

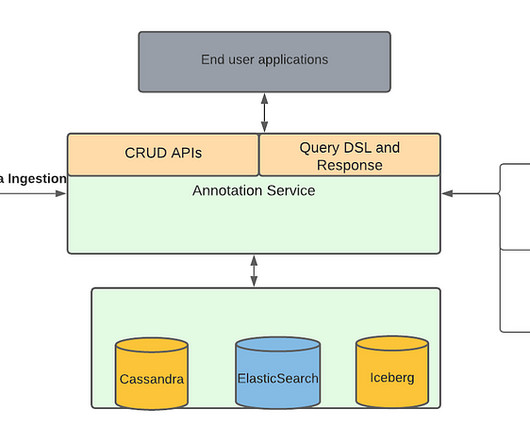
Data ingestion pipeline with Operation Management
Netflix Tech
MARCH 7, 2023
These media focused machine learning algorithms as well as other teams generate a lot of data from the media files, which we described in our previous blog , are stored as annotations in Marken. The solution which we present in this blog is not limited to annotations and can be used for any other domain which uses ES and Cassandra as well.







































Let's personalize your content