
AWS Disaster Recovery Strategies – PoC with Terraform
Xebia
DECEMBER 21, 2022
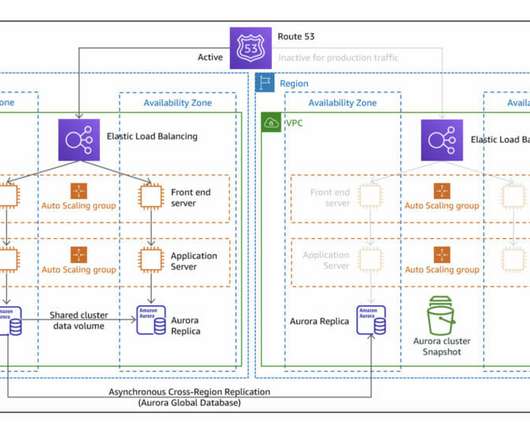
Regional failures are different from service disruptions in specific AZs , where a set of data centers physically close between them may suffer unexpected outages due to technical issues, human actions, or natural disasters. The code is publicly available on the links below, with how-to-use documentation.




















































Let's personalize your content