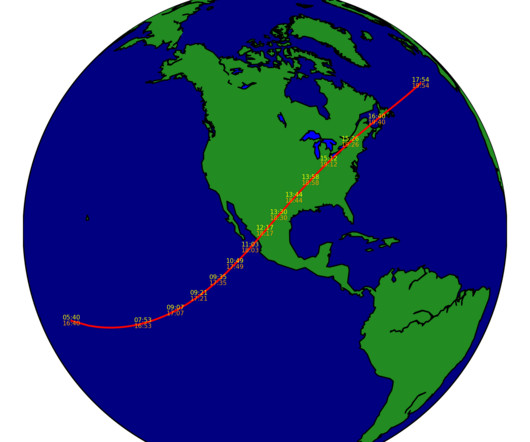
Predicting solar eclipses with Python
Erik Bernhardsson
APRIL 7, 2024
As I am en route to see my first total solar eclipse, I was curious how hard it would be to compute eclipses in Python. It turns out, ignoring some minor coordinate system head-banging, I was able to get something half-decent working in a couple of hours. I didn't want to go deep on celestial mechanics, so I decided to leverage Python's fantastic ecosystem for everything.





































Let's personalize your content