
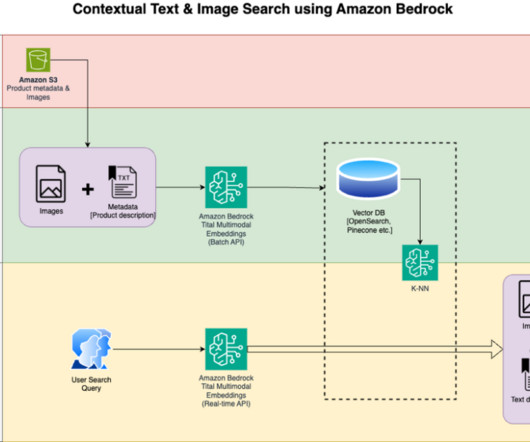
Build a contextual text and image search engine for product recommendations using Amazon Bedrock and Amazon OpenSearch Serverless
AWS Machine Learning - AI
APRIL 3, 2024
A multimodal embeddings model is designed to learn joint representations of different modalities like text, images, and audio. By training on large-scale datasets containing images and their corresponding captions, a multimodal embeddings model learns to embed images and texts into a shared latent space.





























Let's personalize your content