


From Data Swamp to Data Lake: Data Classification
Perficient
FEBRUARY 23, 2023
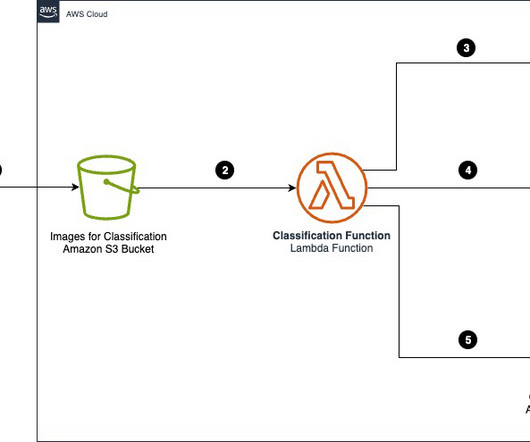
This is the third blog in a series that explains how organizations can prevent their Data Lake from becoming a Data Swamp, with insights and strategy from Perficient’s Senior Data Strategist and Solutions Architect, Dr. Chuck Brooks. In this blog, we discuss the fourth capability: Implementing classification-based security in the Data Lake.











































Let's personalize your content