

Key Data Engineer responsibilities
Apiumhub
JANUARY 26, 2022
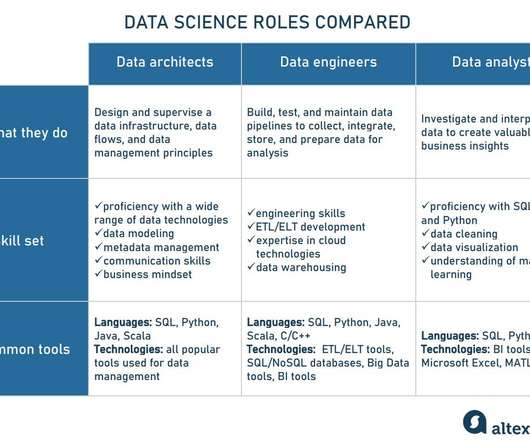
Data engineer roles have gained significant popularity in recent years. Number of studies show that the number of data engineering job listings has increased by 50% over the year. And data science provides us with methods to make use of this data. Who are data engineers?













































Let's personalize your content