


Unlocking the Power of AI with a Real-Time Data Strategy
CIO
FEBRUARY 14, 2023
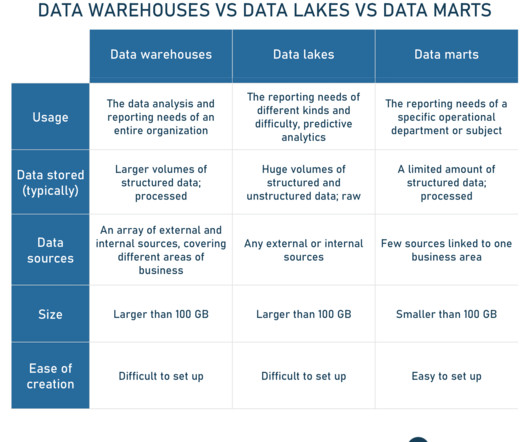
Titanium Intelligent Solutions, a global SaaS IoT organization, even saved one customer over 15% in energy costs across 50 distribution centers , thanks in large part to AI. Real-time decisioning can occur in minutes, seconds, milliseconds, or microseconds, depending on the use case. What kinds of decisions are necessary to be made in real-time?





















Let's personalize your content