Scaling Scala: How to Dockerize Using Kubernetes
Are you a Scala developer hoping to scale your application in the cloud? If so, meet Kubernetes, a cluster manager for Docker applications. Developed by Google, it’s the latest in new open source tools making major waves.
In this article, Toptal Freelance Software Engineer Michele Sciabarra guides us through a step-by-step tutorial on how to take a generic Scala application and implement Kubernetes and Docker to launch multiple instances of the application.

Are you a Scala developer hoping to scale your application in the cloud? If so, meet Kubernetes, a cluster manager for Docker applications. Developed by Google, it’s the latest in new open source tools making major waves.
In this article, Toptal Freelance Software Engineer Michele Sciabarra guides us through a step-by-step tutorial on how to take a generic Scala application and implement Kubernetes and Docker to launch multiple instances of the application.

Michele is a system architect with over 20 years of experience. He is a polyglote developer but his specialty is Scala and DevOps.
PREVIOUSLY AT

Kubernetes is the new kid on the block, promising to help deploy applications into the cloud and scale them more quickly. Today, when developing for a microservices architecture, it’s pretty standard to choose Scala for creating API servers.
If there is a Scala application in your plans and you want to scale it into a cloud, then you are at the right place. In this article I am going to show step-by-step how to take a generic Scala application and implement Kubernetes with Docker to launch multiple instances of the application. The final result will be a single application deployed as multiple instances, and load balanced by Kubernetes.
All of this will be implemented by simply importing the Kubernetes source kit in your Scala application. Please note, the kit hides a lot of complicated details related to installation and configuration, but it is small enough to be readable and easy to understand if you want to analyze what it does. For simplicity, we will deploy everything on your local machine. However, the same configuration is suitable for a real-world cloud deployment of Kubernetes.
What is Kubernetes?
Before going into the gory details of the implementation, let’s discuss what Kubernetes is and why it’s important.
You may have already heard of Docker. In a sense, it is a lightweight virtual machine.
For these reasons, it is already one of the more widely used tools for deploying applications in clouds. A Docker image is pretty easy and fast to build and duplicable, much easier than a traditional virtual machine like VMWare, VirtualBox, or XEN.
Kubernetes complements Docker, offering a complete environment for managing dockerized applications. By using Kubernetes, you can easily deploy, configure, orchestrate, manage, and monitor hundreds or even thousands of Docker applications.
Kubernetes is an open source tool developed by Google and has been adopted by many other vendors. Kubernetes is available natively on the Google cloud platform, but other vendors have adopted it for their OpenShift cloud services too. It can be found on Amazon AWS, Microsoft Azure, RedHat OpenShift, and even more cloud technologies. We can say it is well positioned to become a standard for deploying cloud applications.
Prerequisites
Now that we covered the basics, let’s check if you have all the prerequisite software installed. First of all, you need Docker. If you are using either Windows or Mac, you need the Docker Toolbox. If you are using Linux, you need to install the particular package provided by your distribution or simply follow the official directions.
We are going to code in Scala, which is a JVM language. You need, of course, the Java Development Kit and the scala SBT tool installed and available in the global path. If you are already a Scala programmer, chances are you have those tools already installed.
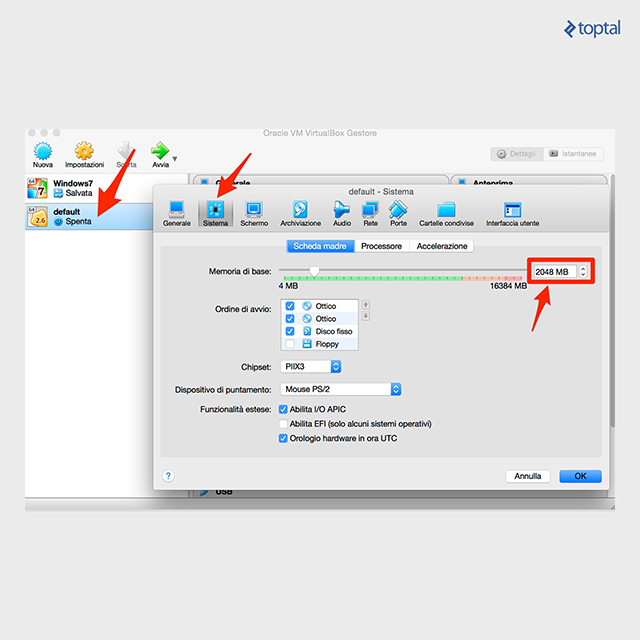
If you are using Windows or Mac, Docker will by default create a virtual machine named default with only 1GB of memory, which can be too small for running Kubernetes. In my experience, I had issues with the default settings. I recommend that you open the VirtualBox GUI, select your virtual machine default, and change the memory to at least to 2048MB.
