

Delivering Modern Enterprise Data Engineering with Cloudera Data Engineering on Azure
Cloudera
JULY 13, 2021
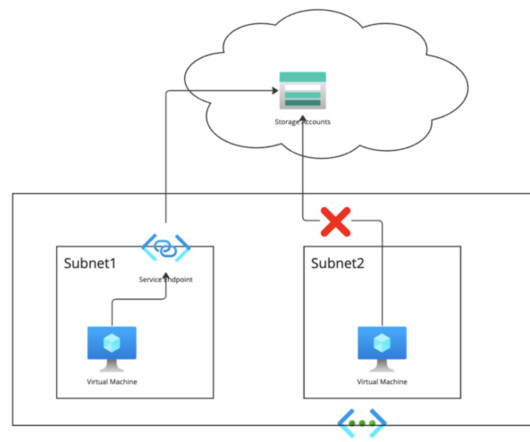
After the launch of CDP Data Engineering (CDE) on AWS a few months ago, we are thrilled to announce that CDE, the only cloud-native service purpose built for enterprise data engineers, is now available on Microsoft Azure. . Prerequisites for deploying CDP Data Engineering on Azure can be found here.














































Let's personalize your content