configuration files, you don’t care about the IDs of, e.g., individual EC2 instances or the ARNs that will be created for security groups that you publish. Internally, however, Terraform needs to know that a given resource block represents a concrete resource with an ID/ARN. This is required to detect changes. Moreover, state is used to track dependencies between resources (also something you don’t have to usually think about!). They are used to construct a graph that can be (usually) parallelized and executed. As always, I recommend that you read the excellent documentation on Terraform state and its purpose.
Since state is the single source of truth for your architecture, you need to make sure you and your team are always working on its most up-to-date version and that you don’t create conflicts by unsynchronized access to the state. You don’t want to resolve merge conflicts on the state file, believe me.
By default, Terraform stores state in a file on disk, located in the current working directory (of each env) as a terraform.tfstate file. This is okay if you know you will be the only developer on the job or are just learning and experimenting with Terraform. Technically, you could make it work in a team because you can commit the state to a VCS repository. But then, you would need to make sure everyone is always working on the latest version of the state and that no one does changes at the same time! This is generally a major headache and I strongly advise against it. Besides, if someone joins your single-dev operation, you still would have to configure an alternative place for the state.
Fortunately, this is a problem with a good solutions build into Terraform: the so-called Remote State. For remote state to work, you need to configure the back-end using one of the available back-end providers. The following back-end example will be based on AWS S3 and AWS DynamoDB (AWS NoSQL database). You could use only S3 but then you lose the mechanism of state locking and consistency checking (not recommended). If you previously used local state only, configuring a remote back-end will offer you an option to migrate your state the first time, so you don’t lose anything. You can read more about back-end configuration here.
Unfortunately, there is a chicken and egg problem: The S3 bucket and DynamoDB table have to be created manually. Terraform cannot create them automatically since there is no state yet! Well, there are some solutions like https://github.com/gruntwork-io/terragrunt that automate that using AWS CLI, but I don’t want to deviate from the main topic of this blog post.
The important things to know about S3 and DynamoDB backend configuration are:
- Enable versioning on the S3 bucket to be safe from human error and Murphy’s Law.
- DynamoDB table has a rate limit on reads and writes (called capacity). If you make a lot of changes to the remote state, make sure to either enable DynamoDB AutoScaling for that table or configure high-enough R/W limits. Otherwise, Terraform will get HTTP 400 errors from the AWS API when executing a lot of calls.
To sum it all up, the following back-end configuration can be placed in terraform.tf to configure remote state on S3 and DynamoDB.
terraform {
# Sometimes you may want to require a certain version of Terraform
required_version = ">= 0.11.7"
# Stores remote state, required for distributed teams
# Bucket & dynamoDB table have to be created manually if they do not exist
# See: https://github.com/hashicorp/terraform/issues/12780
backend "s3" {
bucket = "my-company-terraform-state"
key = "app-name/stage"
region = "eu-west-1"
# 5/5 R/W Capacity might not be enough for heavy, burst work (resulting in 400s). Consider enabling Auto Scaling on the table.
# See: http://docs.aws.amazon.com/amazondynamodb/latest/developerguide/HowItWorks.ProvisionedThroughput.html
dynamodb_table = "terraform-state-lock-table"
}
}
This is a lot to take in at once, but remember, you do this once for each env and then can forget about it. If you need even more control over state locking, there’s HashiCorp Terraform Enterprise, but I won’t cover it here.
Providers
In order for this back-end do be accessible and to be able to communicate with our cloud provider at all, we need to configure the so-called provider. The following block can be placed in terraform.tf file (for each env):
provider "aws" {
profile = "${var.profile}"
region = "${var.region}"
version = "~> 1.23.0"
}
Variables for profile and region are stored in the terraform.tfvars file, which may be ignored. The profile variable refers to a named profile holding security credentials for AWS cloud using the standard credentials file. Note that I’m also setting some version constraints. You don’t want Terraform to upgrade your provider plugins without your knowledge on every back-end initialization. Especially given there is a version 2.x of the AWS provider that requires careful upgrade.