The Application to Clusterize
The instructions in this tutorial can apply to any Scala application or project. For this article to have some “meat” to work on, I chose an example used very often to demonstrate a simple REST microservice in Scala, called Akka HTTP. I recommend you try to apply source kit to the suggested example before attempting to use it on your application. I have tested the kit against the demo application, but I cannot guarantee that there will be no conflicts with your code.
So first, we start by cloning the demo application:
git clone https://github.com/theiterators/akka-http-microservice
Next, test if everything works correctly:
cd akka-http-microservice
sbt run
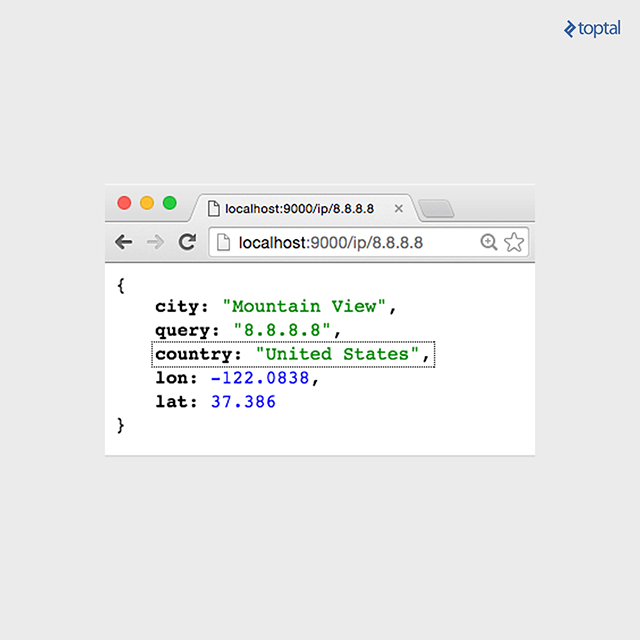
Then, access to http://localhost:9000/ip/8.8.8.8, and you should see something like in the following image:
Adding the Source Kit
Now, we can add the source kit with some Git magic:
git remote add ScalaGoodies https://github.com/sciabarra/ScalaGoodies
git fetch --all
git merge ScalaGoodies/kubernetes
With that, you have the demo including the source kit, and you are ready to try. Or you can even copy and paste the code from there into your application.
Once you have merged or copied the files in your projects, you are ready to start.
Starting Kubernetes
Once you have downloaded the kit, we need to download the necessary kubectl binary, by running:
bin/install.sh
This installer is smart enough (hopefully) to download the correct kubectl binary for OSX, Linux, or Windows, depending on your system. Note, the installer worked on the systems I own. Please do report any issues, so that I can fix the kit.
Once you have installed the kubectl binary, you can start the whole Kubernetes in your local Docker. Just run:
bin/start-local-kube.sh
The first time it is run, this command will download the images of the whole Kubernetes stack, and a local registry needed to store your images. It can take some time, so please be patient. Also note, it needs direct accesses to the internet. If you are behind a proxy, it will be a problem as the kit does not support proxies. To solve it, you have to configure the tools like Docker, curl, and so on to use the proxy. It is complicated enough that I recommend getting a temporary unrestricted access.
Assuming you were able to download everything successfully, to check if Kubernetes is running fine, you can type the following command:
bin/kubectl get nodes
The expected answer is:
NAME STATUS AGE
127.0.0.1 Ready 2m
Note that age may vary, of course. Also, since starting Kubernetes can take some time, you may have to invoke the command a couple of times before you see the answer. If you do not get errors here, congratulations, you have Kubernetes up and running on your local machine.
Dockerizing Your Scala App
Now that you have Kubernetes up and running, you can deploy your application in it. In the old days, before Docker, you had to deploy an entire server for running your application. With Kubernetes, all you need to do to deploy your application is:
- Create a Docker image.
