

Efficient continual pre-training LLMs for financial domains
AWS Machine Learning - AI
MARCH 28, 2024
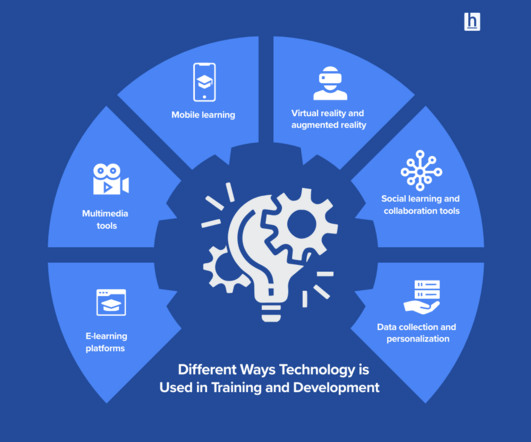
Large language models (LLMs) are generally trained on large publicly available datasets that are domain agnostic. For example, Meta’s Llama models are trained on datasets such as CommonCrawl , C4 , Wikipedia, and ArXiv. The resulting LLM outperforms LLMs trained on non-domain-specific datasets when tested on finance-specific tasks.















































Let's personalize your content