Back-end Initialization
Each back-end configuration requires an initialization step at the beginning and every time there is a change made to it. Initialization also configures Terraform modules (more on those later), so when you add those, you need to re-run the init step as well. This operation is safe to run multiple times. Note that, during initialization of the back-end, not all variables can be read by Terraform to configure state, nor should they be for security reasons (e.g., secret keys). To overcome this and, in our case, use a different AWS profile than the default, you can use the -backend-config option with accepts k=v pairs of variables. This is called partial configuration.
terraform init -backend-config=profile=<aws_profile_name>
Terraform files share a scope that is constrained to a given directory. This means that a sub-folder is not directly connected to the parent-directory code. It is, however, defining a module that allows for code reuse, complexity management, and sharing.
The Workflow
The general workflow when working with Terraform code is as follows:
- Write configuration for your infrastructure.
- See what actual changes it will make (
terraform plan). - Optionally, execute the exact changes you saw in step 2 (
terraform apply). - GOTO 1
Terraform Plan
The Terraform plan command will present you with a list of changes that will be done to your infrastructure upon issuing the apply command. It’s safe to issue plan multiple times, as it by itself does not change anything.
How to Read a Plan
Objects in Terraform (resources and data sources) are easily identifiable by their fully qualified names.
- In the case of resources, the ID might look like:
<resource_type>.<resource_name>—e.g.,aws_ecs_service.this. - In the case of resources inside modules, we have an additional module name:
module.<module_name>.<resource_type>.<resource_name>—e.g.,module.my_service_ecs_service_task.aws_ecs_service.this. - Data sources (inside and outside of a module):
(module.<module_name>).data.<resource_type>.<resource_name>—e.g.,module.my_service_ecs_service_task.data.aws_ecs_task_definition.this.
Resource type is specific to a given provider and usually includes its name (aws_…). The whole list of available resources for AWS can be found in the docs.
There are five actions that a plan will show for given resources:
-
[+]Add – A new resource will be created. -
[-]Destroy – A resource will be completely destroyed. -
[~]Modify in-place – A resource will be modified and one or more parameters will be changed. This is generally safe. Terraform will show you which parameters will be modified and how (if possible). -
