


Machine Learning with Python, Jupyter, KSQL and TensorFlow
Confluent
FEBRUARY 6, 2019
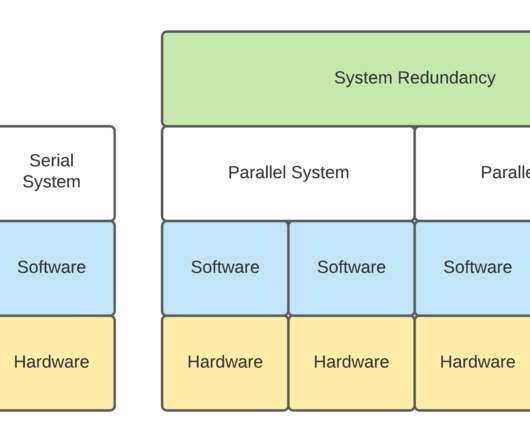
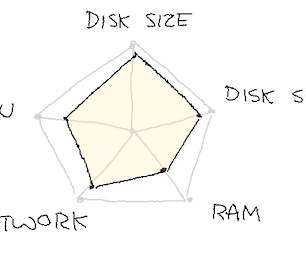
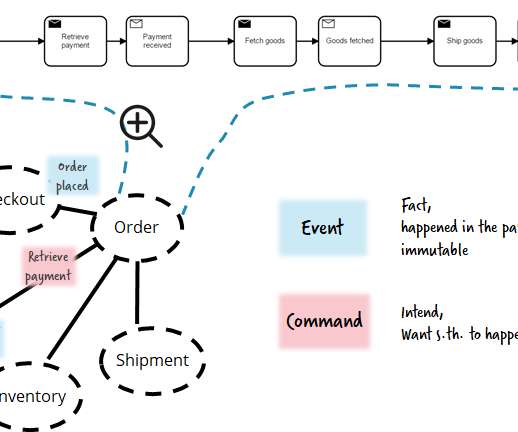
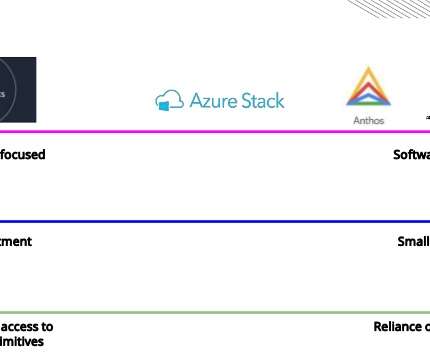
Building a scalable, reliable and performant machine learning (ML) infrastructure is not easy. It allows real-time data ingestion, processing, model deployment and monitoring in a reliable and scalable way. It takes much more effort than just building an analytic model with Python and your favorite machine learning framework.
























Let's personalize your content