Turbo-Charging Confluent Cloud To Be 10x Faster Than Apache Kafka®
Confluent
JANUARY 10, 2024
Confluent Cloud is now 10x faster than Apache Kafka. Read our latency benchmarking results, the innovations behind-the-scenes, and the lessons we learned.

 10x-apache-kafka
10x-apache-kafka 
Confluent
JANUARY 10, 2024
Confluent Cloud is now 10x faster than Apache Kafka. Read our latency benchmarking results, the innovations behind-the-scenes, and the lessons we learned.

Confluent
MAY 30, 2022
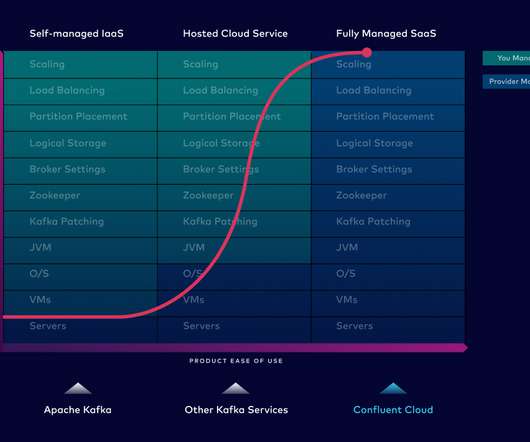
Kafka is horizontally scalable, but it's not enough. So we made Confluent Cloud 10x more elastic - 10x faster to scale up to GB/s or down to zero, easier to use, and cost-effective.
This site is protected by reCAPTCHA and the Google Privacy Policy and Terms of Service apply.
Confluent
MAY 30, 2022
What we’ve done to evolve from cloud Kafka to Confluent Cloud, a data streaming platform that’s 10X better than Kafka in elasticity, storage, resiliency, and more.

Confluent
SEPTEMBER 7, 2022
As mission-critical data infrastructure, Apache Kafka’s resiliency is non-negotiable. Learn how Confluent Cloud builds 10x higher resilience into its cloud-native services.

Cloudera
JULY 21, 2022
Cloudera has partnered with Rill Data, an expert in metrics at any scale, as Cloudera’s preferred ISV partner to provide technical expertise and support services for Apache Druid customers. We want Cloudera customers that rely on Apache Druid to know that their clusters are secure and supported by the Cloudera partner ecosystem.

Confluent
MAY 13, 2019
In the last year, we’ve experienced enormous growth on Confluent Cloud, our fully managed Apache Kafka ® service. As Confluent Cloud has grown, we’ve noticed two gaps that very clearly remain to be filled in managed Apache Kafka services. Five seconds to Kafka (or, never make another cluster again!).
Honeycomb
NOVEMBER 30, 2021
For the entirety of Honeycomb’s existence, we have used Apache Kafka to perform this buffering function in our observability pipeline. A brief overview of Kafka at Honeycomb. How does Kafka help us achieve these results? Adapting Kafka for our use case. Let’s dive in.

Expert insights. Personalized for you.














Let's personalize your content