[- / +]– The resource will be removed and then recreated with new parameters. This happens if a change was made to a parameter that cannot be changed in-place. Terraform will show you which changes force a recreation of a resource with the following comment in red:(forces new resource). This is potentially dangerous, since there is a period in which the resource will not exist at all. It can also break other, connected dependencies. I’d recommend working around such changes unless you know what the consequences will be or do not care about a downtime. -
[<=]– A datasource will be read. This is a read-only operation.
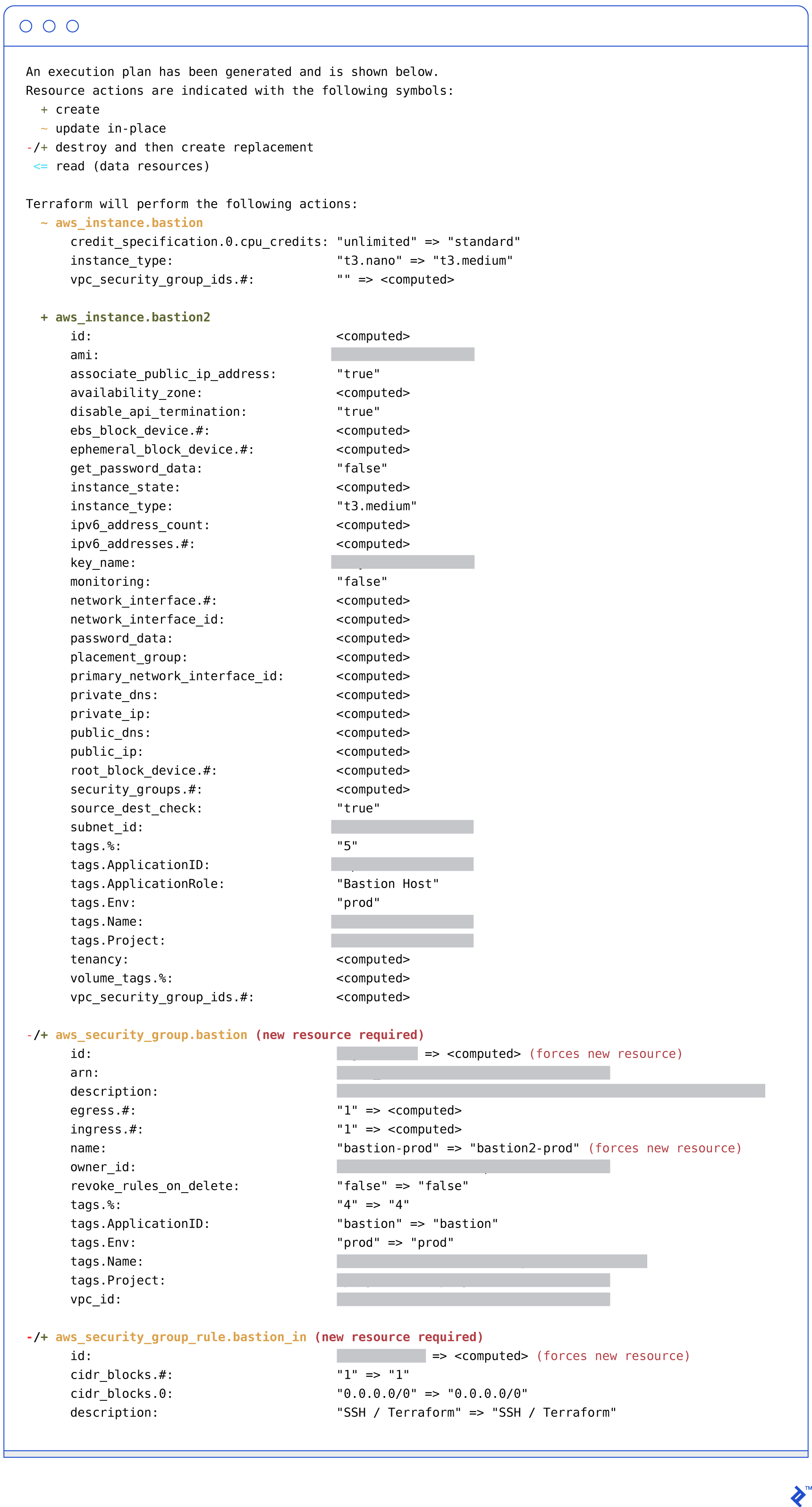
Above is an example plan. The changes I made were:
- Changed the
instance_typeof first bastion instance - Added a second bastion instance
- Changed the name of a security group
Note that the last change is a security group rule that automatically detected a change in parent group’s name. In my opinion, the whole plan is very readable. Some parameter values show as <computed>—it doesn’t mean they will be changed, but rather that they cannot be retrieved and presented at this stage (like the SG name that has not yet been created). Remember that only changed resources will be shown during the plan command. Anything that is omitted won’t be touched.
Usually, Terraform commands accept additional parameters. The most important parameter to the plan command is the -out option, which will save your plan on disk. This saved plan can be then executed (exactly as saved) by the apply command. This is very important, since otherwise there could be a change, made by, e.g., colleagues in between your issuing of a plan and the issuing of apply. Example:
- Issue
planand verify that it looks good. - Someone changes the state, unbeknownst to you.
- Issue
applyand—oops, it did something other than what was planned!
Thankfully, this workflow has been improved in Terraform v0.11.0. Since this version, the apply command automatically presents you with a plan that you have to then approve (by explicitly typing yes). The advantage is that, if you apply this plan, it will be executed exactly as presented.
Another useful option is -destroy, which will show you the plan that will result in destroying all resources that Terraform manages. You can also target specific resources for destruction with the -target option.
Terraform Apply
When we apply a given plan, Terraform goes out and puts a lock on our state to ensure exclusivity. It then proceeds to change the resources and, in the end, pushes an updated state. One thing to note is that some resources take longer to finish than others. For example, the creation of an AWS RDS instance might take more than 12 minutes, and Terraform will wait for this to finish. Obviously, Terraform is smart enough not to block every other operation by this. it creates a directed graph of requested changes and, if there are no interdependencies, uses parallelism to speed up the execution.