- Push it in a registry from where it can be launched.
- Launch the instance with Kubernetes, that will take the image from the registry.
Luckily, it is way less complicated that it looks, especially if you are using the SBT build tool like many do.
In the kit, I included two files containing all the necessary definitions to create an image able to run Scala applications, or at least what is needed to run the Akka HTTP demo. I cannot guarantee that it will work with any other Scala applications, but it is a good starting point, and should work for many different configurations. The files to look for building the Docker image are:
docker.sbt
project/docker.sbt
Let’s have a look at what’s in them. The file project/docker.sbt contains the command to import the sbt-docker plugin:
addSbtPlugin("se.marcuslonnberg" % "sbt-docker" % "1.4.0")
This plugin manages the building of the Docker image with SBT for you. The Docker definition is in the docker.sbt file and looks like this:
imageNames in docker := Seq(ImageName("localhost:5000/akkahttp:latest"))
dockerfile in docker := {
val jarFile: File = sbt.Keys.`package`.in(Compile, packageBin).value
val classpath = (managedClasspath in Compile).value
val mainclass = mainClass.in(Compile, packageBin).value.getOrElse(sys.error("Expected exactly one main class"))
val jarTarget = s"/app/${jarFile.getName}"
val classpathString = classpath.files.map("/app/" + _.getName)
.mkString(":") + ":" + jarTarget
new Dockerfile {
from("anapsix/alpine-java:8")
add(classpath.files, "/app/")
add(jarFile, jarTarget)
entryPoint("java", "-cp", classpathString, mainclass)
}
}
To fully understand the meaning of this file, you need to know Docker well enough to understand this definition file. However, we are not going into the details of the Docker definition file, because you do not need to understand it thoroughly to build the image.
the SBT will take care of collecting all the files for you.
Note the classpath is automatically generated by the following command:
val classpath = (managedClasspath in Compile).value
In general, it is pretty complicated to gather all the JAR files to run an application. Using SBT, the Docker file will be generated with add(classpath.files, "/app/"). This way, SBT collects all the JAR files for you and constructs a Dockerfile to run your application.
The other commands gather the missing pieces to create a Docker image. The image will be built using an existing image APT to run Java programs (anapsix/alpine-java:8, available on the internet in the Docker Hub). Other instructions are adding the other files to run your application. Finally, by specifying an entry point, we can run it. Note also that the name starts with localhost:5000 on purpose, because localhost:5000 is where I installed the registry in the start-kube-local.sh script.
Building the Docker Image with SBT
To build the Docker image, you can ignore all the details of the Dockerfile. You just need to type:
sbt dockerBuildAndPush
The sbt-docker plugin will then build a Docker image for you, downloading from the internet all the necessary pieces, and then it will push to a Docker registry that was started before, together with the Kubernetes application in localhost. So, all you need is to wait a little bit more to have your image cooked and ready.
Note, if you experience problems, the best thing to do is to reset everything to a known state by running the following commands:
bin/stop-kube-local.sh
bin/start-kube-local.sh
Those commands should stop all the containers and restart them correctly to get your registry ready to receive the image built and pushed by sbt.
Starting the Service in Kubernetes
Now that the application is packaged in a container and pushed in a registry, we are ready to use it. Kubernetes uses the command line and configuration files to manage the cluster. Since command lines can become very long, and also be able to replicate the steps, I am using the configurations files here. All the samples in the source kit are in the folder kube.
Our next step is to launch a single instance of the image. A running image is called, in the Kubernetes language, a pod. So let’s create a pod by invoking the following command:
bin/kubectl create -f kube/akkahttp-pod.yml
You can now inspect the situation with the command:
bin/kubectl get pods
You should see:
NAME READY STATUS RESTARTS AGE
akkahttp 1/1 Running 0 33s
k8s-etcd-127.0.0.1 1/1 Running 0 7d
k8s-master-127.0.0.1 4/4 Running 0 7d
k8s-proxy-127.0.0.1 1/1 Running 0 7d
Status actually can be different, for example, “ContainerCreating”, it can take a few seconds before it becomes “Running”. Also, you can get another status like “Error” if, for example, you forget to create the image before.