Importing resources
Often, Terraform and other “configuration as code” solutions are introduced gradually, into an already existing environment. The transition is really easy. Basically, anything not defined inside Terraform is left unmanaged and unchanged. Terraform is only concerned with what it manages. Of course, it’s possible that this will introduce issues—for example, if Terraform relies on some endpoint that exists outside of its configuration and it then is manually destroyed. Terraform doesn’t know about this, and thus cannot recreate this resource during state changes, which will result in errors from the API during plan execution. This is not something I’d worry about; the benefits of introducing Terraform far outweigh the cons.
In order to make the introduction process a little easier, Terraform includes the import command. It’s used to introduce already-existing external resources into Terraform state and allow it to manage those resources. Unfortunately, Terraform is not able to auto-generate configurations for those imported modules, at least at the time of writing. There are plans for this functionality, but for now, you need to first write the resource definition in Terraform and then import this resource in to tell Terraform to start managing it. Once imported into the state (and during the planning of the execution), you will see all the differences between what you wrote in the .tf files and what actually exists in the cloud. This way, you can further tweak the configuration. Ideally, no changes should show up, which would mean that the Terraform configuration reflects what is already on the cloud 1:1.
Modules
Modules are an essential part of the Terraform configuration, and I recommend that you embrace them and use them frequently. They provide you with a way to reuse certain components. An example would be the AWS ECS cluster, which is used to run Docker containers. For such a cluster to work, you need many separate resources to be configured: the cluster itself, the launch configuration that would manage separate EC2 instances, container repositories for images, the autoscaling group and policy, and so on. You usually need to have separate clusters for separate environments and/or applications.
One way to overcome this would be to copy and paste the configuration, but this is obviously a shortsighted solution. You would make errors doing the simplest updates.
Modules allow you to encapsulate all those separate resources under one configuration block (called a module). Modules define inputs and outputs which are the interfaces by which it communicates with “the outside world” (or the calling code). Moreover, modules can be nested inside other modules, allowing you to quickly spin up whole separate environments.
Local and Remote Modules
Similarly to state, you can have local modules or remote modules. Local modules are stored alongside your Terraform configuration (in a separate directory, outside of each environment but in the same repository). This is OK if you have a simple architecture and are not sharing those modules.
This, however, has limitations. It’s hard to version those modules and share them. Versioning is important because you might want to use v1.0.0 of your ECS module on production but would like to experiment with v1.1.0 on a staging environment. If the module was stored alongside your code, every change to the module code would be reflected in every env (once apply is run) which usually is undesirable.
One handy approach to versioning modules is to put them all in a separate repository, e.g., your-company/terraform-modules. Then, when referencing those modules inside your Terraform configuration, you can use a VCS link as a source:
module "my-module" {
source = "git@github.com:your-company/terraform-modules.git//modules/my-module?ref=v1.1.0"
...
}
Here I’m referencing a v1.1.0 of my-module (specific path) which I can test independently from other versions of the same module in different environments.
Other than that, there is the issue of discoverability and shareability of modules. You should strive to write well-documented and reusable modules. Usually, you will have different Terraform configurations for different apps and might want to share the same module among them. Without extracting them to a separate repo, this would be very hard.
Using modules
Modules can be easily referenced in Terraform environments by defining a special module block. Here is an example of such a block for a hypothetical ECS module:
module "my_service_ecs_cluster" {
source = "../modules/ecs_cluster"
cluster_name = "my-ecs-service-${var.env}"
repository_names = [
"my-ecs-service-${var.env}/api",
"my-ecs-service-${var.env}/nginx",
"my-ecs-service-${var.env}/docs",
]
service_name = "my-ecs-service-${var.env}"
ecs_instance_type = "t2.nano"
min_size = "1"
max_size = "1"
use_autoscaling = false
alb_target_group_arn = "${module.my_alb.target_group_arn}"
subnets = "${local.my_private_subnets}"
security_groups = "${aws_security_group.my_ecs.id}"
key_name = "${var.key_name}"
env_tag = "${var.env}"
project_tag = "${var.project_tag}"
application_tag = "${var.api_app_tag}"
asg_tag = "${var.api_app_tag}-asg"
}
All the options that are passed (except from some global ones like source) were defined inside this module’s configuration as inputs (variables).
Modules Registry
Recently HashiCorp launched an official Terraform module registry. This is great news since you can now draw from the knowledge of the community that has already developed battle-tested modules. Moreover, some of them have the “HashiCorp Verified Module” badge, which means they are vetted and actively maintained and gives you extra confidence.
Previously, you either had to write your own modules from scratch (and learn from your mistakes) or use modules published on GitHub and other places, without any guarantees as to their behavior (apart from reading the code!)
Sharing Data Between Environments
Ideally, environments should be totally separate, even by using different AWS accounts. In reality, there are cases when one Terraform environment might use some information in another environment. This is especially true if you are gradually converting your architecture to use Terraform. One example might be that you have a global env that provides certain resources to other envs.
Let’s say env global shares data with stage. For this to work, you can define outputs at the main level of the environment like so:
output "vpc_id" {
value = "${module.network.vpc_id}"
}
Then, in the stage environment, you define a datasource that points to the remote state of global:
data "terraform_remote_state" "global" {
backend = "s3"
config {
bucket = "my-app-terraform-state"
key = "terraform/global"
region = "${var.region}"
dynamodb_table = "terraform-state-lock-table"
profile = "${var.profile}"
}
}
Now, you can use this datasource as any other and access all the values that were defined in global’s outputs:
vpc_id = "${data.terraform_remote_state.global.vpc_id}"
Words of Caution
Terraform has a lot of pros. I use it daily in production environments and consider it stable enough for such work. Having said that, Terraform is still under active development. Thus, you will stumble on bugs and quirks.
Where to Report Issues and Monitor Changes
First of all, remember: Terraform has a separate core repo and repositories for each provider (e.g., AWS). If you encounter issues, make sure to check both the core repo and the separate provider repositories for issues and/or opened pull requests with fixes. GitHub is really the best place to search for bugs and fixes as it is very active and welcoming.
This also means that provider plugins are versioned separately, so make sure you follow their changelogs as well as the core one. Most of the bugs I have encountered were resolved by upgrading the AWS provider which already had a fix.
Can’t Cheat Your Way out of Cloud Knowledge
You cannot use Terraform to configure and manage infrastructure if you have no knowledge of how a given provider works. I would say this is a misconception and not a downside, since Terraform has been designed to augment and improve the workflow of configuration management and not to be some magic dust that you randomly sprinkle around and—poof! Environments grow! You still need a solid knowledge of a security model of each cloud, how to write, e.g., AWS policies, what resources are available, and how they interact.
Prefer Separate Resources That Are Explicitly linked
There are certain resources—for example, the AWS security group or AWS route table—that allow you to configure the security rules and routes respectively, directly inside their own block. This is tempting, as it looks like less work but in fact will cause you trouble. The problems start when you are changing those rules on subsequent passes. The whole resource will be marked as being changed even if only one route/security rule is being introduced. It also gives implicit ordering to those rules and makes it harder to follow the changes. Thankfully, mixing those both approaches is not allowed now (see the note).
Best-practice example, with explicitly linked resources:
resource "aws_security_group" "my_sg" {
name = "${var.app_tag}-my-sg"
...
}
resource "aws_security_group_rule" "rule_one" {
security_group_id = "${aws_security_group.my_sg.id}"
...
}
resource "aws_security_group_rule" "rule_two" {
security_group_id = "${aws_security_group.my_sg.id}"
...
}
Terraform plan Doesn’t Always Detect Issues and Conflicts
I already mentioned this in the case where you were managing resources with Terraform that were relying on other, unmanaged infrastructure. But there are more trivial examples—for example, you will get an error if your EC2 instance has Termination Protection enabled, even though plan would show you it’s OK to destroy it. You can argue that this is what Termination Protection has been designed for, and I agree, but there are more examples of things you can do in theory/on plan but when executed will deadlock or error out. For example, you cannot remove a network interface if something is using it—you get a deadlock without an option to gracefully recover.