You can also check if your pod is running with the command:
bin/kubectl logs akkahttp
You should see an output ending with something like this:
[DEBUG] [05/30/2016 12:19:53.133] [default-akka.actor.default-dispatcher-5] [akka://default/system/IO-TCP/selectors/$a/0] Successfully bound to /0:0:0:0:0:0:0:0:9000
Now you have the service up and running inside the container. However, the service is not yet reachable. This behavior is part of the design of Kubernetes. Your pod is running, but you have to expose it explicitly. Otherwise, the service is meant to be internal.
Creating a Service
Creating a service and checking the result is a matter of executing:
bin/kubectl create -f kube/akkahttp-service.yaml
bin/kubectl get svc
You should see something like this:
NAME CLUSTER-IP EXTERNAL-IP PORT(S) AGE
akkahttp-service 10.0.0.54 9000/TCP 44s
kubernetes 10.0.0.1 <none> 443/TCP 3m
Note that the port can be different. Kubernetes allocated a port for the service and started it. If you are using Linux, you can directly open the browser and type http://10.0.0.54:9000/ip/8.8.8.8 to see the result. If you are using Windows or Mac with Docker Toolbox, the IP is local to the virtual machine that is running Docker, and unfortunately it is still unreachable.
I want to stress here that this is not a problem of Kubernetes, rather it is a limitation of the Docker Toolbox, which in turn depends on the constraints imposed by virtual machines like VirtualBox, which act like a computer within another computer. To overcome this limitation, we need to create a tunnel. To make things easier, I included another script which opens a tunnel on an arbitrary port to reach any service we deployed. You can type the following command:
bin/forward-kube-local.sh akkahttp-service 9000
Note that the tunnel will not run in the background, you have to keep the terminal window open as long as you need it and close when you do not need the tunnel anymore. While the tunnel is running, you can open: http://localhost:9000/ip/8.8.8.8 and finally see the application running in Kubernetes.
Final Touch: Scale
So far we have “simply” put our application in Kubernetes. While it is an exciting achievement, it does not add too much value to our deployment. We’re saved from the effort of uploading and installing on a server and configuring a proxy server for it.
Where Kubernetes shines is in scaling. You can deploy two, ten, or one hundred instances of our application by only changing the number of replicas in the configuration file. So let’s do it.
We are going to stop the single pod and start a deployment instead. So let’s execute the following commands:
bin/kubectl delete -f kube/akkahttp-pod.yml
bin/kubectl create -f kube/akkahttp-deploy.yaml
Next, check the status. Again, you may try a couple of times because the deployment can take some time to be performed:
NAME READY STATUS RESTARTS AGE
akkahttp-deployment-4229989632-mjp6u 1/1 Running 0 16s
akkahttp-deployment-4229989632-s822x 1/1 Running 0 16s
k8s-etcd-127.0.0.1 1/1 Running 0 6d
k8s-master-127.0.0.1 4/4 Running 0 6d
k8s-proxy-127.0.0.1 1/1 Running 0 6d
Now we have two pods, not one. This is because in the configuration file I provided, there is the value replica: 2, with two different names generated by the system. I am not going into the details of the configuration files, because the scope of the article is simply an introduction for Scala programmers to jump-start into Kubernetes.
Anyhow, there are now two pods active. What is interesting is that the service is the same as before. We configured the service to load balance between all the pods labeled akkahttp. This means we do not have to redeploy the service, but we can replace the single instance with a replicated one.
We can verify this by launching the proxy again (if you are on Windows and you have closed it):
bin/forward-kube-local.sh akkahttp-service 9000
Then, we can try to open two terminal windows and see the logs for each pod. For example, in the first type:
bin/kubectl logs -f akkahttp-deployment-4229989632-mjp6u
And in the second type:
bin/kubectl logs -f akkahttp-deployment-4229989632-s822x
Of course, edit the command line accordingly with the values you have in your system.
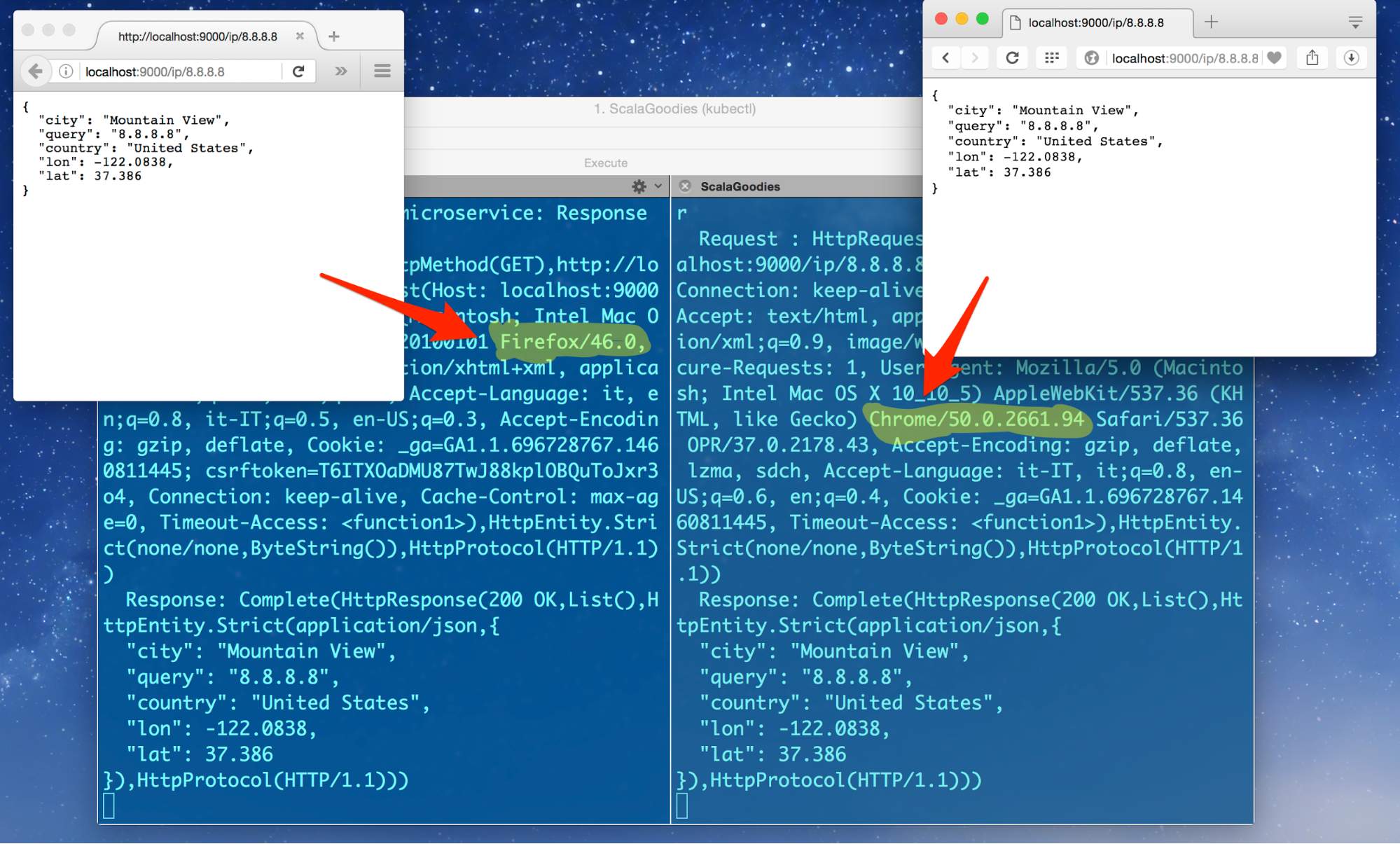
Now, try to access the service with two different browsers. You should expect to see the requests to be split between the multiple available servers, like in the following image:
Conclusion
Today we barely scratched the surface. Kubernetes offers a lot more possibilities, including automated scaling and restart, incremental deployments, and volumes. Furthermore, the application we used as an example is very simple, stateless with the various instances not needing to know each other. In the real world, distributed applications do need to know each other, and need to change configurations according to the availability of other servers. Indeed, Kubernetes offers a distributed keystore (etcd) to allow different applications to communicate with each other when new instances are deployed. However, this example is purposefully small enough and simplified to help you get going, focusing on the core functionalities. If you follow the tutorial, you should be able to get a working environment for your Scala application on your machine without being confused by a large number of details and getting lost in the complexity.
Michele Sciabarra
San Benedetto del Tronto, Province of Ascoli Piceno, Italy
Member since January 8, 2016
About the author
Michele is a system architect with over 20 years of experience. He is a polyglote developer but his specialty is Scala and DevOps.
PREVIOUSLY AT