Syntax Quirks
There are also quirks related to how HCLv1 (the syntax language Terraform uses) has been designed. It has a couple of frustrating quirks. There is work underway to provide an improved version of the parser for HCLv2. The best way to read on the current limitations and the plan to overcome them is this fantastic blog series. In the meantime, there are workarounds for most of those issues. They are not pretty and they will fail once v0.12 comes out, but hey, it is what it is.
When State Update Fails
It sometimes happens that Terraform is not able to correctly push an updated state. This is usually due to underlying network issues. The solution is to retry the state update instead of running apply again, which will fork the state.
Another issue might happen when state lock (the synchronization primitive that prevents multiple users to update the same state) fails to be taken down by Terraform. This involves running terraform force-unlock with the lock ID to take it down manually.
Thankfully, in case of such problems, Terraform provides you with a good description and steps you need to make to fix it.
Not Everything Is Fun to Manage Through Terraform
There are certain cases where Terraform is not my tool of choice. For example, configuring AWS CodePipeline and CodeBuild projects (AWS equivalent of CI/CD pipeline) is cumbersome when done through Terraform. You need to define each step through very verbose configuration blocks and things like “Login via GitHub” are a lot more complicated than using the UI. Of course, it’s still possible if you prefer to have it codified. Well, I guess it’s a good candidate for a well-written module!
Same thing goes for managing AWS API Gateway endpoints. In this case, using a dedicated serverless framework would be a better option.
When configuring AWS resources with Terraform, you will find yourself writing a lot of policies. Policies that would otherwise often be auto-generated for you (when using the UI). For those, I’d recommend the AWS Visual Editor and then copying the resulting policy JSON into Terraform.
Conclusion
Using Terraform has been fun and I’ll continue doing so. Initial steps can be a bumpy ride, but there are more and more resources that help to ease you in.
I’d definitely recommend taking Terraform for a spin and simply playing with it. Remember, though—be safe and test it out on a non-essential account. If you are eligible for AWS Free Tier, use it as a 12-month free trial. Just be aware it has limitations as to what you can provision. Otherwise, just make sure you spin the cheapest resources, like t3.nano instances.
I highly recommend extensions for Terraform support in various code editors. For Visual Studio Code, there is one with syntax highlighting, formatting, validation and linting support.
It’s always valuable to learn new things and evaluate new tools. I found that Terraform helped me immensely in managing my infrastructure. I think working with Terraform will only get easier and more fun, especially once v0.12.0 ships with a major upgrade to the HCL syntax and solve most of the quirks. The traction and community around Terraform are active and vibrant. You can find a lot of great resources on things I didn’t manage to cover in a single blogs post, e.g., a detailed guide on how to write modules.
Understanding the basics
What is Terraform used for?
Terraform is used to manage infrastructure on various cloud platforms. It does so based on configuration files that control the creation, changing, and destruction of all resources they cover. It frees you from having to do this manually, which would be error-prone and often irreproducible
Why should I use Terraform?
You should use Terraform because, with it, you can automate the creation of complex environments on multiple cloud platforms. Since the configuration is written as code, it can be reviewed, collaborated on, and versioned in VCS. It also provides you with reproducible deployments that are less error-prone.
What is AWS?
AWS stands for Amazon Web Services. It’s one of the leading cloud platforms that allows one to, e.g., provision virtual machines, databases, and store and operate on vast amounts of data. All the resources are available on-demand and are scalable without you having to worry about physical infrastructure.
Do I need to know AWS or other platform to use Terraform?
Yes, you need at least a basic understanding of what the given platform offers and how its components interact with each other to create functional setups.
Can I preview changes before executing them with Terraform?
Yes, use the “plan” command for that. It’s a dry-run mode that sums up all the changes that would be made should you apply them. Remember to save this plan so that later it will be applied exactly as you saw it.
Radosław Szalski
Poznań, Poland
Member since August 29, 2017
About the author
Radosław is a Python enthusiast and full-stack developer with over half a decade of professional experience engineering web apps.
PREVIOUSLY AT